







DBMS_SCHEDULER:任务调度 :官方文档
Oracle 10g之前,可以使用dbms_job来管理定时任务,0g之后,Oracle引入dbms_scheduler来替代先前的dbms_job,
在功能方面,它比dbms_job提供了更强大的功能和更灵活的机制/管理。
使用dbms_scheduler创建一个定时任务有两种形式:
- 创建1个SCHEDULER来定义计划,1个PROGRAM来定义任务内容,再创建1个JOB,为这个JOB指定上面的SCHEDULER和PROGRAM。
- 直接创建JOB,在参数里面直接指定计划和任务内容。
要执行DBMS_SCHEDULER需要有CREATE JOB权限。
select * from dba_sys_privs where grantee='SCOTT'; --查询用户授予的权限
--授予权限
grant create job to SCOTT;
grant manage scheduler to SCOTT;
--查询用户所拥有的角色以及角色所包含的权限
select * from role_sys_privs where role in (select granted_role from dba_role_privs where grantee='SCOTT') order by role;示例1:
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.1.0
Connected as system@ORCL AS SYSDBA
SQL> select * from dba_sys_privs where grantee='SCOTT';
GRANTEE PRIVILEGE ADMIN_OPTION
------------------------------ ---------------------------------------- ------------
SCOTT UNLIMITED TABLESPACE NO
SCOTT DEBUG CONNECT SESSION NO
SQL>
SQL> select * from role_sys_privs where role in (
2 select granted_role from dba_role_privs where grantee='SCOTT'
3 ) order by role;
ROLE PRIVILEGE ADMIN_OPTION
------------------------------ ---------------------------------------- ------------
CONNECT CREATE SESSION NO
RESOURCE CREATE CLUSTER NO
RESOURCE CREATE INDEXTYPE NO
RESOURCE CREATE OPERATOR NO
RESOURCE CREATE PROCEDURE NO
RESOURCE CREATE SEQUENCE NO
RESOURCE CREATE TABLE NO
RESOURCE CREATE TRIGGER NO
RESOURCE CREATE TYPE NO
9 rows selected
SQL>
SQL> create table test_t1(id int, create_date date);
Table created
SQL> create or replace procedure test_p1
2 is
3 v_maxId test_t1.id%type := 1;
4 begin
5 select nvl(max(id), 0) into v_maxId from test_t1;
6 insert into test_t1 values(v_maxId + 1, sysdate);
7 commit;
8 end test_p1;
9 /
Procedure created
SQL> declare
2 v_count int := 0;
3 begin
4 select count(*) into v_count from user_scheduler_jobs where job_name='TEST_JOB1';
5 if v_count > 0 then
6 dbms_scheduler.drop_job('TEST_JOB1');
7 end if;
8 dbms_scheduler.create_job (
9 job_name => 'test_job1', --必选, 任务名称
10 job_type => 'STORED_PROCEDURE', --必须,任务类型【存储过程,匿名块等】
11 job_action => 'TEST_P1', --必选, 任务内容, 与job_type配合使用
12 start_date => sysdate, --可选, 首次执行时间, 为空时表示立即执行
