









目录
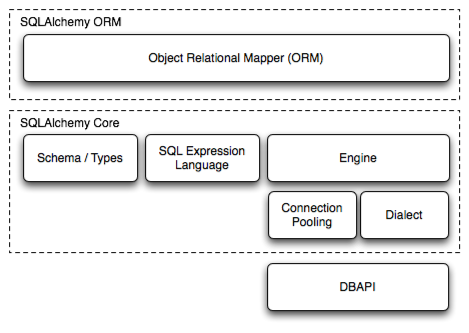
架构
版本要求:Cpython +3.7
安装:
pip install SQLAlchemy 安装对应数据库的DBAPI: https://docs.sqlalchemy.org/en/20/dialects/mysql.html (我使用了aiomysql,databases要求sqlalchemy<1.4,所以不适用) # 查看版本 >>> import sqlalchemy >>> sqlalchemy.__version__
Engine:
# 创建engine
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import declarative_base, sessionmaker
from sqlalchemy import text
#参数 echo:打印执行日志,future:使用2.0新特性,也可以使用async_engine_from_config创建,engine直到第一次请求数据库才会真正连接到数据库,称为延迟初始化
engine = create_async_engine("mysql+aiomysql://127.0.0.1:3307/test",
echo=True, future=True)
Session = sessionmaker(class_=AsyncSession,autocommit=False,
autoflush=False,bind=engine)
Base = declarative_base()
#等价于 from sqlalchemy.orm import registry
# mapper_registry = registry()
# Base = mapper_registry.generate_base()
# 简单使用
async def connect_query():
async with engine.connect() as conn:
result = await conn.execute(text("SELECT x, y FROM some_table"))
for row in result:
print(f"x: {row.x} y: {row.y}")
# 手动提交: 使用冒号声明参数
async def connect_insert():
async with engine.connect() as conn:
await conn.execute(text("CREATE TABLE some_table (x int, y int)"))
await conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
{"x": 1, "y": 1}, {"x": 2, "y": 4}
)
await conn.commit()
# 自动提交:绑定多个参数
async def connect_insert():
async with engine.begin() as conn:
await conn.execute(text("CREATE TABLE some_table (x int, y int)"))
await conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}]
)
await conn.commit()
# 使用bindparams绑定参数
async def connect_query():
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x,y").bindparams(y=6)
async with engine.connect() as conn:
result = await conn.execute(stmt)
for row in result:
print(f"x: {row.x} y: {row.y}")
# Engine.connect()从连接池中返回一个Connection对象,连接对象会被回收,而不是真正的关闭
# connection.execute返回一个CursorResult对象,类似游标,CursorResult在所有结果行(如果有)用尽时关闭。特别的如UPDATE 语句(没有任何返回的行),在执行后立即释放游标资源Result:
1. 每一条数据都是一个Row(类似具名元组),因此可以访问属性,索引
2. 返回字典对象:
for dict_row in result.mappings():
x = dict_row['x']
y = dict_row['y']
3. 获取所有结果: all()等价fetchall() → List[sqlalchemy.engine.row.Row]
4. 获取特定列:columns(*col_expressions: Union[str, Column[Any], int])
5. 获取指定条数:fetchmany(size: Optional[int] = None) → List[sqlalchemy.engine.row.Row]
6. 获取单行:fetchone() → Optional[sqlalchemy.engine.row.Row]
Result.first() → Optional[sqlalchemy.engine.row.Row] (丢弃其他数据)
7. 重复读取结果Result.freeze() → sqlalchemy.engine.FrozenResult
8. 读取列名称Result.keys() → sqlalchemy.engine.RMKeyView
9. 返回字典格式数据mappings() → sqlalchemy.engine.MappingResult
10. 结果合并merge(*others: sqlalchemy.engine.result.Result) → sqlalchemy.engine.MergedResult
11. 返回一条数据,不存在或多个时抛出异常one() → sqlalchemy.engine.Row
12. 返回一条数据或None one_or_none() → Optional[sqlalchemy.engine.row.Row
13. 分块返回,(但后台依然一次性缓存了所有数据)partitions(size: Optional[int] = one)Iterator[List[sqlalchemy.engine.row.Row]]
14. 返回第一行的第一列值,如果没有返回None: scalar() → Any
15. 返回第一行,不存在或多个则报错:scalar_one() → Any
16. 返回第一条或者None:scalar_one_or_none() → Optional[Any]
17. 返回所有数据的某一列值(默认返回第一列):scalars(index: Union[str, Column[Any], int] = 0)
18. 批量返回:yield_per(num: int) → SelfResult
sqlalchemy.engine.ScalarResult
sqlalchemy.engine.MappingResult
sqlalchemy.engine.CursorResult
都类似,编码过程中注意看result的类型,查看具体方法:https://docs.sqlalchemy.org/en/20/core/connections.html#sqlalchemy.engine.ResultSession:
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import declarative_base, sessionmaker
engine = create_async_engine("mysql+aiomysql://127.0.0.1:3307/test",
echo=True, future=True)
Session = sessionmaker(class_=AsyncSession,autocommit=False,
autoflush=False,bind=engine)
Base = declarative_base()
async def session_query():
async with Session() as session:
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x, y").bindparams(y=6)
result = await session.execute(stmt)
