







文章目录
什么是线性结构?
线性结构(Linear Structure):是一种有序数据项的集合,其中每个数据项都有唯一的前驱和后继。
- 除了第一个没有前驱,最后一个没有后继
- 新的数据项加入到数据集中时,只会加入原有某个数据项之前或之后
- 具有这种性质的数据集,就称为线性结构。
线性结构总有两端,在不同的情况下,两端的称呼也不同:
-
有时候称为"左""右"端、“前”"后"端、“顶”"底"端

-
两端的称呼并不是关键,不同线性结构的关键区别在于数据项增减的方式
-
有的结构只允许数据项从一端添加,而有的结构则允许从两端移除

本章从4个最简单但功能强大的结构入手,开始研究数据结构:
- 栈Stack
- 队列Queue
- 双端队列Deque
- 列表List
这些数据集的共同点在于,数据项之间只存在先后的次序关系,都是线性结构。
- 这些线性结构是应用最广泛的数据结构
- 它们出现在各种算法中,用来解决大量重要问题
1.栈抽象数据类型及Python实现
1.1什么是栈?
-
栈(Stack):是一种有次序的数据项的集合,在栈中,数据项的加入和移除都仅发生在同一端
- 这一端叫栈顶(top),另一端叫栈底(base)
-
日常生活中有很多栈的应用:盘子、托盘、书堆等等

-
栈的特点是**“后进先出”**(LIFO, Last In First Out)
- 距离栈底越近的数据项,留在栈中的时间就越长
-
栈的特性:反转次序,也就是后进先出。这种访问次序反转的特性,我们在某些计算机操作上碰到过:
- 浏览器的“后退”按钮,最先back的是最近访问的网页
- Word的“Undo”按钮,最先撤销的是最近操作
1.2 抽象数据类型(ADT)Stack
- 抽象数据类型“栈”是一个有次序的数据集,每个数据项仅从“栈顶”一端加入到数据集中、从数据集中移除,栈具有LIFO的特性

- 抽象数据类型“栈”定义位如下的操作:
- Stack():创建一个空栈,不包含任何数据项
- push(item):将item加入到栈顶,无返回值
- pop():将栈顶数据项移除,并返回,栈被修改
- peek():“窥视”栈顶数据项,返回栈顶的数据项但不移除,栈不被修改
- isEmpty():返回栈是否为空栈
- size():返回栈中有多少个数据项
1.3 ADT Stack的Python实现
-
将ADT Stack实现为Python的一个Class
-
将ADT Stack的操作实现为Class的方法
-
由于Stack是一个数据集,所以可以采用Python的原生数据集来实现,我们选用最常用的数据集List来实现
-
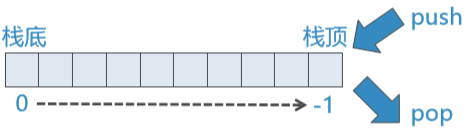
这里有一个细节:Stack的两端对应list设置
- 可以将List的任意一端(index=0 or -1)设置为栈顶
- 我们选用List的末端(index=-1)作为栈顶,这样栈的操作就可以通过list的append和pop来实现,时间复杂度均为O(1)
-
注:也可以使用列表的首端(index=0)作为栈顶,但是此时push和pop操作需要分别用list.indsert(0,item)、list.pop(0)来实现,这两个操作的时间复杂度均为O(n)
- 也可以看出不同的实现方案保持了ADT接口的稳定性,也就是ADT接口的功能没有变,但是性能有所不同
# ADT Stack的Python实现
class Stack:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[-1]
def size(self):
return len(self.items)
# Stack测试代码
s = Stack()
print(s.isEmpty())
s.push(4)
s.push('dog')
print(s.peek())
s.push(True)
print(s.size())
print(s.isEmpty())
s.push(8.4)
print(s.pop())
print(s.pop())
print(s.size())
True
dog
3
False
8.4
True
2
1.4 栈的应用
1.4.1 括号匹配
1.4.1.1 简单括号匹配
-
括号的使用必须遵循“平衡”规则
- 首先,每个开括号要恰好对应一个闭括号
- 其次,每对开闭括号要正确的嵌套
- 正确的括号:(()()()()),(((()))),(()((())()))
- 错误的括号:((((((()),())),(()()(()
-
对括号是否正确匹配的识别,是很多语言编译器的基础算法
-
下面看看如何构造括号匹配识别算法
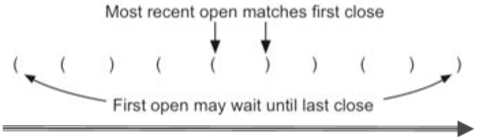
- 从左到右扫描括号串,最新打开的左括号,应该匹配最先遇到的右括号
- 这样,第一个左括号(最早打开),就应该匹配最后一个右括号(最后遇到)
- 这种次序反转的识别,正好符合栈的特性!
-
算法的流程图如下:

def parChecker(symbolString):
s = Stack()
balanced = True
index = 0
while index < len(symbolString) and balanced:
symbol = symbolString[index]
# 经leetcode测试,in要比==节省时间
if symbol in "(":
s.push(symbol)
else:
if s.isEmpty():
balanced = False
else:
s.pop()
index += 1
# if balanced and s.isEmpty():
# return True
# else:
# return False
return balanced and s.isEmpty()
print(parChecker('((()))'))
print(parChecker('(()'))
True
False
1.4.1.2 通用括号匹配算法
-
在实际的应用里,我们会碰到更多种括号
- 如python中列表所用的方括号“[]”
- 字典所用的花括号“{}”
- 元组和表达式所用的圆括号“()”
-
这些不同的括号有可能混合在一起使用
-
因此就要注意各自的开闭匹配情况
-
下面这些是匹配的
- { { ( [ ] [ ] ) } ( ) }
- [ [ { { ( ( ) ) } } ] ]
- [ ] [ ] [ ] ( ) { }
-
下面这些是不匹配的
- ( [ ) ]
- ( ( ( ) ] ) ) [ { ( ) ]
-
对上面的匹配函数稍加修改就可以:
- 碰到各种左括号依然入栈
- 碰到各种右括号的时候需要判断栈顶的左括号是否与之是同一类
def parChecker2(symbolString):
s = Stack()
balanced = True
index = 0
while index < len(symbolString) and balanced:
symbol = symbolString[index]
if symbol in "([{":
s.push(symbol)
else:
if s.isEmpty():
balanced = False
else:
top = s.pop()
if not matches(top, symbol):
balanced = False
index += 1
return balanced and s.isEmpty()
def matches(open, close):
opens = "([{"
closers = ")]}"
return opens.index(open) == closers.index(close)
print(parChecker2("{{([][])}()}"))
print(parChecker2("[{()]"))
True
False
- HTML/XML文档也有类似于括号的开闭标记,这种层次结构化文档的校验、操作也可以通过栈来实现

1.4.2 进制转换
1.4.2.1 十进制转换为二进制
-
所谓的“进制”,就是用多少个字符来表示整数
- 十进制是0~9这十个数字字符,二进制是0、1两个字符
-
我们经常需要将整数在二进制和十进制之间转换
- 如:(233)
10
_{10}
10的对应二进制数为(11101001)
2
_2
2, 具体是这样:
- (233) 10 _{10} 10=2×10 2 ^2 2+3×10 1 ^1 1+3×10 0 ^0 0
- (11101001) 2 _2 2=1×2 7 ^7 7+1×2 6 ^6 6+1×2 5 ^5 5+0×2 4 ^4 4+1×2 3 ^3 3 +0×2 2 ^2 2+0×2 1 ^1 1+1×2 0 ^0 0
- 如:(233)
10
_{10}
10的对应二进制数为(11101001)
2
_2
2, 具体是这样:
-
十进制转换为二进制,采用的是“除以2求余数”的算法
- 将整数不断除以2,每次得到的余数就是由低到高的二进制位

- 将整数不断除以2,每次得到的余数就是由低到高的二进制位
-
“除以2”的过程,依次得到的余数是从低到高的次序,而输出则是从高到低,所以需要一个栈来反转次序
def divideBy2(decNumber):
remstack = Stack()
while decNumber > 0:
rem = decNumber % 2
remstack.push(rem)
decNumber //= 2
binString = ""
while not remstack.isEmpty():
binString += str(remstack.pop())
return binString
print(divideBy2(42))
101010
1.4.2.2 扩展到更多进制转换-十进制转换为十六进制及以下任意进制
-
十进制转换为二进制的算法,很容易可以扩展为转换到任意N进制
- 只需要将“除以2求余数”算法改为“除以N求余数”算法就可以
-
计算机中另外两种常用的进制是八进制和十六进制
- (233) 10 _{10} 10等于(351) 8 _8 8和(E9) 16 _{16} 16
- (351) 8 _8 8=3×8 2 ^2 2+5×8 1 ^1 1+1×8 0 ^0 0
- (E9) 16 _{16} 16=14×16 1 ^1 1+9×16 0 ^0 0
-
主要的问题是如何表示八进制及十六进制
- 二进制有两个不同数字0、1
- 十进制有十个不同数字0、1、2、3、4、5、6、 7、8、9
- 八进制可用八个不同数字0、1、2、3、4、5、6 、7
- 十六进制的十六个不同数字则是0、1、2、3、4 、5、6、7、8、9、A、B、C、D、E、F
def baseConverter(decNumber, base):
digits = "0123456789ABCDEF"
remstack = Stack()
while decNumber > 0:
rem = decNumber % base
remstack.push(rem)
decNumber //= base
newString = ""
while not remstack.isEmpty():
newString += digits[remstack.pop()]
return newString
print(baseConverter(25,2))
print(baseConverter(25,16))
11001
19
1.4.3 表达式转换(至此开始简化)
中缀表达式
- 我们通常看到的表达式象这样:B*C,很容易知道这是B乘以C
- 这种操作符(operator)介于操作数(operand)中间的表示法,称为“中缀”表示法
- 但有时候中缀表示法会引起混淆,如“A+B*C”
- 是A+B然后再乘以C
- 还是B*C然后再去加A?
前缀和后缀表达式
-
例如中缀表达式A+B
- 将操作符移到前面,变为“+AB”
- 或者将操作符移到最后,变为“AB+”
-
我们就得到了表达式的另外两种表示法: “前缀”和“后缀”表示法
- 以操作符相对于操作数的位置来定义
-
这样A+B*C将变为前缀的“+A*BC”, 后缀的“ABC*+”
-
在前缀和后缀表达式中,操作符的次序完全决定了运算的次序,不再有混淆
- 所以在很多情况下,表达式的计算机表示都避免用复杂的中缀形式
1.4.3.1 通用的中缀转后缀算法
流程说明
- 后面的算法描述中,约定中缀表达式是由空格隔开的一系列单词(token)构成,
- 操作符单词包括*/±()
- 而操作数单词则是单字母标识符A、B、C等。
- 首先,创建空栈opstack用于暂存操作符 ,空表postfixList用于保存后缀表达式
- 将中缀表达式转换为单词(token)列表
- A+B*C =split=> [‘A’, ‘+’, ‘B’, ‘*’, ‘C’]
流程
- 从左到右扫描中缀表达式单词列表
- 如果单词是操作数,则直接添加到后缀表达式列表的末尾
- 如果单词是左括号“(”,则压入opstack栈顶
- 如果单词是右括号“)”,则反复弹出opstack栈顶操作符,加入到输出列表末尾,直到碰到左括号
- 如果单词是操作符“*/±”,则压入opstack栈顶
- 但在压入之前,要比较其与栈顶操作符的优先级
- 如果栈顶的高于或等于它,就要反复弹出栈顶操作符,加入到输出列表末尾
- 直到栈顶的操作符优先级低于它
- 中缀表达式单词列表扫描结束后,把opstack栈中的所有剩余操作符依次弹出,添加到输出列表末尾
- 把输出列表再用join方法合并成后缀表达式字符串,算法结束
实例