13 repeat_interval => 'FREQ=MINUTELY;INTERVAL=1', --可选, 执行频率, 为空时表示只执行一次 【FREQ=MINUTELY; -- 表示间隔单位, 可选值有YEARLY, MONTHLY, WEEKLY, DAILY, HOURLY, MINUTELY, SECONDLY 】
14 --INTERVAL=1 表示间隔周期
15 enabled => true --可选, 是否启用任务
16 );
17 end;
18 /
PL/SQL procedure successfully completed
SQL> select job_name, job_type, enabled, state from user_scheduler_jobs; --查看已经创建的job
JOB_NAME JOB_TYPE ENABLED STATE
------------------------------ ---------------- ------- ---------------
BSLN_MAINTAIN_STATS_JOB TRUE SCHEDULED
DRA_REEVALUATE_OPEN_FAILURES STORED_PROCEDURE TRUE SCHEDULED
FGR$AUTOPURGE_JOB PLSQL_BLOCK FALSE DISABLED
FILE_WATCHER FALSE DISABLED
HM_CREATE_OFFLINE_DICTIONARY STORED_PROCEDURE FALSE DISABLED
ORA$AUTOTASK_CLEAN TRUE SCHEDULED
PURGE_LOG TRUE SCHEDULED
RSE$CLEAN_RECOVERABLE_SCRIPT PLSQL_BLOCK TRUE SCHEDULED
SM$CLEAN_AUTO_SPLIT_MERGE PLSQL_BLOCK TRUE SCHEDULED
TEST_JOB1 STORED_PROCEDURE TRUE SCHEDULED
XMLDB_NFS_CLEANUP_JOB STORED_PROCEDURE FALSE DISABLED
11 rows selected
SQL> select log_id, log_date, status from user_scheduler_job_run_details where job_name='TEST_JOB1'; --查看JOB运行日志
LOG_ID LOG_DATE STATUS
---------- -------------------------------------------------------------------------------- ------------------------------
6105 22-FEB-20 04.32.45.521000 PM +08:00 SUCCEEDED
SQL> 执行结果:
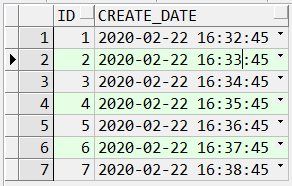
删除 job:
SQL> exec dbms_scheduler.drop_job('TEST_JOB1');
PL/SQL procedure successfully completedjob 参数说明(常用):
job_name: 每个job都必须有一个的名称
job_class: 作业(任务)类的名称
program_name:作业(任务)运行的程序的名称
schedule_name: 如果定义了计划,在这里指定计划的名称
job_type: 目前支持四种类型:
1:PL/SQL块: PLSQL_BLOCK,
2:存储过程: STORED_PROCEDURE
3:外部程序: EXECUTABLE (外部程序可以是一个shell脚本,也可以是操作系统级别的指令).
4:CHAIN -- 执行一个CHAIN
schedule_limit:在取消作业(任务)运行之前,计划作业(任务)与实际作业(任务)启动之间的最大延迟时间
job_action: 根据job_type的不同,job_action有不同的含义.
如果job_type指定的是存储过程,就需要指定存储过程的名字;
如果job_type指定的是PL/SQL块,就需要输入完整的PL/SQL代码;
如果job_type指定的外部程序,就需要输入script的名称或者操作系统的指令名
enabled: 指定job创建完毕是否自动激活 (见示例1)
comments: 对于job的简单说明
start_time:开始时间。
end_time:结束时间
repeat_interval:重复频率
PL/SQL表达式: 这也是dbms_job包中所使用的,例如SYSDATE+1, SYSDATE + 30/24*60;
日期表达式:
FREQ=MINUTELY; -- 表示间隔单位, 可选值有YEARLY(年), MONTHLY(月), WEEKLY(周), DAILY(天), HOURLY(时), MINUTELY(分), SECONDLY(秒)
INTERVAL=1 -- 表示间隔周期
repeat_interval => 'FREQ=MINUTELY;INTERVAL=1', :表示每分钟执行一次
