







一,什么是分区表以及作用
数据分区的概念以及存在很久了,通常使用分区来水平分散压力,将数据从物理上移到和使用最频繁的用户更近的地方,以及实现其目的。 hive中有分区表的概念,我们可以看到分区具重要性能优势,而且分区表还可以将数据以一种符合逻辑的方式进行组织,比如分层存储
分区表分别有静态分区和动态分区
二、 静态分区
1,创建静态分区格式:
create table employees ( name string, salary float, subordinated array<string>, deductions map<string,float>, address struct<street:string,city:string,state:string,zip:int> ) partitioned by (country string,state string) row format delimited fields terminated by "\t" collection items terminated by "," map keys terminated by ":" lines terminated by "\n" stored as textfile;
创建成果后发现他的存储路径和普通的内部表的路径是一样的而且多了分区表的字段,因为我们创建的分区表并没内容,事实上,除非需要优化查询性能,否则实现表的用户不需要关系"字段是否是分区字段"
2,然后我们添加分区表
alter table employees add partition (country="china",state="Asia");查看分区表信息: show partitions employees;
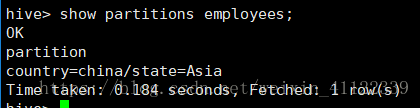
hdfs上的路径:/user/hive/warehouse/zxz.db/employees/country=china/state=Asia 他们都是以目录及子目录形式存储的
3,插入数据:
格式: INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row …]; 格式2:(推荐使用) load data local inpath '/home/had/data1.txt' into table employees partition (country =china,state=Asia)4,利用分区表查询:(一般分区表都是利用where语句查询的)
5,CTAS语句和like
创建表,携带数据 create table employees1 as select * from employees1 创建表,携带表结构 create table employees2 like employees6,外部分区表:
外部表同样可以使用分区,事实上,用户会发现,只是管理大型生产数据集最常见的情况,这种结合给用户提供一个和其他工具共享数据的方式,同时也可以优化查询性能
create external table employees_ex ( name string, salary float, subordinated array<string>, deductions map<string,float>, address struct<street:string,city:string,state:string,zip:int> ) partitioned by (country string,state string) row format delimited fields terminated by "\t" collection items terminated by "," map keys terminated by ":" lines terminated by "\n" stored as textfile; location "/user/had/data/" //他其实和普通的静态分区表一样就是多了一个external关键字这样我们就可以把数据路径改变而不影响数据的丢失,这是内部分区表远远不能做的事情:
1,(因为我们创建的是外部表)所有我们可以把表数据放到hdfs上的随便一个地方这里自动数据加载到/user/had/data/下(当然我们之前在外部表上指定了路径) load data local inpath '/home/had/data.txt' into table employees_ex partition (country="china",state="Asia"); 2,如果我们加载的数据要分离一些旧数据的时候就可以hadoop的distcp命令来copy数据到某个路径 hadoop distcp /user/had/data/country=china/state=Asia /user/had/data_old/country=china/state=Asia 3,修改表,把移走的数据的路径在hive里修改 alter table employees partition(country="china",state="Asia") set location '/user/had/data_old/country=china/state=Asia' 4,使用hdfs的rm命令删除之前路径的数据 hdfs dfs -rmr /user/had/data/country=china/state=Asia 这样我们就完成一次数据迁移 如果觉得突然忘记了数据的位置使用使用下面的方式查看 describe extend employees_ex partition (country="china",state="Asia");7,删除分区表
alter table employees drop partition(country="china",state="Asia");
8,众多的修改语句
1,把一个分区打包成一个har包 alter table employees archive partition (country="china",state="Asia") 2, 把一个分区har包还原成原来的分区 alter table employees unarchive partition (country="china",state="Asia") 3, 保护分区防止被删除 alter table employees partition (country="china",state="Asia") enable no_drop 4,保护分区防止被查询 alter table employees partition (country="china",state="Asia") enable offline 5,允许分区删除和查询 alter table employees partition (country="china",state="Asia") disable no_drop alter table employees partition (country="china",state="Asia") disable offline9,通过查询语句向表中插入数据
insert overwrite/into table copy_employees partition (country="china",state="Asia") select * from employees es where es.country="china" and es.state ="Asia"