def infixToPostfix(infixexpr):
prec = {}
prec["*"] = 3
prec["/"] = 3
prec["+"] = 2
prec["-"] = 2
prec["("] = 1
opStack = Stack()
postfixList = []
tokenList = infixexpr.split(" ")
for token in tokenList:
if token in "ABCDEFGHIJKLMNOPQRSTUVWXYZ" or token in "0123456789":
postfixList.append(token)
elif token in "(":
opStack.push(token)
elif token in ")":
topToken = opStack.pop()
while topToken != "(":
postfixList.append(topToken)
topToken = opStack.pop()
else:
while (not opStack.isEmpty()) and (prec[opStack.peek()] >= prec[token]):
postfixList.append(opStack.pop())
opStack.push(token)
while not opStack.isEmpty():
postfixList.append(opStack.pop())
return " ".join(postfixList)
print(infixToPostfix("A + B * C"))
print(infixToPostfix("A * B + C * D"))
A B C * +
A B * C D * +
1.4.4 后缀表达式求值
- 跟中缀转换为后缀问题不同,
- 在对后缀表达式从左到右扫描的过程中,
- 由于操作符在操作数的后面,
- 所以要暂存操作数,在碰到操作符的时候,再将暂存的两个操作数进行实际的计算
- 仍然是栈的特性:操作符只作用于离它最近的两个操作数
流程
- 创建空栈operandStack用于暂存操作数
- 将后缀表达式用split方法解析为单词(token)的列表
- 从左到右扫描单词列表
- 如果单词是一个操作数,将单词转换为整数int,压入operandStack栈顶
- 如果单词是一个操作符(*/±),就开始求值,从栈顶弹出2个操作数,先弹出的是右操作数,后弹出的是左操作数,计算后将值重新压入栈顶
- 单词列表扫描结束后,表达式的值就在栈顶
- 弹出栈顶的值,返回
实例

def postinfxiEval(postfixeExpr):
operandStack = Stack()
tokenList = postfixeExpr.split(" ")
for token in tokenList:
if token in "0123456789":
operandStack.push(int(token))
else:
operand2 = operandStack.pop()
operand1 = operandStack.pop()
result = doMath(token, operand1, operand2)
operandStack.push(result)
return operandStack.pop()
def doMath(op, op1, op2):
if op == "*":
return op1 * op2
elif op == "/":
return op1 / op2
elif op == "+":
return op1 + op2
else:
return op1 - op2
postfixExpr = infixToPostfix("1 * 3 + 2 * 6")
print(postfixExpr)
finalResult = postinfxiEval(postfixExpr)
print(finalResult)
1 3 * 2 6 * +
15
2.队列抽象数据类型及Python实现
2.1 什么是队列?
- 队列是一种有次序的数据集合,其特征是
- 新数据项的添加总发生在一端(通常称为“尾 rear”端)
- 而现存数据项的移除总发生在另一端(通常称为“首front”端)
- 当数据项加入队列,首先出现在队尾,随着队首数据项的移除,它逐渐接近队首

