







 该博客介绍了如何使用Python3编写爬虫,逐页爬取CSDN上的个人博客文章,包括文章的日期、原创标记、标题、链接、浏览量和评论量。通过正则表达式解析网页源码,解压获取数据,并保存到TXT文件中。
该博客介绍了如何使用Python3编写爬虫,逐页爬取CSDN上的个人博客文章,包括文章的日期、原创标记、标题、链接、浏览量和评论量。通过正则表达式解析网页源码,解压获取数据,并保存到TXT文件中。
序
本文我实现的是一个CSDN博文爬虫,将某人csdn博客http://blog.csdn.net/fly_yr/article/list/1 中的全部博文基本信息抓取下来,每一页保存到一个文件中。
先来看一下他的博客页面(与选择的主题有关系哦,不同主题网页样式与源码是不同的~):
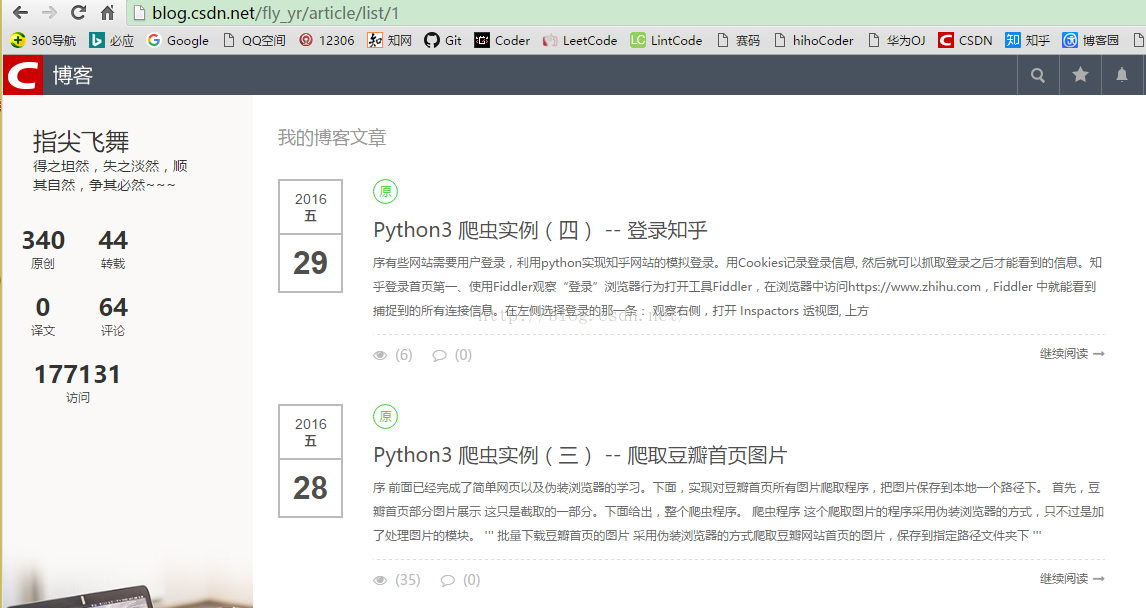
确定要提取的信息:
- 发表日期
- 是否原创标记
- 博文标题
- 博文链接
- 浏览量
- 评论量
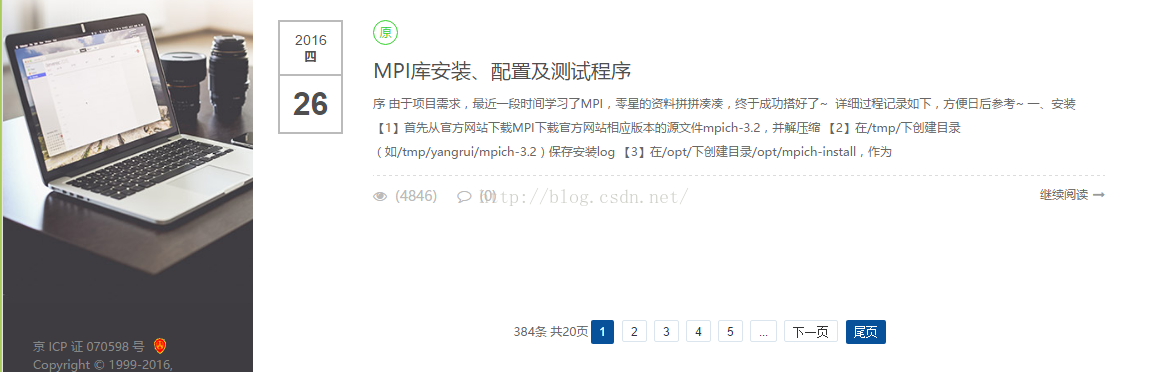
从上第二个图中可以看出,我的博文目前有20页共384条数据,我们要把所有的博文都爬取下来,就要先获取总页数。
1. 确认URL
首先,我们确认好要爬取页面的url="http://blog.csdn.net/fly_yr/article/list/1";
然后,利用Fiddler工具查看访问csdn网站所需的报头:
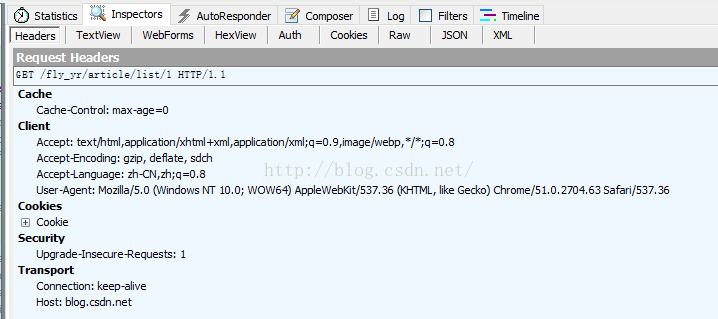
即:
最后,我们需要构造正则表达式,提取所需要的信息,下节详述。
2.分析网页源码
确认好了要抓取的信息,下面查看该网页源码(在当前网页点击右键查看源代码),构造正则表达式:
2.1 提取页数:

在当前网页源码中找到上图所示的部分,构造正则表达式:
pages = r'<div.*?pagelist">.*?<span>.*?共(.*?)页</span>'
此处,对正则表达式做简要说明:
1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2)(.*?)代表一个分组,在这个正则表达式中我们匹配了1个分组,在后面的遍历item中,item[0]就代表第一个(.*?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
2.2 提取博文信息
同理找到,关于每个博文的网页源码:

我们发现,每个博文都是有上图代码段来定义的,以<dl class="list_c clearfix">开始,到</dl>结束,我们为
- 发表日期
- 是否原创标记
- 博文标题
- 博文链接
- 浏览量
- 评论量
设计正则表达式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