for row in result:
print(f"x: {row.x} y: {row.y}")
async def session_update():
async with Session() as session:
result = await session.execute(
text("UPDATE some_table SET y=:y WHERE x=:x"),
[{"x": 9, "y":11}, {"x": 13, "y": 15}]
)
await session.commit()
# result 为CursorResult对象,参数绑定方式与connect相同 MetaData:
# metadata 保存所有Table 和 ORM对象
from sqlalchemy import Table, Column, Integer, String
from sqlalchemy import MetaData
metadata_obj = MetaData()
user_table = Table(
"user_account",
metadata_obj,
Column('id', Integer, primary_key=True),
Column('name', String(30)),
Column('fullname', String)
)
>>> user_table.c.name
Column('name', String(length=30), table=<user_account>)
>>> user_table.c.keys()
['id', 'name', 'fullname']
# 生成表到数据库
metadata_obj.create_all(engine)
# 删除所有表
metadata_obj.drop_all()Table And ORM:
from sqlalchemy.orm import registry,eclarative_base
from sqlalchemy.orm import relationship
Base = registry().generate_base()
Base = declarative_base(bind=engine) # 更简单的声明Base,推荐
class User(Base):
__tablename__ = 'user_account'
id = Column(Integer, primary_key=True)
name = Column(String(30))
fullname = Column(String)
# 如果使用back_populates,必须在两边对应声明
addresses = relationship("Address", back_populates="user")
def __repr__(self):
return f"User(id={self.id!r}, name={self.name!r}, fullname={self.fullname!r})"
class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
email_address = Column(String, nullable=False)
user_id = Column(Integer, ForeignKey('user_account.id'))
user = relationship("User", back_populates="addresses")
def __repr__(self):
return f"Address(id={self.id!r}, email_address={self.email_address!r})"
# User.__table__ 就是一个Table对象,相反的你也可以先声明一个Table再使用这个Table声明一个ORM类
from sqlalchemy import Table, Column, Integer, String
from sqlalchemy import MetaData
metadata_obj = MetaData()
user_table = Table(
"user_account",
metadata_obj,
Column('id', Integer, primary_key=True),
Column('name', String(30)),
Column('fullname', String)
)
Base = declarative_base(bind=engine,metadata=metadata_obj)
class User(Base):
__table__ = user_table
addresses = relationship("Address", backref="user")
def __repr__(self):
return f"User({self.name!r}, {self.fullname!r})"
# 生成所有表
Base.metadata.create_all(engine)反射表:
# 所谓反射就是读取现有数据库的表结构,生成对应的Table对象,也支持View反射,目前只支持同步engine
from sqlalchemy import create_engine
from sqlalchemy import MetaData
metadata_obj = MetaData()
engine = create_engine("mysql+pymysql://127.0.0.1:3307/test", echo=True, future=True)
# 反射单个表
some_table = Table("some_table", metadata_obj, autoload_with=engine)
# 覆盖原有属性或增加新属性
mytable = Table('mytable', metadata_obj,
Column('id', Integer, primary_key=True),
Column('mydata', Unicode(50)),
autoload_with=some_engine)
# 一次反射所有表
metadata_obj = MetaData()
metadata_obj.reflect(bind=engine)
users_table = metadata_obj.tables['users']
addresses_table = metadata_obj.tables['addresses']
# 更底层的反射可以看 inspect
# 如果我想在异步中使用反射,先使用同步engine得到反射后的metadata_obj对象,在将它传递给Base就可以了
# 也可以这样
import asyncio
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy import inspect
engine = create_async_engine(
"postgresql+asyncpg://scott:tiger@localhost/test"
)
def use_inspector(conn):
inspector = inspect(conn)
# use the inspector
print(inspector.get_view_names())
# return any value to the caller
return inspector.get_table_names()
async def async_main():
async with engine.connect() as conn:
tables = await conn.run_sync(use_inspector)插入数据:
# 插入数据
from sqlalchemy import insert
# 插入单条数据
async def insert_one():
async with Session() as session:
stmt=insert(user_table).values(name='spongebob',fullname="SpongebobSquarepants")
result = await session.execute(stmt)
await session.commit()
# 获取插入数据的主键(注意有的数据库可能不支持,必须使用insert方法构建,直接使用text方法构建的插入不能访问该属性)
result.inserted_primary_key
# 插入多条数据
async def insert_many():
async with Session() as session:
result = await session.execute(
stmt=insert(user_table),
[
{"name": "sandy", "fullname": "Sandy Cheeks"},
{"name": "patrick", "fullname": "Patrick Star"}
]
)
await session.commit()
# 插入数据的复合主键
result.inserted_primary_key_rows
# insert from select 我没有这样的场景
>>> select_stmt = select(user_table.c.id, user_table.c.name + "@aol.com")
>>> insert_stmt = insert(address_table).from_select(
... ["user_id", "email_address"], select_stmt
... )
>>> print(insert_stmt.returning(address_table.c.id, address_table.c.email_address))
# 部分数据库支持返回值
insert_stmt=insert(address_table)
.returning(address_table.c.id,address_table.c.email_address) 查询数据:
# 查询数据
async def query():
async with Session() as session:
# stmt=select(user_table).where(user_table.c.name == 'spongebob')
stmt = select(User).where(User.name == 'spongebob')
result = await session.execute(stmt)
data = result.all()
# 排序
select(User).where(User.name == 'spongebob').order_by(User.name.desc())
# 分组
select(User).where(User.name=='spongebob').group_by(User.name)
.having(func.count(Address.id) > 1)
select(Address.user_id,func.count(Address.id).label('num_addresses')).\
group_by("user_id").order_by("user_id", desc("num_addresses"))
# 属性别名
select(("Username: " + user_table.c.name).label("username"))
# 表别名
from sqlalchemy.orm import aliased
address_alias_1 = aliased(Address)
# where : ==、!=、>、<、 >= 、<=
# and_ or_
>>> from sqlalchemy import and_, or_
>>> print(
... select(Address.email_address).
... where(
... and_(
... or_(User.name == 'squidward', User.name == 'sandy'),
... Address.user_id == User.id
... )
... )
... )
#filter_by 注意是一个等号
stmt = select(Application).filter_by(app_id = app_id)
# 查询数量
select(func.count('*')).select_from(user_table)
# 指定返回数量
select(Application).filter_by(app_id = app_id).limit(1)
# 关联查询(默认为内联)
select(user_table.c.name,address_table.c.email_address).join_from(user_table,address_table)
user_alias_1 = user_table.alias()
user_alias_2 = user_table.alias()
select(user_alias_1.c.name, user_alias_2.c.name)\
.join_from(user_alias_1, user_alias_2, user_alias_1.c.id > user_alias_2.c.id)
select(user_table.c.name, address_table.c.email_address).join(address_table)
# 指定关联条件
select(address_table.c.email_address).select_from(user_table).join(address_table, user_table.c.id == address_table.c.user_id)
#外联
select(user_table).join(address_table, isouter=True)
#全联
select(user_table).join(address_table, full=True)
# 子查询
subq = select(
func.count(address_table.c.id).label("count"),
address_table.c.user_id
).group_by(address_table.c.user_id).subquery()
select(subq.c.user_id, subq.c.count)
# CTE临时结果集 cte()
# UNION Union ALL
stmt1 = select(User).where(User.name == 'sandy')
stmt2 = select(User).where(User.name == 'spongebob')
u = union_all(stmt1, stmt2)
# 判断是否存在
stmt = select(User).where(User.name == 'sandy').exists()
# 使用数据库函数 func.count():https://docs.sqlalchemy.org/en/14/core/functions.html
.....更多:https://docs.sqlalchemy.org/en/14/tutorial/data_select.html更新和删除:
# 更新数据
from sqlalchemy import update
stmt = (
update(user_table).where(user_table.c.name == 'patrick').
values(fullname='Patrick the Star')
)
# 查询并更新
from sqlalchemy import bindparam
stmt = (
update(user_table).
where(user_table.c.name == bindparam('oldname')).
values(name=bindparam('newname'))
)
async def update_db():
async with engine.begin() as conn:
conn.execute(
stmt,
[
{'oldname':'jack', 'newname':'ed'},
{'oldname':'wendy', 'newname':'mary'},
{'oldname':'jim', 'newname':'jake'},
]
)
# 有序更新
update_stmt = (
update(some_table).
ordered_values(
(some_table.c.y, 20),
(some_table.c.x, some_table.c.y + 10)
)
)
# 删除数据
from sqlalchemy import delete
stmt = delete(user_table).where(user_table.c.name == 'patrick')
# 获取执行结果影响行数
result.rowcount
# 指定返回值
update_stmt = (
update(user_table).where(user_table.c.name == 'patrick').