- 新加入的数据项必须在数据集末尾等待, 而等待时间最长的数据项则是队首
- 这种次序安排的原则称为(FIFO:First-in first-out)先进先出
- 或“先到先服务first-come first-served”
- 队列仅有一个入口和一个出口
- 不允许数据项直接插入队中,也不允许从中间移 除数据项
计算机科学中队列的例子:
- 打印队列
- 进程调度
- 键盘缓冲
2.2 抽象数据类型Queue
-
抽象数据类型Queue是一个有次序的数据集合
- 数据项仅添加到“尾rear”端
- 而且仅从“首front”端移除
- Queue具有FIFO的操作次序
-
抽象数据类型Queue由如下操作定义:
- Queue():创建一个空队列对象,返回值为Queue对象;
- enqueue(item):将数据项item添加到队尾,无返回值;
- dequeue():从队首移除数据项,返回值为队首数据项,队列被修改;
- isEmpty():测试是否空队列,返回值为布尔值
- size():返回队列中数据项的个数
2.3 ADT Queue的Python实现
- 采用List来容纳Queue的数据项
- 将List首端作为队列尾端
- List的末端作为队列首端
- enqueue()复杂度为O(n)
- dequeue()复杂度为O(1)
- 首尾倒过来的实现 ,复杂度也倒过来
class Queue:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def enqueue(self, item):
self.items.insert(0,item)
def dequeue(self):
return self.items.pop()
def size(self):
return len(self.items)
2.4 队列的应用
2.4.1 热土豆问题(约瑟夫问题)
- “击鼓传花”的土豆版本
- 传烫手的热土豆,鼓声停的时候,手里有土豆的小孩就要出列
- 如果去掉鼓,改为传过固定人数,就成了“现代版”的约瑟夫问题
- 传说犹太人反叛罗马人,落到困境,约瑟夫和39人决定殉难,坐成一圈儿,报数1~7,报到7的人由旁边杀死,结果约瑟夫给自己安排了个位置,最后活了下来……
算法
- 用队列来实现热土豆问题的算法,参加游戏的人名列表,以及传土豆次数num,算法返回最后剩下的人名
- 模拟程序采用队列来存放所有参加游戏的人名,按照传递土豆方向从队首排到队尾
- 游戏时,队首始终是持有土豆的人
- 模拟游戏开始,只需要将队首的人出队,随即再到队尾入队,算是土豆的一次传递
- 传递了num次后,将队首的人移除,不再入队
- 如此反复,直到队列中剩余1人
def hotPotato(namelist, num):
simqueue = Queue()
for name in namelist:
simqueue.enqueue(name)
while simqueue.size() > 1:
for i in range(num):
simqueue.enqueue(simqueue.dequeue())
simqueue.dequeue()
return simqueue.dequeue()
print(hotPotato(["Bill", "David", "Susan", "Jane", "Kent", "Brad"], 7))
Susan
2.4.2 打印任务
-
多人共享一台打印机,采取“先到先服务”的队列策略来执行打印任务
-
在这种设定下,一个首要的问题就是:
- 这种打印作业系统的容量有多大?
- 在能够接受的等待时间内,系统能容纳多少用户以多高频率提交多少打印任务?
-
一个具体的实例配置如下:
- 一个实验室,在任意的一个小时内,大约有10名学生在场,
- 这一小时中,每人会发起2次左右的打印,每次1~20页
-
打印机的性能是:
- 以草稿模式打印的话,每分钟10页,
- 以正常模式打印的话,打印质量好,但速度下降为每分钟5页
-
问题是:怎么设定打印机的模式,让大家都不会等太久的前提下尽量提高打印质量?
-
这是一个典型的决策支持问题,但无法通过规则直接计算
-
我们要用一段程序来模拟这种打印任务场景,然后对程序运行结果进行分析,以支持对打印机模式设定的决策
如何对问题建模?
-
首先对问题进行抽象,确定相关的对象和过程
- 抛弃那些对问题实质没有关系的学生性别、年龄、打印机型号、打印内容、纸张大小等等众多细节
-
对象:打印任务、打印队列、打印机
- 打印任务的属性:提交时间、打印页数
- 打印队列的属性:具有FIFO性质的打印任务队列
- 打印机的属性:打印速度、是否忙
-
过程:生成和提交打印任务
- 确定生成概率:实例为每小时会有10个学生提交的20个作业,这样,概率是每180秒会有1个作业生成并提交,概率为每秒1/180
- 确定打印页数:实例是1~20页,那么就是1~20页之间概率相同
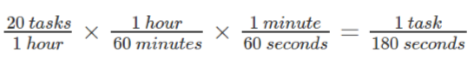
-
过程:实施打印
- 当前的打印作业:正在打印的作业
- 打印结束倒计时:新作业开始打印时开始倒计时,回0表示打印完毕,可以处理下一个作业
-
模拟时间:
- 统一的时间框架:以最小单位(秒)均匀流逝的时间,设定结束时间
- 同步所有过程:在一个时间单位里,对生成打印任务和实施打印两个过程各处理一次
模拟流程
- 创建打印队列对象
- 时间按照秒的单位流逝
- 按照概率生成打印作业,加入打印队列
- 如果打印机空闲,且队列不空,则取出队首作业打印,记录此作业等待时间
- 如果打印机忙,则按照打印速度进行1秒打印
- 如果当前作业打印完成,则打印机进入空闲
- 时间用尽,开始统计平均等待时间
- 作业的等待时间
- 生成作业时,记录生成的时间戳
- 开始打印时,当前时间减去生成时间即可
- 作业的打印时间
- 生成作业时,记录作业的页数
- 开始打印时,页数除以打印速度即可
import random
class Printer:
def __init__(self, ppm):
self.pagerate = ppm # 打印速度
self.currentTask = None # 打印任务
self.timeRemaining = 0 # 任务倒计时
def tick(self): # 打印1秒
if self.currentTask != None:
self.timeRemaining -= 1
if self.timeRemaining <= 0:
self.currentTask = None
def busy(self): # 打印忙?
if self.currentTask != None:
return True
else:
return False
def startNext(self, newtask): # 打印新作业
self.currentTask = newtask
self.timeRemaining = newtask.getPages()*60/self.pagerate
class Task:
def __init__(self, time):
self.timestamp = time # 生成时间戳
self.pages = random.randrange(1,21) # 打印页数
def getStamp(slef):
return self.timestamp
def getPages(self):
return self.pages
def waitTime(self, currenttime):