三、动态分区:
为什么要使用动态分区呢,我们举个例子,假如中国有50个省,每个省有50个市,每个市都有100个区,那我们都要使用静态分区要使用多久才能搞完。所有我们要使用动态分区。
动态分区默认是没有开启。开启后默认是以严格模式执行的,在这种模式下需要至少一个分区字段是静态的。这有助于阻止因设计错误导致导致查询差生大量的分区。列如:用户可能错误使用时间戳作为分区表字段。然后导致每秒都对应一个分区!这样我们也可以采用相应的措施:
关闭严格分区模式 动态分区模式时是严格模式,也就是至少有一个静态分区。 set hive.exec.dynamic.partition.mode=nonstrict //分区模式,默认nostrict set hive.exec.dynamic.partition=true //开启动态分区,默认true set hive.exec.max.dynamic.partitions=1000 //最大动态分区数,默认10001,创建一个普通动态分区表:
create table if not exists zxz_5( name string, nid int, phone string, ntime date ) partitioned by (year int,month int) row format delimited fields terminated by "|" lines terminated by "\n" stored as textfile;现在还看不出来有什么不一样
insert overwrite table zxz_5 partition (year,month) select name,nid,phone,ntime,year(ntime) as year ,month(ntime) as month from zxz_dy; zxz_5这个表里面存放着数据。 我们利用year,和month函数来获取ntime列的年和月来作为分区,这个是靠我们查询到数据来分区是不是很舒服来我们看看他自动分区的格式
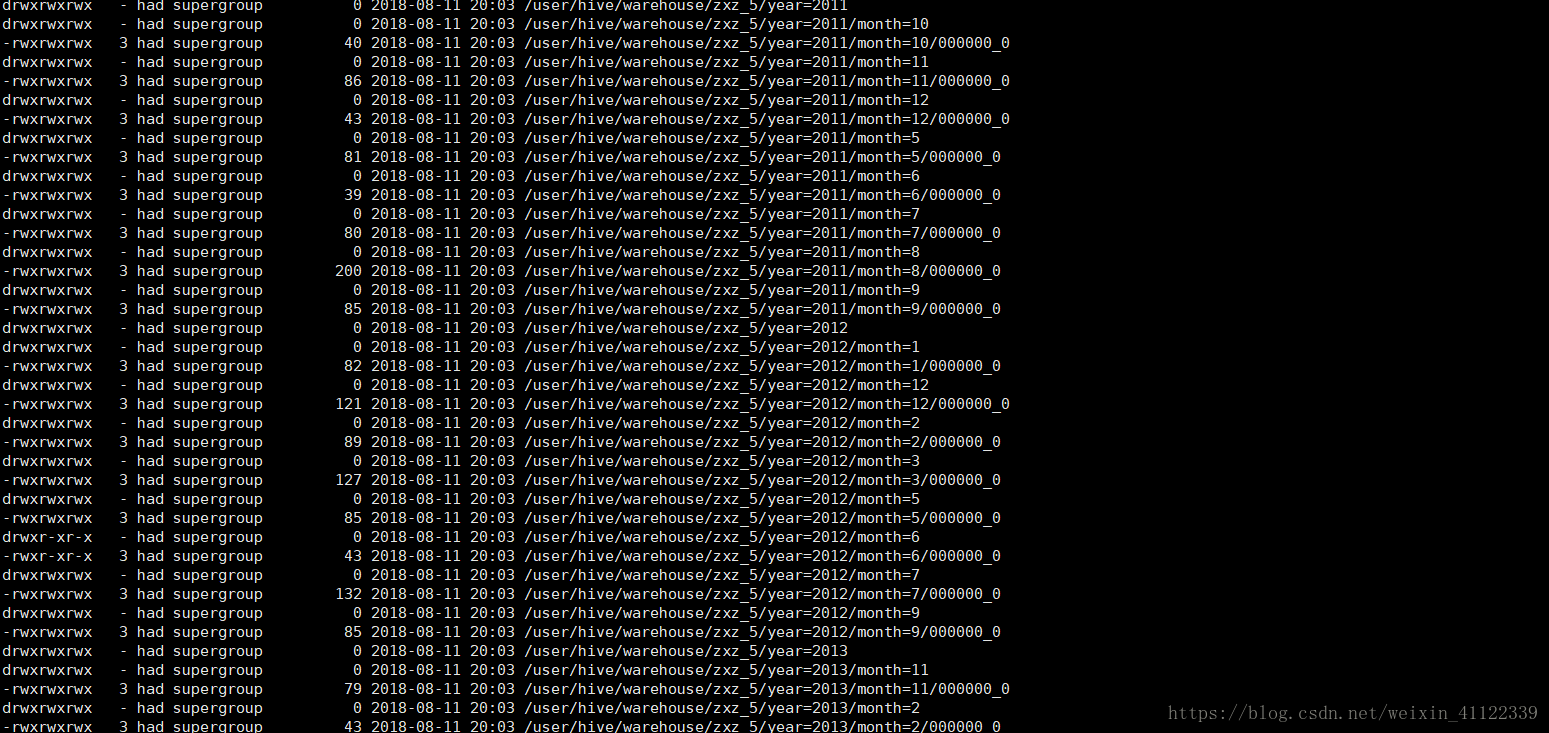

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









