






读者大概率都会遇到这样的情况:模型在训练数据上表现非常好,但无法准确预测测试数据。原因是模型过拟合了,解决此类问题的方法是正则化。
正则化有助于防止模型过度拟合,学习过程变得更加高效。有几个正则化工具:Early Stopping、dropout、权重初始化技术 (Weight Initialization Techniques) 和批量归一化 (Batch Normalization)。
在本文中,将详细探讨批量归一化,内容如下。
- 什么是批量归一化?
- 批量归一化的工作原理?
- 为什么批量归一化有效?
- 如何使用批量归一化?
- PyTorch 简单实现 Batch Normalization
什么是批量归一化?
在进入批量归一化 (Batch Normalization) 之前,让我们了解术语 “Normalization”。归一化是一种数据预处理工具,用于将数值数据调整为通用比例而不扭曲其形状。
通常,当我们将数据输入机器或深度学习算法时,倾向于将值更改为平衡的比例。规范化是为了确保模型可以适当地概括数据。
现在回到 Batch Normalization,这是一个通过在深度神经网络中添加额外层来使神经网络更快、更稳定的过程。新层对来自上一层的层的输入执行标准化和规范化操作。
那批量归一化中术语 “Batch” 是什么?典型的神经网络是使用一组称为 Batch 的输入数据集进行训练的。同样,批归一化中的归一化过程是分批进行的,而不是单个输入。
让我们通过一个例子来理解这一点,我们有一个深度神经网络,如下图所示。
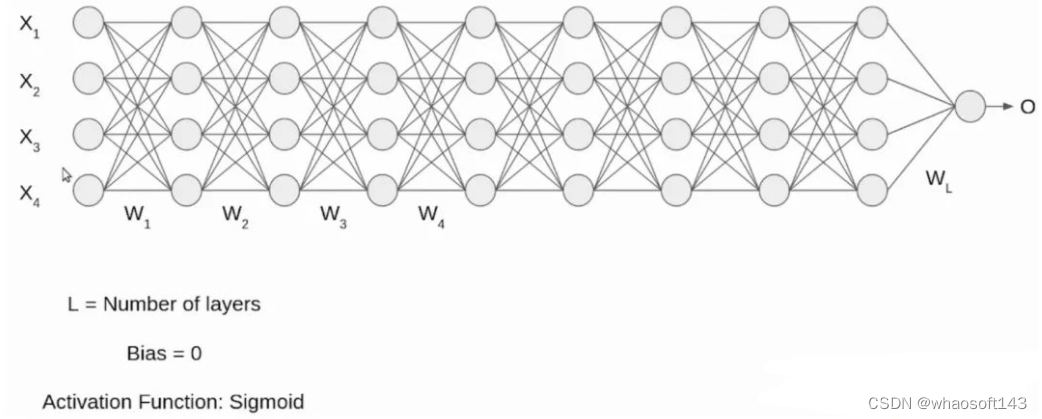
