







堆外内存的回收条件:

Buffer底层原理:

直接内存和堆内存源码实现:
// Buffer的基类,其中定义了四个索引下标的用法
public abstract class Buffer {
// 不变性质: mark <= position <= limit <= capacity
private int mark = -1; // 标记索引下标
private int position = 0; // 当前处理索引下标
private int limit; // 限制索引下标(通常用于在写入后,标记读取的最终位置)
private int capacity; // 容量索引下标
// 用于指向DirectByteBuffer的地址
long address;
}
// 直接继承自Buffer基类,实现了字节缓冲区的基本操作和创建实际Buffer实例的工厂方法
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>{
final byte[] hb; // 用于HeapByteBuffer中的字节数组
// 默认分配的为堆内存
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity); // 创建堆内存对象
}
// 可以通过该方法创建直接内存缓冲区
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity); // 创建直接内存缓冲区
}
}
// 该类继承自ByteBuffer,实现了堆内存中字节数组的实现,该类不是public共有类,只能通过ByteBuffer来创建实例
class HeapByteBuffer extends ByteBuffer{
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0); // 直接初始化hb字节数组
}
}
// 该类继承自ByteBuffer,提供了文件fd与用户空间地址的映射
public abstract class MappedByteBuffer extends ByteBuffer{
private final FileDescriptor fd; // 文件fd
MappedByteBuffer(int mark, int pos, int lim, int cap,FileDescriptor fd)
{
super(mark, pos, lim, cap);
this.fd = fd;
}
MappedByteBuffer(int mark, int pos, int lim, int cap) { // 不使用FD映射,支撑DirectByteBuffer
super(mark, pos, lim, cap);
this.fd = null;
}
}
// 该类继承自MappedByteBuffer,提供了直接内存缓冲区的实现
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer{
protected static final Unsafe unsafe = Bits.unsafe(); // 操作的Unsafe对象
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap); // 初始化父类
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); // 分配直接内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); // 用于清理分配的直接内存
att = null;
}
}
Netty的ByteBuf:
Netty的ByteBuf就是对NIO的ByteBuffer做了层封装

对象池提升了什么性能?
1.减少YGC产生的系统损耗,如果对象用完就释放,那么在YGC的时候就会回收掉,就会造成时间损耗。如果用了对象池,那么在GC过程中,会把对象池的对象挪到old区,此时就不会影响到YGC。
2.可以避免在创建对象和销毁对象时产生的性能损耗。
什么时候把ByteBuf对象放回对象池?
首先主要有四种垃圾回收算法:
1.引用计数 reference count,当引用计数变为0时,就认为是垃圾,但是此种方式不能解决循环引用的问题
A → B → C
↑________↓
2.Mark-Sweep(标记清除):算法相对简单,存活对象比较多的情况下效率较高;两遍扫描,效率偏低,容易产生碎片
3.Copying(拷贝) :适用于存活对象比较少的情况,只扫描一次,效率提高,没有碎片;空间浪费,需要调整对象引用
4.Mark-Compact(标记压缩):不会产生碎片,方便对象分配,不会产生内存减半;但是需要扫描两次,需要移动对象,效率偏低,这种算法在标记阶段跟markSweep算法是一样的,但是在完成标记之后,不是直接清理垃圾内存,而是将存活对象往一端移动,然后将端边界以外的所有内存直接清除
而ByteBuf就是使用的引用计数算法,就是ReferenceCounted
public interface ReferenceCounted {
int refCnt();
ReferenceCounted retain();
ReferenceCounted retain(int var1);
ReferenceCounted touch();
ReferenceCounted touch(Object var1);
boolean release();
boolean release(int var1);
}
public abstract class ByteBuf implements ReferenceCounted, Comparable<ByteBuf> {
}
public abstract class AbstractByteBuf extends ByteBuf {
int readerIndex;
int writerIndex;
private int markedReaderIndex;
private int markedWriterIndex;
private int maxCapacity;
}
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> AIF_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
private static final ReferenceCountUpdater<AbstractReferenceCountedByteBuf> updater =
new ReferenceCountUpdater<AbstractReferenceCountedByteBuf>() {
@Override
protected AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> updater() {
return AIF_UPDATER;//上面定义的一个属性
}
@Override
protected long unsafeOffset() {
return REFCNT_FIELD_OFFSET;
}
};
}
//这个类实现了对ReferenceCounted的操作
public abstract class ReferenceCountUpdater<T extends ReferenceCounted> {}
//对现有的对象中的普通属性进行原子性操作,不用修改源码
public abstract class AtomicIntegerFieldUpdater<T> {
//需要传递一个对象和对象中需要原子更新的字段名,底层通过反射和CAS操作
public static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> tclass,
String fieldName) {
return new AtomicIntegerFieldUpdaterImpl<U>
(tclass, fieldName, Reflection.getCallerClass());
}
}ByteBuf有两个指针:

调用discardReadBytes()

解决CAS的ABA问题:
public class AtomicStampedReference<V> {
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
}NIO的底层模型:

FileInputStream fileInputStream = new FileInputStream("NioTest1.txt");
FileChannel fileChannel = fileInputStream.getChannel();
public FileChannel getChannel() {
synchronized (this) {
if (channel == null) {
channel = FileChannelImpl.open(fd, path, true, false, this);
}
return channel;
}
}
public static FileChannel open(FileDescriptor var0, String var1, boolean var2, boolean var3, Object var4) {
return new FileChannelImpl(var0, var1, var2, var3, false, var4);
}
private FileChannelImpl(FileDescriptor var1, String var2, boolean var3, boolean var4, boolean var5, Object var6) {
this.fd = var1;
this.readable = var3;
this.writable = var4;
this.append = var5;
this.parent = var6;
this.path = var2;
this.nd = new FileDispatcherImpl(var5);
}ByteBuffer buffer = ByteBuffer.allocate(512);
fileChannel.read(buffer);
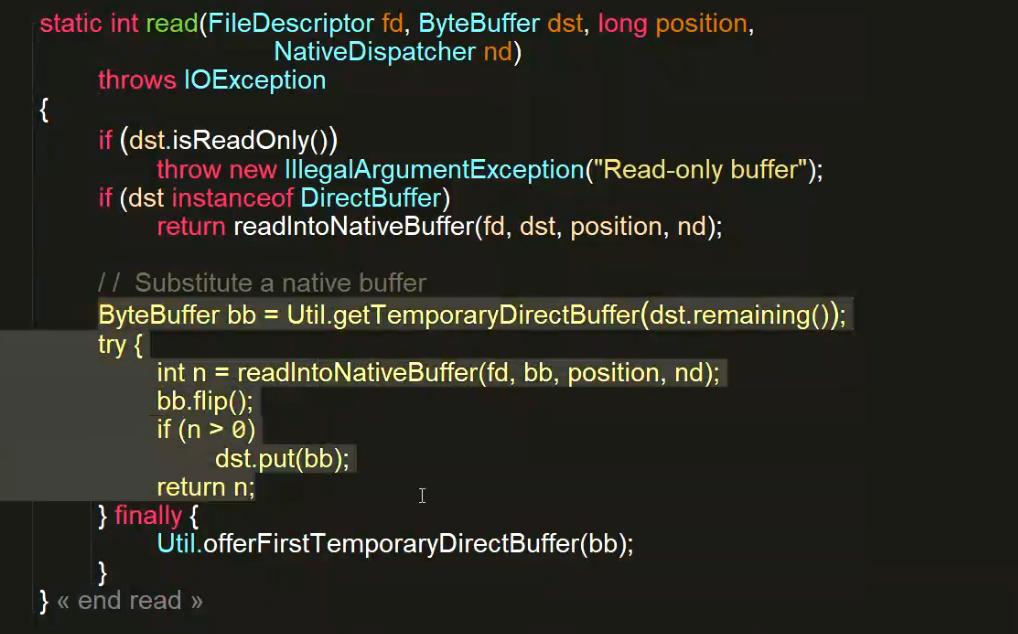
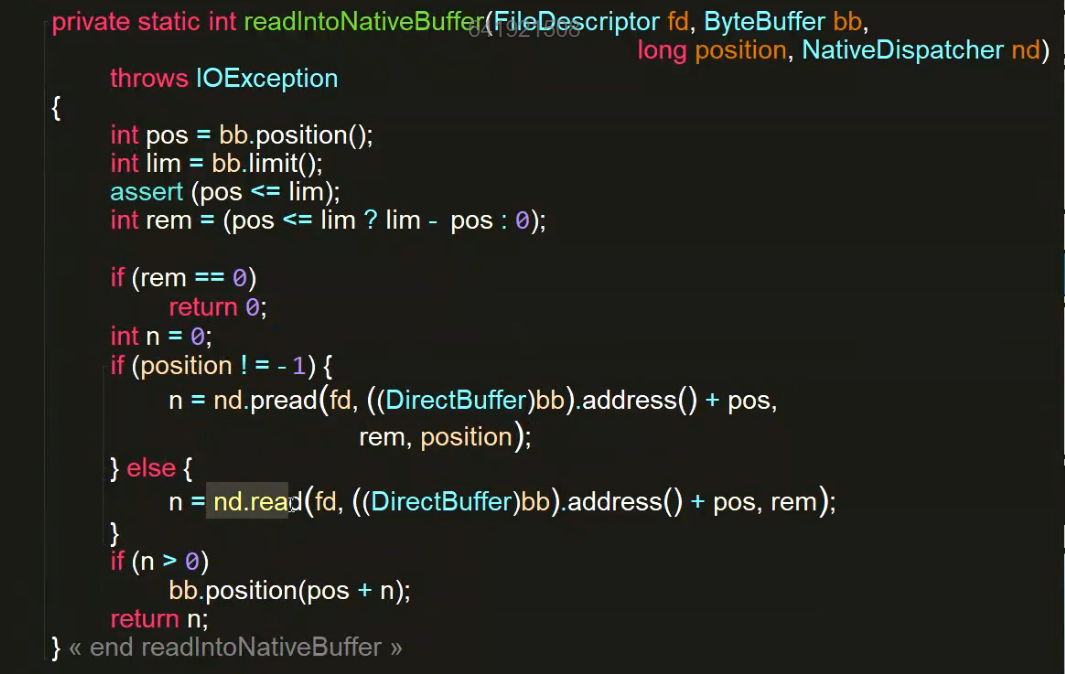
底层依然是调用了操作系统的read和write函数