values(fullname='Patrick the Star').
returning(user_table.c.id, user_table.c.name)使用流式:
# 访问大量数据时
async with async_engine.connect() as conn:
result = await conn.stream("select * from user")
async for rows in result.partitions(size=100):
for row in rows:
yield row._mappingAsync ORM:
import asyncio
from sqlalchemy import Column
from sqlalchemy import DateTime
from sqlalchemy import ForeignKey
from sqlalchemy import func
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.future import select
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy.orm import selectinload
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class A(Base):
__tablename__ = "a"
id = Column(Integer, primary_key=True)
data = Column(String)
create_date = Column(DateTime, server_default=func.now())
bs = relationship("B")
# required in order to access columns with server defaults
# or SQL expression defaults, subsequent to a flush, without
# triggering an expired load
__mapper_args__ = {"eager_defaults": True}
class B(Base):
__tablename__ = "b"
id = Column(Integer, primary_key=True)
a_id = Column(ForeignKey("a.id"))
data = Column(String)
async def async_main():
engine = create_async_engine(
"postgresql+asyncpg://scott:tiger@localhost/test",
echo=True,
)
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.drop_all)
await conn.run_sync(Base.metadata.create_all)
# expire_on_commit=False will prevent attributes from being expired
# after commit.
async_session = sessionmaker(
engine, expire_on_commit=False, class_=AsyncSession
)
async with async_session() as session:
async with session.begin():
session.add_all(
[
A(bs=[B(), B()], data="a1"),
A(bs=[B()], data="a2"),
A(bs=[B(), B()], data="a3"),
]
)
stmt = select(A).options(selectinload(A.bs))
result = await session.execute(stmt)
for a1 in result.scalars():
print(a1)
print(f"created at: {a1.create_date}")
for b1 in a1.bs:
print(b1)
result = await session.execute(select(A).order_by(A.id))
a1 = result.scalars().first()
a1.data = "new data"
await session.commit()
# access attribute subsequent to commit; this is what
# expire_on_commit=False allows
print(a1.data)
# for AsyncEngine created in function scope, close and
# clean-up pooled connections
await engine.dispose()
asyncio.run(async_main())
#调用同步方法 session.run_sync(sync_func)
#多对多关系的删除
1. 查询出要删除的多对多关系 user.hobbies
2. user.hobbies = [] 删除多对多关系
# 实际上直接删除中间表更便捷关联对象加载:
# 配置orm关系为lazy="noload",我认为非必要无需加载关联对象,lazy其他可使用的值为:'select'、'joined'、'subquery'、'selectin'、'raise',
parent = relationship('Parent', bacref='children', lazy='noload')
# 在查询中指定需要加载的关联对象
session.query(Parent).options(selectinload(Parent.children)).all()
详细文档:https://docs.sqlalchemy.org/en/20/orm/loading_relationships.html?highlight=lazy#sqlalchemy.orm.Load.lazyloadEvent 钩子:
from sqlalchemy.engine import Engine
from sqlalchemy.orm import Session
@event.listens_for(Engine, "before_execute")
def my_before_execute(
conn, clauseelement, multiparams, params, execution_options
):
print("before execute!")
@event.listens_for(Session, "after_commit")
def my_after_commit(session):
print("after commit!")
# 更多event节点见 ConnectionEvents类SQL 编译缓存:
engine = create_engine("postgresql://scott:tiger@localhost/test", query_cache_size=100)
#使用的内部缓存称为 LRUCache,DDL 构造通常不参与缓存,因为它们通常不会被重复第二次
# 自定义缓存
my_cache = {}
with engine.connect().execution_options(compiled_cache=my_cache) as conn:
conn.execute(table.select())Alembic 数据库迁移:
1. 安装:pip install alembic
2. 初始化:alembic init alembic
3. 修改配置:
alembic.ini配置文件 (你的数据库连接信息)
sqlalchemy.url = mysql+pymysql://root:admin@localhost/alembic_demo
env.py (保证你的model被加载到)
import os
import sys
from xxx import Base
# 把当前项目路径加入到path中
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
target_metadata = Base.metadata
4. 生成迁移文件:alembic revision --autogenerate -m "first commit"
5. 更新到数据库:alembic upgrade head最后不得不吐槽sqlalchemy的文档实在是太乱了,多个版本交错,期待2.0有所改善 官方文档地址:SQLAlchemy Documentation — SQLAlchemy 2.0 Documentation

















 1651
1651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