输入 X1、X2、X3、X4 是标准化形式,因为它们来自预处理阶段。当输入通过第一层时,输入 X 和权重矩阵 W 进行点积计算,再经过 sigmoid 函数。以此类推。
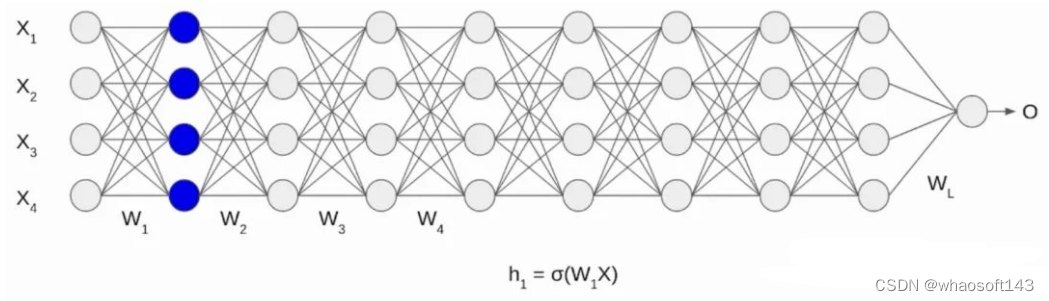
第一层计算方式应用到每一层,最后一层记录为 L,如图所示。
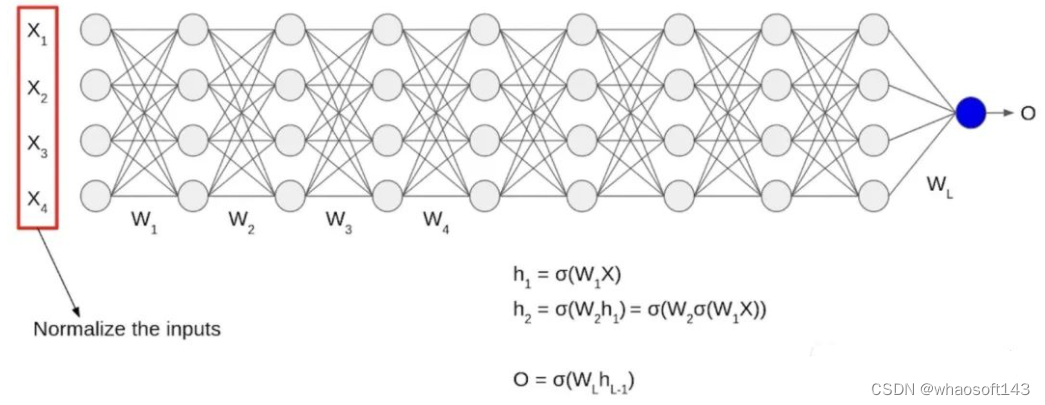
输入 X 随时间归一化,输出将不再处于同一比例。当数据经过多层神经网络并经过 L 个激活函数时,会导致数据发生内部协变量偏移(Internal Covariate Shift)。在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化,这一过程被称作 Internal Covariate Shift。
批量归一化的工作原理?
现在我们对为什么需要批量归一化有了一个清晰的认识,那么让我们了解它是如何工作的。这是一个两步过程。先将输入归一化,然后执行重新缩放和偏移。
输入的归一化

重新缩放与偏移
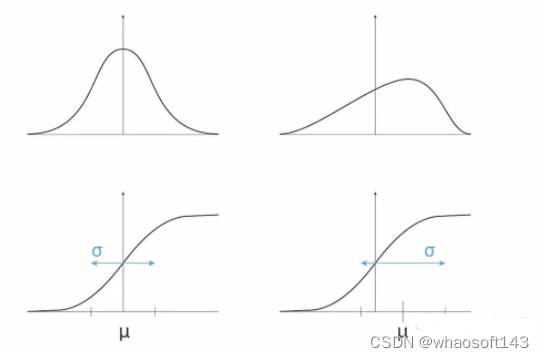
在最后的操作中,将对输入进行重新缩放和偏移。重新缩放参数 γ (gamma) 和偏移参数 β (beta)。
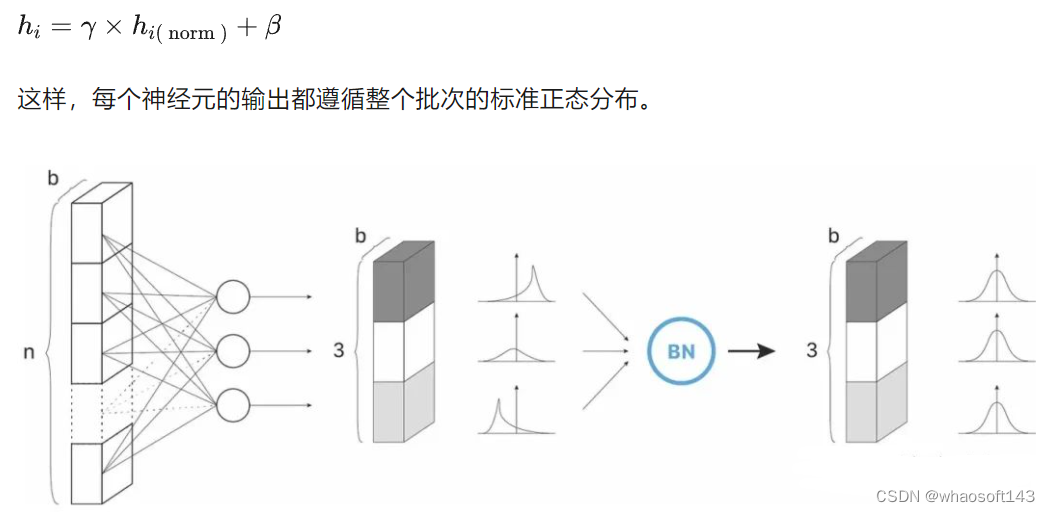
两个可训练参数 𝛾 和 𝛽 应用线性变换来计算层的输出,这样的步骤允许模型通过调整这两个参数来为每个隐藏层选择最佳分布:
- 𝛾 允许调整标准偏差;
- 𝛽 允许调整偏差,在右侧或左侧移动曲线。
为什么批量归一化有效?