repeat_interval => 'FREQ=HOURLY; INTERVAL=2' :每隔2小时运行一次
repeat_interval => 'FREQ=DAILY':每天运行一次
repeat_interval => 'FREQ=WEEKLY;BYDAY=MON,WED,FRI':每周的1,3,5运行job
repeat_interval => 'FREQ=YEARLY;BYMONTH=MAR,JUN,SEP,DEC; BYMONTHDAY=30':每年的3,6,9,12月的30号运行
| Name | Description |
|---|---|
| FREQ | 指定了递归的类型。必须指定它。可能的预定义频率值是年、月、周、日、小时、分钟和次。或者,指定作为用户定义频率使用的现有调度。 |
| INTERVAL | 它指定一个正整数,表示循环重复的频率。默认值是1,表示秒为秒,天为天,以此类推。最大值是99。 |
| BYMONTH | 这指定您希望在哪个月或哪个月执行作业。您可以使用数字,例如1表示一月,3表示三月,以及三个字母的缩写,例如2表示二月,7表示七月。 |
| BYWEEKNO | 它将一年中的星期指定为一个数字。接下来是ISO-8601,它将一周定义为周一开始,周日结束;一年的第一周作为第一周,主要是在公历年度内。第一周相当于以下两个变体:包含公历年第一个星期四的那一周;以及包含1月4日的那一周。ISO-8601周数是从1到52或53的整数;第一周的部分时间可能在上一个日历年;52周的部分时间可能在下一个日历年;如果一年有一个星期53,它的一部分必须在下一个日历年。例如,在1998年,ISO第一周开始于1997年12月29日星期一;ISO的最后一周(第53周)于1999年1月3日结束。1997年12月29日是ISO周1998-01,1999年1月1日是ISO周1998-53。星期只能用一年。无效规范的例子有“FREQ= annual;BYWEEKNO = 1;BYMONTH = 12”和“频率=年度;BYWEEKNO = 53; BYMONTH = 1”。 |
| BYYEARDAY | 这指定了一个日期列表,其中每个日期的格式是[YYYY]MMDD。可以使用SPAN修饰符生成一系列连续的日期,还可以使用OFFSET修饰符调整日期。一个简单的例子BYDATE条款:BYDATE = 0115, 0315, 0615, 0915, 1215, 20060115以下跨度示例相当于BYDATE = 0110, 0111, 0112, 0113, 0114,这是一个跨越5天从1/10开始:BYDATE = 0110 +跨度:5 d前面的加号跨越关键字表示跨度从提供的日期。负号表示在提供日期结束的跨度,“^”表示以提供日期为中心的n天或n周的跨度。如果n是偶数,则调整为下一个奇数。偏移量通过增加或减少n天或n周来调整提供的日期。BYDATE=0205-OFFSET:2W相当于BYDATE=0205-14D (OFFSET:关键字是可选的),也相当于BYDATE=0122。 |
| BYMONTHDAY | 这将每月的日期指定为一个数字。有效值为1到31。例如10,表示所选月份的第10天。可以使用负号(-)从最后一天开始倒数,例如BYMONTHDAY=-1表示该月的最后一天,BYMONTHDAY=-2表示该月的下一天。 |
| BYDAY | 它以星期一、星期二等形式指定从星期一到星期日的星期几。使用数字,您可以指定一年中的第26个星期五(如果使用年频率),或者每月的第4个星期四(使用月频率)。用这个负号,你可以说这个月的第二个星期五。例如,-1星期五是一个月的最后一个星期五。 |
| BYHOUR | 它指定作业运行的时间。有效值是0到23。例如,10表示上午10点。 |
| BYMINUTE | 这指定了作业运行的时间。有效值是0到59。例如,45表示选择的时间已经过了45分钟。 |
| BYSECOND | 这将指定作业要在其上运行的第二个作业。有效值是0到59。例如,30表示超过所选分钟的30秒。 |
| BYSETPOS | 这将按位置在整个日历表达式求值后的时间戳列表中选择一个或多个项。它对于诸如在一个月的最后一个工作日运行作业之类的需求非常有用。您可以对calendar表达式进行编码,将其计算为该月的每个工作日的列表,然后添加BYSETPOS子句来仅选择该列表的最后一项,而不是尝试使用其他BY子句来表达这一点。假设工作日是周一到周五,那么语法应该是:FREQ=MONTHLY;BYDAY =星期一,星期二,星期三,星期四,星期五,BYSETPOS=-1的有效值是1到9999。负数从列表的末尾选择一个项目(-1是最后一个项目,-2是最后一个项目,依此类推),正数从列表的开头选择一个项目。BYSETPOS子句总是最后求值。BYSETPOS只支持每月和每年的频率。每个频率周期对时间戳列表应用一次BYSETPOS子句。例如,当频率被定义为MONTHLY时,调度器将确定该月的所有有效时间戳、订单列表,然后应用BYSETPOS子句。然后调度器转到下一个月,重复这个过程。假设启动日期为2004年6月10日,则示例的计算结果为:6月30日、7月30日、8月31日、9月30日、10月29日,依此类推。 |