Netty架构图:


Transport Services对应着Netty传输层,Protocol Support对应着Netty协议层。
什么是线程?
一个程序里不同的执行路径,就是一个搞不定,多个一起搞。
进程和线程有什么区别?
进程是OS分配资源的基本单位,线程是执行调度的基本单位(比如执行main线程,执行socket线程,
执行UI线程),分配资源最重要的是:独立的内存空间,线程调度执行(线程共享进程的内存空间
,没有自己独立的内存空间)
进程:在linux中也称为Task,是系统分配资源的基本单位,资源:独立的地址空间,
内核数据结构(进程描述符),全局变量,数据段...
线程在linux的实现:就是一个普通进程,只不过和其他进程共享资源(内存空间,全局数据等)
其他系统都有各自的所谓LWP的实现 Light Weight Process(轻量级进程)
高层面理解:一个进程中不同的执行路线在Linux源码中,创建进程调用的是sys_fork,创建线程是调用的sys_clone,底层都是调用了do_fork。区别就是克隆标记位不一样,sys_clone的clone_flags是从用户空间传过来的,sys_fork是调用的系统自身的



怎么实现高性能?
就是让线程一直搞,如果中间没有Selector,那么如果Channel没数据,线程就一直处于阻塞状态,此时再来一个连接,难道再开一个线程?这样效率很低,所以在中间加了一层Selector,线程询问Selector,是否有数据,如果没有就先去干别的事。
那么是否所有的Channel都可以注册到Selector上呢?
答案不是,所以Java中有一个SelectableChannel,通过看它的实现类可知,基本上和网络相关的Channel都可以,但是本地的,比如FileChannel是不可以的,因为FileChannel是对本地的文件进行操作,相对于网络传输来说,是非常快的。
事件循环组:
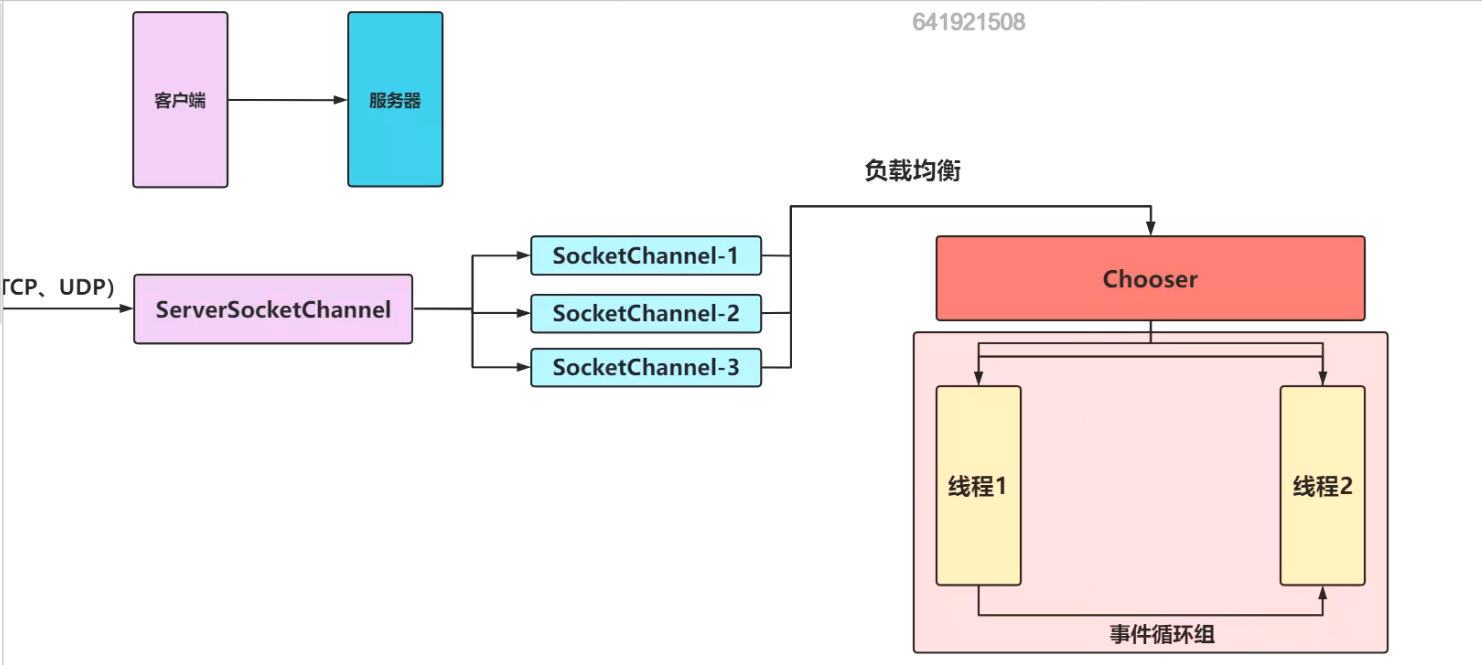
多个ServerSocketChannel会产生多个SocketChannel,如果产生了事件,就会通过Chooser注册到某个线程上进行处理,而线程与线程之间,也可以分发事件。















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