在大多数情况下,Batch Normalization 可以提高深度学习模型的性能。那太棒了,但我们想知道黑匣子内部到底发生了什么。在深入讨论之前,我们将看到以下内容:
- 原始论文 【1】 假设 BN 有效性是减少了内部协变量偏移(ICS)。一篇论文 [2] 驳斥了这一假设。
- 另一种假设更谨慎地取代了第一种假设:BN 减轻了训练期间各层之间的相互依赖性。
- 麻省理工学院最近的一篇论文【2】强调了 BN 对优化过程平滑度的影响,使训练更容易。
如果我们要训练一个分类器,判断图片中是否有猫,假设我只有橘猫图片来训练,测试的图片确实是无毛猫。

从模型的角度来看,训练图像在统计上与测试图像差异太大,会有一个协变量偏移。
如果输入信号中存在巨大的协变量偏移,优化器将难以很好地泛化。相反,如果输入信号始终服从标准正态分布,优化器将更容易泛化。考虑到这一点,【1】 的作者应用了对隐藏层中的信号进行归一化的策略。他们假设强制 (𝜇 = 0, σ = 1) 中间信号分布将有助于网络在“概念”级别的特征泛化。
但是,我们并不总是希望隐藏单元中的标准正态分布。它会降低模型的代表性。为了解决这个问题,他们添加了两个可训练参数 𝛽 和 𝛾 ,允许优化器为特定任务选择最佳均值(使用 𝛽 )和标准差(使用 𝛾 )。
在论文【2】的实验中,训练了三个 VGG 网络(在 CIFAR-10 上):
- 第一个没有任何 BN 层;
- 第二个确实有 BN 层;
- 第三个与第二个类似,除了他们在激活之前在隐藏单元内明确添加了一些 ICS_distrib (通过添加随机偏差和方差)。
他们测量了每个模型达到的准确度,以及迭代时分布值的演变。这是他们得到的:
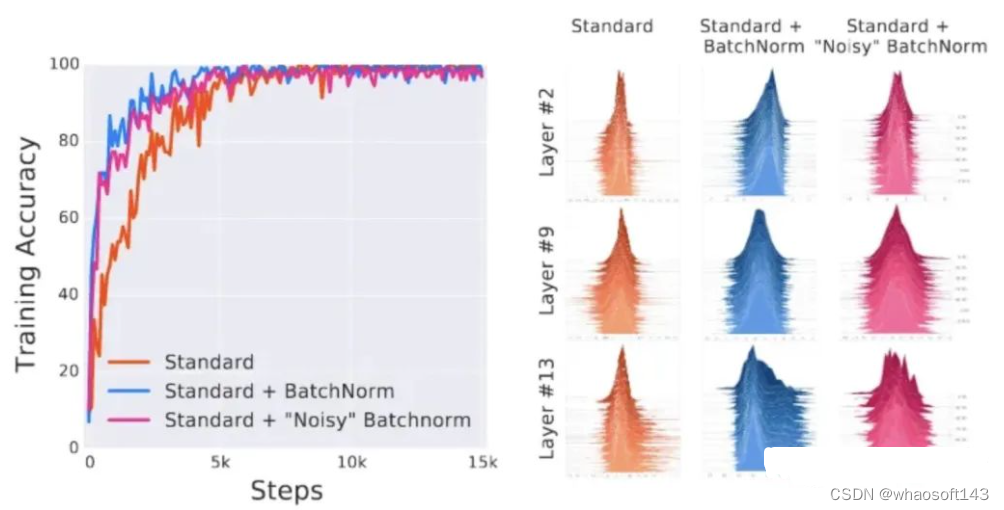
正如预期的那样,我们可以看到第三个网络具有非常高的 ICS。然而,噪声网络的训练速度仍然比标准网络快。其达到的性能可与标准 BN 网络获得的性能相媲美。该结果表明BN 有效性与 ICS_distrib 可能无关。哎呀!
我们不应该过快地抛弃 ICS 理论:如果 BN 有效性不是来自 ICS_distrib,它可能与 ICS 的另一个定义有关。[2] 的作者提出了 ICS 的另一个定义:
We define the internal covariate shift from an optimization perspective as the difference between the gradient computed on a hidden layer k after backpropagating the error L(X)_it, and the gradient computed on the same layer k from the loss L(X)_it+1 computed after the iteration = it update of weights.