| INCLUDE | 这包括日历表达式中的一个或多个命名调度。也就是说,由每个包含的命名调度定义的时间戳集被添加到日历表达式的结果中。如果一个相同的时间戳是由一个包含的计划和日历表达式提供的,那么它只会被包含在结果时间戳集中一次。指定的调度必须使用CREATE_SCHEDULE过程定义。 |
| EXCLUDE | 这将一个或多个命名调度从日历表达式中排除。也就是说,从日历表达式的结果中删除每个被排除的已命名调度定义的时间戳集。指定的调度必须使用CREATE_SCHEDULE过程定义。 |
| INTERSECT | 它指定日历表达式结果与由一个或多个命名调度定义的时间戳集之间的交集。只有同时出现在日历表达式和指定时间表中的时间戳才包含在结果时间戳集中。例如,假设指定的schedule last_sat表示每个月的最后一个星期六,而对于2005年,每月最后一天也是星期六的月份只有4月和12月。也假设指定的日程表end_qtr显示了2005年每个季度的最后一天:3/31/2005,6/30/2005,9/30/2005,12/31/2005这些日历表达式导致了以下日期:3/31/2005,4/30/2005,6/30/2005,9/30/2005,12/31/2005 FREQ=MONTHLY;BYMONTHDAY = 1;在本例中,术语FREQ=MONTHLY;BYMONTHDAY=-1表示每个月的最后一天。 |
| PERIODS | 它标识形成用户定义频率的一个周期的周期数。它用于定义用户定义频率的调度的repeat_interval表达式中。当主调度中的repeat_interval表达式包含BYPERIOD子句时,它是强制性的。下面的例子定义了一个财政年度的季度: |
| BYPERIOD | 它从用户定义的频率中选择周期。例如,如果主调度指定一个用户定义的频率调度,该频率调度定义前面示例中显示的财政季度,那么主调度中的BYPERIOD=2,4子句将选择第二和第四财政季度。 |
示例2:
SQL> declare
2 L_start_date date;
3 l_next_date date;
4 l_return_date date;
5
6 begin
7 l_start_date := trunc(sysdate);
8 l_return_date := l_start_date;
9 for ctr in 1..10 loop
10 dbms_scheduler.evaluate_calendar_string('FREQ=DAILY; BYDAY=MON,TUE,WED,THU,FRI; BYHOUR=7,15',l_start_date, l_return_date, l_next_date);
11 dbms_output.put_line('Next Run on: ' ||to_char(l_next_date,'YYYY-MM-DD HH24:MI:SS'));
12 l_return_date := l_next_date;
13 end loop;
14 end;
15 /
Next Run on: 2020-02-24 07:00:00
Next Run on: 2020-02-24 15:00:00
Next Run on: 2020-02-25 07:00:00
Next Run on: 2020-02-25 15:00:00
Next Run on: 2020-02-26 07:00:00
Next Run on: 2020-02-26 15:00:00
Next Run on: 2020-02-27 07:00:00
Next Run on: 2020-02-27 15:00:00
Next Run on: 2020-02-28 07:00:00
Next Run on: 2020-02-28 15:00:00
PL/SQL procedure successfully completed
SQL> 'FREQ=DAILY; BYDAY=MON,TUE,WED,THU,FRI; BYHOUR=7,15' : 按天执行,星期一到星期五 ,7点和15点。
job 结合 program
1:创建 program
什么是程序? 我的理解就是准备计划需要的元数据(metadata),它包括以下部分: 程序名;程 序中用到的参数: 例如程序的类型,以及具体操作的描述。
program-1:
BEGIN
dbms_scheduler.create_program(
program_name=>'program_wty_test_scheduler', --程序名称
program_action=>'sp_wty_test_scheduler', --
program_type=>'stored_procedure',
number_of_arguments=>1,
comments=>'wty_test_scheduler_program',
enabled =>FALSE
);
END;这个例子将会创建一个名为"program_wty_test_scheduler"的程序,类型是存储过程,过程的名称是“sp_wty_test_scheduler”。过程包含一个参数,存储过程的描述是:'wty_test_scheduler_program'。