return currenttime - self.timestamp # 等待时间
def newPrintTask():
num = random.randrange(1,181) # 1/180概率生成作业
if num == 100:
return True
else:
return False
def simulation(numSeconds, pagesPerMinute): # 模拟
labprinter = Printer(pagesPerMinute)
printQueue = Queue()
waitingtimes = []
for currentSecond in range(numSeconds): # 时间流逝
if newPrintTask():
task = Task(currentSecond)
printQueue.enqueue(task)
if (not labprinter.busy()) and (not printQueue.isEmpty()):
nexttask = printQueue.dequeue()
waitingtimes.append(nexttask.waitTime(currentSecond))
labprinter.startNext(nexttask)
labprinter.tick()
averageWait = sum(waitingtimes) / len(waitingtimes)
print("Average Wait %6.2f secs %3d tasks remaining." % (averageWait, printQueue.size()))
return averageWait
运行和分析
- 按5PPM、1小时的设定,模拟运行10次
- 总平均等待时间130.56秒,最长的平均等待260.43秒 ,最短的平均等待22秒
- 有3次模拟,还有作业没开始打印
total_averageWait = []
for i in range(10):
averageWait = simulation(3600 , 5)
total_averageWait.append(averageWait)
max_averageWait = max(total_averageWait)
min_averageWait = min(total_averageWait)
total_averageWait = sum(total_averageWait) / len(total_averageWait)
print("Total Average Wait %6.2f secs, Max Average Wait %6.2f secs, min %6.2f secs" \
% (total_averageWait, max_averageWait, min_averageWait))
Average Wait 63.35 secs 0 tasks remaining.
Average Wait 41.47 secs 0 tasks remaining.
Average Wait 161.46 secs 1 tasks remaining.
Average Wait 141.58 secs 0 tasks remaining.
Average Wait 61.50 secs 0 tasks remaining.
Average Wait 42.00 secs 0 tasks remaining.
Average Wait 66.76 secs 0 tasks remaining.
Average Wait 86.10 secs 1 tasks remaining.
Average Wait 411.35 secs 1 tasks remaining.
Average Wait 356.50 secs 5 tasks remaining.
Total Average Wait 143.21 secs, Max Average Wait 411.35 secs, min 41.47 secs
- 提升打印速度到10PPM、1小时的设定
- 总平均等待时间12秒,最长的平均等待35秒,最短的平均等待0秒,就是一提交就打印了
- 而且,所有作业都打印了
total_averageWait = []
for i in range(10):
averageWait = simulation(3600 , 10)
total_averageWait.append(averageWait)
max_averageWait = max(total_averageWait)
min_averageWait = min(total_averageWait)
total_averageWait = sum(total_averageWait) / len(total_averageWait)
print("Total Average Wait %6.2f secs, Max Average Wait %6.2f secs, min %6.2f secs" \
% (total_averageWait, max_averageWait, min_averageWait))
Average Wait 7.38 secs 0 tasks remaining.
Average Wait 12.25 secs 0 tasks remaining.
Average Wait 16.88 secs 0 tasks remaining.
Average Wait 12.18 secs 0 tasks remaining.
Average Wait 16.05 secs 0 tasks remaining.
Average Wait 7.41 secs 0 tasks remaining.
Average Wait 10.36 secs 0 tasks remaining.
Average Wait 11.58 secs 0 tasks remaining.
Average Wait 13.33 secs 0 tasks remaining.
Average Wait 10.11 secs 0 tasks remaining.
Total Average Wait 11.75 secs, Max Average Wait 16.88 secs, min 7.38 secs
讨论
-
为了对打印模式设置进行决策,我们用模拟程序来评估任务等待时间
- 通过两种情况模拟仿真结果的分析,我们认识到如果有那么多学生要拿着打印好的程序源代码赶去上课的话
- 那么,必须得牺牲打印质量,提高打印速度
-
模拟系统对现实的仿真
- 在不耗费现实资源的情况下——有时候真实的实验是无法进行的
- 可以以不同的设定,反复多次模拟
- 来帮助我们进行决策
-
打印任务模拟程序还可以加进不同设定,来进行更丰富的模拟
- 学生数量加倍了会怎么样?
- 如果在周末,学生不需要赶去上课,能接受更长等待时间,会怎么样?
- 如果改用Python编程,源代码大大减少,打印的页数减少了,会怎么样?
-
更真实的模拟,来源于对问题的更精细建模,以及以真实数据进行设定和运行
-
也可以扩展到其它类似决策支持问题
- 如:饭馆的餐桌设置,使得顾客排队时间变短
3.双端队列抽象数据类型及Python实现
3.1 什么是Deque?
-
双端队列Deque是一种有次序的数据集,
- 跟队列相似,其两端可以称作“首”“尾”端,
- 但deque中数据项既可以从队首加入,也可以从队尾加入;数据项也可以从两端移除。
- 某种意义上说,双端队列集成了栈和队列的能力