看起来好复杂,我们简单的理解一下,这个定义更多地关注梯度而不是隐藏层输入分布,让我们了解 ICS 如何对底层优化问题产生影响。
在下一个实验中,作者记录使用和不使用 BN 层对损失、梯度的影响。让我们来看看结果:
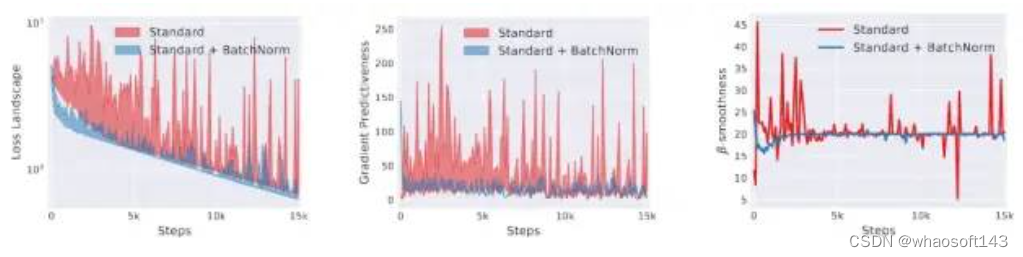
我们可以清楚地看到,使用 BN 层的优化过程更加平滑。
我们终于有了可以用来解释 BN 有效性的结果:BN 层以某种方式使优化更加平滑。这使得优化器的工作更容易:我们可以定义更大的学习率,而不会受到梯度消失(权重卡在突然的平面上)或梯度爆炸(权重突然下降到局部最小值)的影响。
如何使用批量归一化?
之前,BN 层位于非线性函数之前,这与【1】的作者当时的目标和假设是一致的。一些实验表明,将 BN 层放置在非线性函数之后会产生更好的结果【6】。

PyTorch:torch.nn.BatchNorm1d,torch.nn.BatchNorm2d,torch.nn.BatchNorm3d。
Tensorflow/Keras:tf.nn.batch_normalization,tf.keras.layers.BatchNormalization。
torch.nn.BatchNorm2d 示例:
参数如下:
1.num_features:特征的数量,输入一般为
2.eps:分母中添加的一个常数,为了计算的稳定性,默认为 1e-5;
3.momentum:用于计算 running_mean 和 running_var,默认为 0.1;
4.affine:当为 True 时,会给定可以学习的系数矩阵 gamma 和 beta;
5.track_running_stats:一个布尔值,当设置为 True 时,模型追踪 running_mean 和 running_variance,当设置为 False 时,模型不跟踪统计信息,并在训练和测试时都使用测试数据的均值和方差来代替,默认为 True。
使用 PyTorch 简单实现 Batch Normalization
- 使用 Pytorch 简单实现 BN(应用于 MLP,只有三层隐藏层);
- 在 MNIST 数据集(一个小的数据集)上测试。
Kaggle 练习网址
复制链接,在 kaggle 平台即可练习:https://www.kaggle.com/code/zymzym/bn-pytorch
- 导入库和设置超参数
- 导入 MINST 数据集,本地没有便会下载.
- 复现 BN,遵循一下公式,不熟悉的读者请查看前面的工作原理:
- 跟踪记录模型的状态。
- 构建 2 个三层隐藏层的网络结构,唯一区别是是否带有 BN。
- 建立训练和测试循环。
- 绘图展示 BN 层在评价指标和损失的影响。
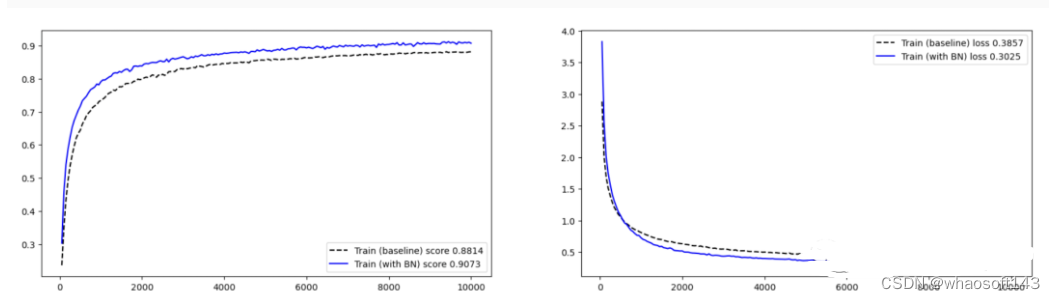
从实验结果来看,有 BN 的网络,训练的准确率高,收敛更快!















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