program-2:
begin
dbms_scheduler.create_program(
program_name=> 'DAILY_BACKUP_SH',
program_type=> 'EXECUTABLE',
program_action=>'/home/oracle/script/daily_backup.sh');
end;
/这个例子将会创建一个名为"DAILY_BACKUP_SH"的程序,类型是可执行的shell脚本,脚本的名称是“/home/oracle/script/daily_backup.sh”。
SELECT * FROM user_scheduler_programs; --查询 program
EXEC dbms_scheduler.drop_program('program_wty_test_scheduler'); --删除指定 program2 program 参数:
| Parameter | Description |
|---|---|
| program_name | 要分配给程序的名称。名称在SQL名称空间中必须是唯一的。例如,程序不能与模式中的表具有相同的名称。如果没有指定名称,则会发生错误 |
| program_type | 此属性指定正在创建的程序的类型。如果没有指定,则会得到一个错误。program_type支持三个值:
|
| program_action | 此属性指定程序的操作。(存储过程的名称;具体的pl/sql代码;操作系统脚本名称) 以下操作是可能的:对于PL/SQL块,操作是执行PL/SQL代码。这些块必须以分号结束。 例如:my_proc(); or BEGIN my_proc(); END; or DECLARE arg pls_integer:= 10; BEGIN my_proc2(arg); END;。 注意,调度器将job_action包装在自己的块中,并将以下内容传递给PL/SQL以执行:开始job_action结束;这样做是为了声明一些内部调度器变量。 可以在PL/SQL代码中包含除event_message之外的任何调度程序元数据属性。使用属性名与使用任何其他PL/SQL标识符一样,调度程序将为其分配一个值。 如果它是一个匿名块,可以使用以下变量名访问特殊调度器元数据:job_name、job_owner、job_start、window_start、window_end。有关更多信息, 请参见“DEFINE_METADATA_ARGUMENT过程”。 对于存储过程,操作是存储过程的名称。如果过程驻留在作业之外的模式中,则必须指定模式。 如果需要区分大小写,请将模式名和存储过程名用双引号括起来。 例如,program_action=>'"Schema"."Procedure"'。 对于可执行文件,操作是外部可执行文件的名称,包括完整路径名,但不包括任何命令行参数。如果操作以单个问号('?')开始, 则问号将被本地作业到Oracle主目录或远程作业到调度器代理主目录的路径所取代。如果操作包含一个at符号('@'),并且作业是本地的,则用当前Oracle实例的SID替换at符号。 如果没有指定program_action,则会生成一个错误 |
| number_of_arguments | 此属性指定程序接受的参数数量。如果未指定此参数,则默认值为0。一个程序最多可以有255个参数。 如果program_type是PLSQL_BLOCK,则忽略该参数。 |
| enabled | 此标志指定是否应将程序创建为启用。如果将标志设置为TRUE,则进行有效性检查,如果所有检查都成功,则创建为启用程序。默认情况下,此标志设置为FALSE,表示未创建启用。您还可以在使用程序之前调用ENABLE过程来启用它。 |
| comments | 关于程序的描述信息。默认情况下,该属性为NULL。 |
程序和作业(任务)相比,有什么区别呢?
程序其实是可以与作业分离的,因此不同的用户可以在不同的时间段去重用它.而一个作业是属于特定的用户的; 另外,将程序与作业分离,也就激活了一个新的程序库(ProgramLibrary),利用程序库,用户可以很自由地选择特定的程序在特定的时间段运行,以及自由的配置程序执行时的参数。
create_program与create_job的关系?
创建程序并不是一个计划的必须组成部分,一个计划可以没有程序,但是必须有一个已经定义好的作业;另外,program_action这个参数也是可选的,假如程序的类型是pl/sql 块,你完全可以在创建作业时来指定它。上面已经提到了,程序和作业可以是分离的,这样一个程序的具体执行(ACTION)就可以灵活地确定。它既可以只运行一次,也可以在多个不同的作业中来重用这个执行.这样一来,在修改针对一个作业的计划时就非常灵活,你不需要重新创建pl/sql块。
运行 create_program需要什么权限 ?