-
但双端队列并不具有内在的LIFO或者FIFO特性
- 如果用双端队列来模拟栈或队列,需要由使用者自行维护操作的一致性
3.2 抽象数据类型Deque
- deque定义的操作如下:
- Deque():创建一个空双端队列
- addFront(item):将item加入队首
- addRear(item):将item加入队尾
- removeFront():从队首移除数据项,返回值为移除的数据项
- removeRear():从队尾移除数据项,返回值为移除的数据项
- isEmpty():返回deque是否为空
- size():返回deque中包含数据项的个数
3.3 ADT Deque的Python实现
- 采用List实现
- List下标0作为deque的尾端
- List下标-1作为deque的首端
- 操作复杂度
- addFront/removeFront O(1)
- addRear/removeRear O(n)
class Deque:
def __init__(self):
self .items = []
def isEmpty(self):
return self.items == []
def addFront(self, item):
self.items.append(item)
def addRear(self, item):
self.items.insert(0, item)
def removeFront(self):
return self.items.pop()
def removeRear(self):
return self.items.pop(0)
def size(self):
return len(self.items)
3.4 双端队列的应用
3.4.1 回文词判定
- “回文词”指正读和反读都一样的词
- 如radar、madam、toot
- 中文“上海自来水来自海上”、“山东落花生花落东山”
- 用双端队列很容易解决“回文词”问题
- 先将需要判定的词从队尾加入deque
- 再从两端同时移除字符判定是否相同,直到deque中剩下0个或1个字符