要保证create_program能够顺利执行,你同样需要CREATE JOB这个系统权限. 如果一个用户拥有了createany job这个权限,它就可以创建属主为任何用户的程序(SYS用户除外),与创建作业一样,一个程序建立完毕,缺省的状态也是非激活的,当然你可以在创建程序时,显式的设置enabled参数为true来
激活它。
示例3:
BEGIN
DBMS_SCHEDULER.CREATE_PROGRAM(
program_name => 'LEO.UPDATE_STATS',
program_type => 'PLSQL_BLOCK',
program_action => 'DECLARE
sUsername varchar2(30);
cursor cur is
select username from dba_users where username not in ('SYS','SYSTEM','SYSMAN','DBSNMP')
and account_status='OPEN' and substr(username,1,5)<>'MGMT_' ;
BEGIN
OPEN cur;
FETCH cur into sUsername;
WHILE cur%Found
LOOP
DBMS_STATS.GATHER_SCHEMA_STATS (sUsername);
FETCH cur into sUsername;
END LOOP;
close cur;
END;' );
END;上面这个例子创建一个名为"UPDATE_STATS"的程序,它的类型是PL/SQL块,完成更新非系统用户的统计信息的工作。在这个基础上你可以定制一个合理的计划,来定期执行这个程序。
3 program 参数配置:
SQL> BEGIN
2 dbms_scheduler.define_program_argument(program_name=>'program_wty_test_scheduler',
3 argument_position=>1,
4 argument_type=>'varchar2',
5 default_value =>'program');
6 END;
7 /
PL/SQL procedure successfully completed在 program-1 中定义了一个参数,在这里指定参数类型和值。
在这个例子中,程序的类型是存储过程,而不是pl/sql块。
使用define_program_argument这个过程来定义一个程序所需要的参数. 有两点说明一下:
- 程序如果使用了参数,就必须事先指定,这样才能在程序被job使用时生效。
- 定义程序的参数不会改变程序的激活属性。也就是说,如果一个程序是没有激活的状态,运行了define_program_argument过程不会自动激活这个程序。
缺省情况下只有program的owner才能修改创建的程序,如果用户被授予了alter 权限 或者 create anyjob权限,就可以修改属主为另一个用户的程序。
创建计划(Schedule)
如果你已经了解了怎样创建作业(任务)和程序,就等于已经掌握怎样创建计划了。你需要做的附加工作只是指定计划的开始时间,结束时间,重复频率等等。
创建 job:
SQL> BEGIN
2 dbms_scheduler.create_job(JOB_NAME=>'job_create_wty_test',
3 job_type=> 'PLSQL_BLOCK',
4 JOB_ACTION=>'BEGIN
5 INSERT INTO wty_test_scheduler VALUES ("JOB",SYSDATE);
6 COMMIT;
7 END;',
8 ENABLED=>TRUE,
9 start_date=>sysdate,
10 repeat_interval=>'SYSTIMESTAMP + 1/(24*60)',
11 comments=>'job_create_wty_test');
12 END;
13 /
PL/SQL procedure successfully completed
EXEC dbms_scheduler.drop_job('job_create_wty_test'); --删除作业
SELECT * FROM user_scheduler_jobs; --查询所有作业查询执行结果:
SQL> SELECT t.r_id,CAST(t.r_date AS DATE) FROM wty_test_scheduler t;
R_ID CAST(T.R_DATEASDATE)
---------- --------------------
77755 2020-02-22 22:21:54
77755 2020-02-22 22:22:54
77755 2020-02-22 22:23:54
77755 2020-02-22 22:24:54
77755 2020-02-22 22:25:54
77755 2020-02-22 22:26:54
77755 2020-02-22 22:27:54
77755 2020-02-22 22:28:54
8 rows selected
SQL> 执行命令:
SQL> EXEC dbms_scheduler.enable('program_wty_test_scheduler');