def palchecker(aString):
chardeque = Deque()
for ch in aString:
chardeque.addRear(ch)
stillEqual = True
while chardeque.size() > 1 and stillEqual:
first = chardeque.removeFront()
last = chardeque.removeRear()
if first != last:
stillEqual = False
return stillEqual
print(palchecker("lsdkjfskf"))
print(palchecker("radar"))
False
True
print(palchecker("上海自来水来自海上"))
True
4.无序表抽象数据类型及Python实现
4.1 列表List:什么是列表?
-
在前面基本数据结构的讨论中,我们采用Python List来实现了多种线性数据结构
-
列表List是一种简单强大的数据集结构,提供了丰富的操作接口
- 但并不是所有的编程语言都提供了List数据类型 ,有时候需要程序员自己实现。
-
列表:是一种数据项按照相对位置存放的数据集
- 特别的,被称为“无序表”(UnorderedList)
- 其中数据项只按照存放位置来索引,如第1个、 第2个……、最后一个等。(为了简单起见,假设表中不存在重复数据项)
-
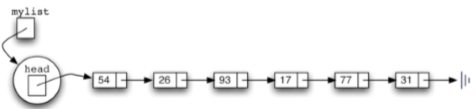
如一个考试分数的集合“54, 26, 93, 17, 77和31”
-
如果用无序表来表示,就是[54, 26, 93, 17, 77, 31]
4.2 抽象数据类型:UnorderedList
- 无序表List的操作如下:
-
List():创建一个空列表
-
add(item):添加一个数据项到列表中,假设item原先不存在于列表中
-
remove(item):从列表中移除item,列表被修改,item原先应存在于表中
-
search(item):在列表中查找item,返回布尔类型值
-
isEmpty():返回列表是否为空
-
size():返回列表包含了多少数据项
-
append(item):添加一个数据项到表末尾,假设item原先不存在于列表中
-
index(item):返回数据项在表中的位置
-
insert(pos, item):将数据项插入到位置pos,假设item原先不存在与列表中,同时原列表具有足够多个数据项,能让item占据位置pos
-
pop():从列表末尾移除数据项,假设原列表至少有1个数据项
-
pop(pos):移除位置为pos的数据项,假设原列表存在位置pos
-
4.3 ADT UnorderedList的Python实现
采用链表实现无序表
-
为了实现无序表数据结构,可以采用链接表的方案。
-
虽然列表数据结构要求保持数据项的前后相对位置,但这种前后位置的保持,并不要求数据项依次存放在连续的存储空间
-
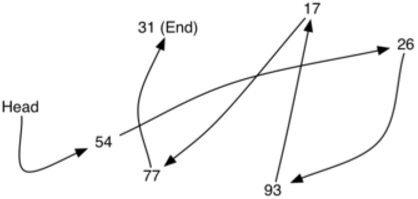
如下图,数据项存放位置并没有规则,但如果在数据项之间建立链接指向,就可以保持其前后相对位置
- 第一个和最后一个数据项需要显式标记出来,一 个是队首,一个是队尾,后面再无数据了。
链表实现:节点Node
- 第一个和最后一个数据项需要显式标记出来,一 个是队首,一个是队尾,后面再无数据了。
-
链表实现的最基本元素是节点Node
- 每个节点至少要包含2个信息:数据项本身,以及指向下一个节点的引用信息
- 注意next为None的意义是没有下一个节点了,这个很重要
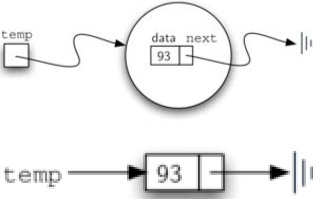
class Node:
def __init__(self,initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self,newData):
self.data = newData
def setNext(slef,newnext):
self.next = newnext
temp = Node(93)
temp.getData()
93
链表实现:无序表UnorderedList
- 可以采用链接节点的方式构建数据集来实现无序表
- 链表的第一个和最后一个节点最重要
- 如果想访问到链表中的所有节点,就必须从第一个节点开始沿着链接遍历下去
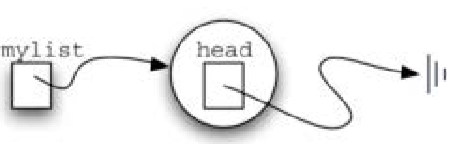
- 如果想访问到链表中的所有节点,就必须从第一个节点开始沿着链接遍历下去
- 所以无序表必须要有对第一个节点的引用信息
- 设立一个属性head,保存对第一个节点的引用
- 空表的head为None
class UnorderedList:
def __init__(self):
self.head = None
mylist = UnorderedList()
print(mylist.head)
None
链表实现:无序表UnorderedList的方法
-
isEmpty()方法
- 随着数据项的加入,无序表的head始终指向链条中的第一个节点
- 注意!无序表mylist对象本身并不包含数据项(数据项在节点中)
- 其中包含的head只是对首个节点Node的引用
- 判断空表的isEmpty()很容易实现 •return self.head == None
- 随着数据项的加入,无序表的head始终指向链条中的第一个节点
-
add()方法
- 接下来,考虑如何实现向无序表中添加数据项,实现add方法。
- 由于无序表并没有限定数据项之间的顺序,新数据项可以加入到原表的任何位置,按照实现的性能考虑,应添加到最容易加入的位置上。
- 由链表结构我们知道,要访问到整条链上的所有数据项,都必须从表头head开始沿着next链接逐个向后查找,所以添加新数据项最快捷的位置是表头,整个链表的首位置
- 要特别注意:链接次序很重要!!
-
size()方法
- size:从链条头head开始遍历到表尾同时用变量累加经过的节点个数
-
search()方法
- 从链表头head开始遍历到表尾,同时判断当前节点的数据项是否目标
-
remove(item)方法
- 首先要找到item,这个过程跟search一样,但在删除节点时,需要特别的技巧
- current指向的是当前匹配数据项的节点
- 而删除需要把前一个节点的next指向current的下一个节点
- 所以我们在search current的同时,还要维护前一个(previous)节点的引用
- 找到item之后,current指向item节点,previous指向前一个节点,开始执行删除,需要区分两种情况:
- current是首个节点;或者是位于链条中间的节
- 首先要找到item,这个过程跟search一样,但在删除节点时,需要特别的技巧
class UnorderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
def add(self, item):
temp = Node(item)
temp.setNext(self.head)
self.head = temp
def size(self):
current = self.head
count = 0
while current != None:
count += 1
current = current.getNext()
return count
def search(self, item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
mylist = UnorderedList()
print(mylist.head)
print(mylist.isEmpty())
print(mylist.size())
for i in [31, 77, 17, 93, 26, 54]:
mylist.add(i)
print(mylist.head.getData())
print(mylist.isEmpty())
print(mylist.size())
print(mylist.search(17))
mylist.remove(17)
print(mylist.search(17))
None
True
0
31
77
17
93
26
54
False
6
True
False
5.有序表抽象数据类型及Python实现
5.1 什么是有序表?
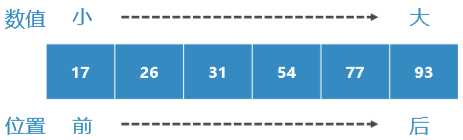
- 有序表:是一种数据项依照其某可比性质(如整数大小、字母表先后)来决定在列表中的位置
- 越“小”的数据项越靠近列表的头,越靠“前”
5.2 抽象数据类型:OrderedList
-
OrderedList所定义的操作如下:
- OrderedList():创建一个空的有序表
- add(item):在表中添加一个数据项,并保持整体顺序,此项原不存在
- remove(item):从有序表中移除一个数据项,此项应存在,有序表被修改
- search(item):在有序表中查找数据项,返回是否存在
- isEmpty():是否空表
- size():返回表中数据项的个数
- index(item):返回数据项在表中的位置,此项应存在
- pop():移除并返回有序表中最后一项,表中应至少存在一项
- pop(pos):移除并返回有序表中指定位置的数据项,此位置应存在
-
在实现有序表的时候,需要记住的是,数据项的相对位置,取决于它们之间的“大小”比较
- 由于Python的扩展性,下面对数据项的讨论并不仅适用于整数,可适用于所有定义了__gt__ 方法(即’>'操作符)的数据类型
-
以整数数据项为例,(17, 26, 31, 54, 77, 93)的链表形式如图

5.3 ADT OrderedList的Python实现
链表实现:有序表OrderedList
- 同样采用链表方法实现
- Node定义相同
- OrderedList也设置一个head来保存链表表头的引用
class OrderList:
def __init__(self):
self.head = None
链表实现:有序表OrderedList的方法
- 对于isEmpty/size/remove这些方法, 与节点的次序无关,所以其实现跟UnorderedList是一样的
- search/add方法则需要有修改
- search(item)方法
- 在无序表的search中,如果需要查找的数据项不存在,则会搜遍整个链表,直到表尾
- 对于有序表来说,可以利用链表节点有序排列的特性,来为search节省不存在数据项的查找时间
- 一旦当前节点的数据项大于所要查找的数据项, 则说明链表后面已经不可能再有要查找的数据项,可以直接返回False
- add(item)方法
- 相比无序表,改变最大的方法是add,因为add方法必须保证加入的数据项添加在合适的位置,以维护整个链表的有序性
- 比如在(17, 26, 54, 77, 93)的有序表中,加入数据项31,我们需要沿着链表,找到第一个比31大的数据项54,将31插入到54的前面
- 由于涉及到的插入位置是当前节点之前,而链表无法得到“前驱”节点的引用
- 所以要跟remove方法类似,引入一个previous的引用,跟随当前节点current
- 一旦找到首个比31大的数据项,previous就派上用场了
class OrderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
def size(self):
current = self.head
count = 0
while current != None:
count += 1
current = current.getNext()
return count
def search(self,item):
current = self.head
found = False
stop = False
while current != None and not found and not stop:
if current.getData() == item:
found = True
else:
if current.getData() > item:
stop = True
else:
current = current.getNext()
return found
def add(self,item):
current = self.head
previous = None
stop = False
while current != None and not stop:
if current.getData() > item: # 发现插入位置
stop = True
else:
previous = current
current = current.getNext()
temp = Node(item)
if previous == None: # 插入在表头
temp.setNext(self.head)
self.head = temp
else: # 插入在表中
temp.setNext(current)
previous.setNext(temp)
def remove(self, item):
current = self.head
previous = None
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
mylist = OrderedList()
print(mylist.head)
print(mylist.isEmpty())
print(mylist.size())
for i in [31, 77, 17, 93, 26, 54]:
mylist.add(i)
print(mylist.head.getData())
print(mylist.isEmpty())
print(mylist.size())
print(mylist.search(17))
mylist.remove(17)
print(mylist.search(17))
None
True
0
31
31
17
17
17
17
False
6
True
False
5.4 链表实现的算法分析
- 对于链表复杂度的分析,主要是看相应的方法是否涉及到链表的遍历
- 对于一个包含节点数为n的链表
-
isEmpty是O(1),因为仅需要检查head是否为None
-
size是O(n),因为除了遍历到表尾,没有其它办法得知节点的数量
-
search/remove以及有序表的add方法,则是O(n),因为涉及到链表的遍历,按照概率其平均操作的次数是n/2
-
无序表的add方法是O(1),因为仅需要插入到表头
-
链表实现的List,跟Python内置的列表数据类型,在有些相同方法的实现上的时间复杂度不同
-
主要是因为Python内置的列表数据类型是基于顺序存储来实现的,并进行了优化
-
6.线性结构小结
- 线性数据结构(Linear DS)将数据项以某种线性的次序组织起来
- 栈Stack
- 栈Stack维持了数据项后进先出LIFO的次序
- stack的基本操作包括push, pop, isEmpty
- 书写表达式的方法有前缀prefix、中缀 infix和后缀postfix三种
- 由于栈结构具有次序反转的特性,所以栈结构适合用于开发表达式求值和转换的算法
- 栈Stack维持了数据项后进先出LIFO的次序
- 队列Queue
- 队列Queue维持了数据项先进先出FIFO的次序
- queue的基本操作包括enqueue, dequeue, isEmpty
- “模拟系统”可以通过一个对现实世界问题进行抽象建模,并加入随机数动态运行,为复杂问题的决策提供各种情况的参考
- 队列queue可以用来进行模拟系统的开发
- 队列Queue维持了数据项先进先出FIFO的次序
- 双端队列Deque
- 双端队列Deque可以同时具备栈和队列的功能
- deque的主要操作包括addFront, addRear, removeFront, removeRear, isEmpty
- 双端队列Deque可以同时具备栈和队列的功能
- 列表List
- 列表List是数据项能够维持相对位置的数据集
- 链表的实现,可以保持列表维持相对位置的特点,而不需要连续的存储空间
- 链表实现时,其各种方法,对链表头部head需要特别的处理
参考资料:
1.数据结构与算法Python版















 2944
2944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