PL/SQL procedure successfully completed
SQL> SELECT t.r_id,CAST(t.r_date AS DATE) FROM wty_test_scheduler t;
R_ID CAST(T.R_DATEASDATE)
---------- --------------------
77755 2020-02-22 22:21:54
77755 2020-02-22 22:22:54
77755 2020-02-22 22:23:54
77755 2020-02-22 22:24:54
77755 2020-02-22 22:25:54
77755 2020-02-22 22:26:54
77755 2020-02-22 22:27:54
77755 2020-02-22 22:28:54
77755 2020-02-22 22:29:54
77755 2020-02-22 22:30:54
10 rows selected查询 dbms_sheduler运行信息
SQL> SELECT
2 t.job_name,
3 t.ENABLED,
4 cast(t.last_start_date AS DATE),
5 t.SCHEDULE_NAME
6 FROM user_scheduler_jobs t
7 WHERE t.job_name='JOB_CREATE_WTY_TEST';
JOB_NAME ENABLED CAST(T.LAST_START_DATEASDATE) SCHEDULE_NAME
------------------------------ ------- ----------------------------- --------------------------------------------------------------------------------
JOB_CREATE_WTY_TEST TRUE 2020-02-22 22:36:54
SQL> 查询 dbms_scheduler运行成功与否信息
SQL> SELECT
2 t.JOB_NAME,
3 t.STATUS,
4 CAST(t.ACTUAL_START_DATE AS DATE) start_date,
5 CAST(t.LOG_DATE AS DATE) log_date
6 FROM user_scheduler_job_run_details t
7 WHERE t.JOB_NAME='JOB_CREATE_WTY_TEST'
8 /
JOB_NAME STATUS START_DATE LOG_DATE
-------------------------------------------------------------------------------- ------------------------------ ----------- -----------
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
JOB_NAME STATUS START_DATE LOG_DATE
-------------------------------------------------------------------------------- ------------------------------ ----------- -----------
JOB_CREATE_WTY_TEST SUCCEEDED 2020-02-22 2020-02-22
21 rows selected
SQL> 查询执行时间情况
SQL> SELECT
2 t1.WINDOW_NAME,
3 t1.REPEAT_INTERVAL,
4 t1.duration
5 FROM dba_scheduler_windows t1,
6 dba_scheduler_wingroup_members t2
7 WHERE t1.WINDOW_NAME=t2.WINDOW_NAME
8 AND t2.WINDOW_GROUP_NAME='MAINTENANCE_WINDOW_GROUP';
WINDOW_NAME REPEAT_INTERVAL DURATION
------------------------------ -------------------------------------------------------------------------------- ---------------------------------------
MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 +000 04:00:00
TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 +000 04:00:00
WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 +000 04:00:00
THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 +000 04:00:00
FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 +000 04:00:00
SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 +000 20:00:00
SUNDAY_WINDOW freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0 +000 20:00:00
7 rows selected
SQL>
综合示例:
Dome1:
1:创建一个 program 执行一个 存储过程:存储过程的作用是统计test_table表的数据数量,然后把统计数量和时间插入 COUNT_TABLE表中。program 绑定了存储过程。
create or replace procedure COUNT_INFO
as
lv_sum number;
begin
select count(rowid) into lv_sum from test_table;
insert into count_table(amount,time) values(lv_sum,sysdate);
end;
begin
dbms_scheduler.create_program(
program_name=> 'count_program', --程序名称
program_type=> 'STORED_PROCEDURE', --程序类型
program_action=> 'COUNT_INFO', --要执行的存储过程名称
enabled=> TRUE,
comments=> 'statistical magnitude'
);
end;删除程序:EXEC dbms_scheduler.drop_schedule('count_program');
2 :创建一个计划,执行 program。计划执行的时间间隔是每2分钟执行一次。
begin
dbms_scheduler.create_schedule
(
schedule_name => 'EVERY_2_MINS', --计划名称
repeat_interval => 'FREQ=MINUTELY; INTERVAL=2', --执行时间间隔
comments => 'Every 2-mins' --计划描述
);
end;删除计划:EXEC dbms_scheduler.drop_schedule('EVERY_2_MINS');
3:创建作业(任务)将程序和计划组合起来。
begin
dbms_scheduler.create_job
(
job_name => 'count_job', --job 名称
program_name => 'count_program', --程序名称
schedule_name => 'EVERY_2_MINS', -- 计划名称
comments => 'Count the number of data in the test_table', -- job 描述
enabled => TRUE -- 生效
);
end;查看执行结果:
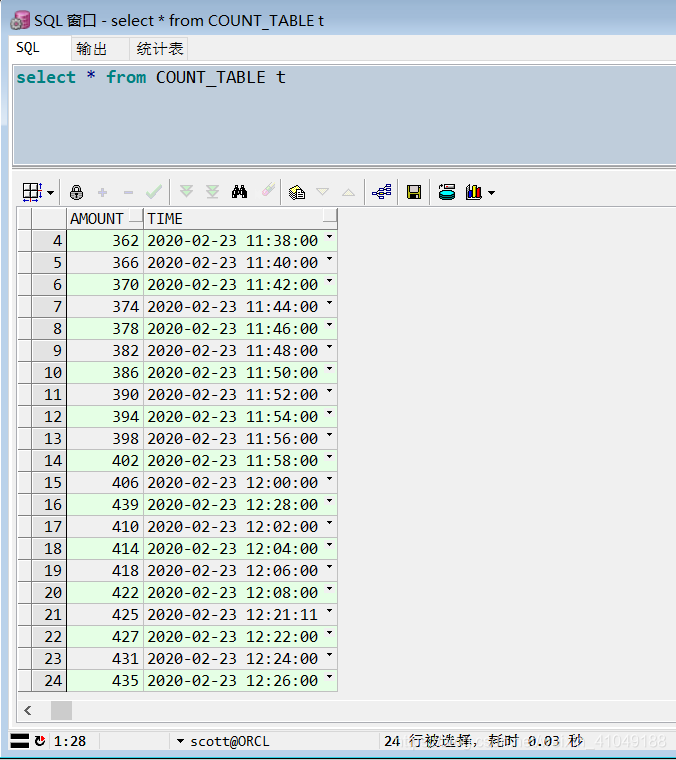
4:修改启动时间和 任务时间间隔
BEGIN
--修改计划时间间隔 为 5 分钟执行一次
dbms_scheduler.set_attribute(name =>'EVERY_2_MINS',attribute => 'repeat_interval',value => 'FREQ=MINUTELY; INTERVAL=5');
--修改计划启动时间
dbms_scheduler.set_attribute(name =>'EVERY_2_MINS',attribute => 'start_date',value => to_date('2020-02-23 13:10:00','yyyy-mm-dd hh24:mi:ss'));
END;查看任务执行情况:
select t.JOB_NAME as 任务名称,t.STATUS as 状态, to_char(t.ACTUAL_START_DATE,'yyyy-mm-dd hh24:mi:ss') 启动时间, to_char(t.LOG_DATE ,'yyyy-mm-dd hh24:mi:ss') 日志时间 from user_scheduler_job_run_details t where t.JOB_NAME='COUNT_JOB' order by t.ACTUAL_START_DATE desc;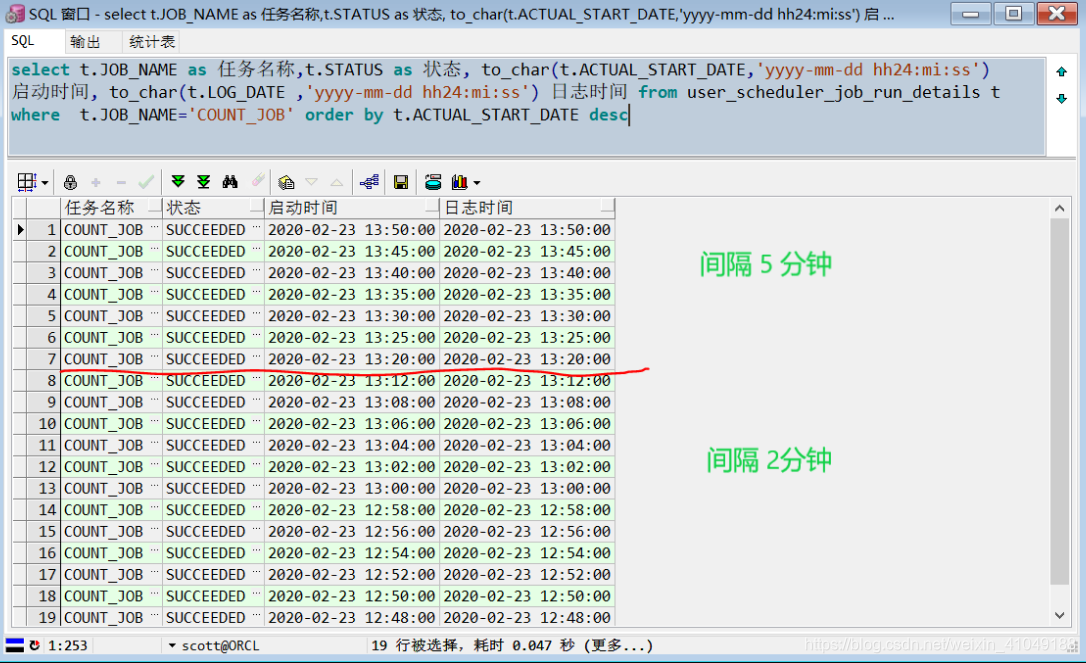
查看任务执行结果:
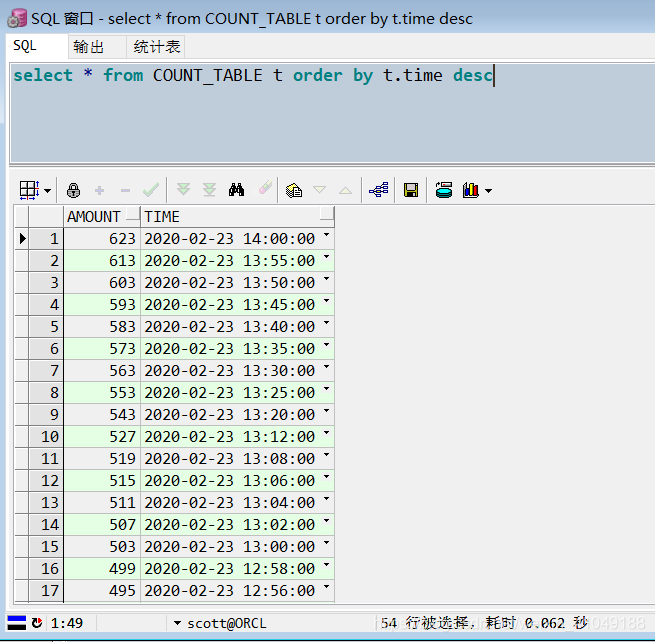

















 7738
7738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









