







介绍XML语法及应用
1.XML基础知识
1.1什么是XML语言
XML 被设计用来传输和存储数据。
HTML 被设计用来显示数据。
XML 指可扩展标记语言(eXtensible Markup Language)。
可扩展标记语言(英语:Extensible Markup Language,简称:XML)是一种标记语言,是从标准通用标记语言(SGML)中简化修改出来的。它主要用到的有可扩展标记语言、可扩展样式语言(XSL)、XBRL和XPath等。
1.2 XML 和 HTML 之间的差异
XML 不是 HTML 的替代。
XML 和 HTML 为不同的目的而设计:
XML 被设计用来传输和存储数据,其焦点是数据的内容。
HTML 被设计用来显示数据,其焦点是数据的外观。
HTML 旨在显示信息,而 XML 旨在传输信息。
1.3 XML 用途
XML 应用于 Web 开发的许多方面,常用于简化数据的存储和共享。
- XML 把数据从 HTML 分离
如果您需要在 HTML 文档中显示动态数据,那么每当数据改变时将花费大量的时间来编辑 HTML。
通过 XML,数据能够存储在独立的 XML 文件中。这样您就可以专注于使用 HTML/CSS 进行显示和布局,并确保修改底层数据不再需要对 HTML 进行任何的改变。通过使用几行 JavaScript 代码,您就可以读取一个外部 XML 文件,并更新您的网页的数据内容。 - XML 简化数据共享
在真实的世界中,计算机系统和数据使用不兼容的格式来存储数据。
XML 数据以纯文本格式进行存储,因此提供了一种独立于软件和硬件的数据存储方法。
这让创建不同应用程序可以共享的数据变得更加容易。 - XML 简化数据传输
对开发人员来说,其中一项最费时的挑战一直是在互联网上的不兼容系统之间交换数据。
由于可以通过各种不兼容的应用程序来读取数据,以 XML 交换数据降低了这种复杂性。
2.XML语法
2.1基础语法
1.XML 声明文件的可选部分,如果存在需要放在文档的第一行,备注版本和语言【可选】
<?xml version="1.0" encoding="utf-8"?>
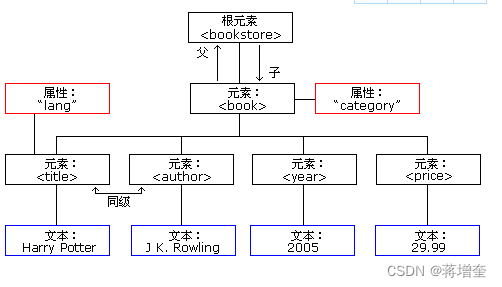
2.XML必须有个并且只有一个根元素,把所有都包围起来
<person>
..........
</person>
3.XML是一个树状结构,支持层层嵌套
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
4.XML的一个标签必须有对应的关闭开关
5.XML的元素属性必须加引号
错误:<tang>ddddd 正确:<tang>ddd</tang>
错误:<tag date=200-12-01>fff</tag> 正确:<tag date="2002-12-01">fff</tag>
6.特殊字符转义
在 XML 中,只有字符 “<” 和 “&” 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。
转义符号:
< < 小于
> > 大于
& & &符号
' ' 单引号
" " 双引号
<!-- 错误:-->
<sql> select * from test where id<2</sql>
正确
<sql> select * from test where id < 2</sql>
如果不想使用转义,则可以加如下格式忽略:< ! [ CDATA [忽略检查的文本]]>
<sql> select * from test where id <![ CDATA [ <2 ]]></sql>
7.XML注释
<!-- This is a comment -->
2.2XML元素
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。
一个元素可以包含:
- 其他元素
- 文本
- 属性
- 或混合以上所有…
<bookstore>
<book category="CHILDREN">
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title>Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
在上面的实例中,<bookstore> 和 <book> 都有 元素内容,
因为他们包含其他元素。<book> 元素也有属性(category="CHILDREN")。
<title>、<author>、<year> 和 <price> 有文本内容
,因为他们包含文本。
XML 元素必须遵循以下命名规则:
名称可以包含字母、数字以及其他的字符
名称不能以数字或者标点符号开始
名称不能以字母 xml(或者 XML、Xml 等等)开始
名称不能包含空格
可使用任何名称,没有保留的字词。
2.3 XML属性
属性通常提供不属于数据组成部分的信息。在下面的实例中,文件类型与数据无关,但是对需要处理这个元素的软件来说却很重要:
<file type="gif">computer.gif</file>
因使用属性而引起的一些问题:
- 属性不能包含多个值(元素可以)
- 属性不能包含树结构(元素可以)
- 属性不容易扩展(为未来的变化)
2.4XML命名空间
XML 命名空间提供避免元素命名冲突的方法,我们看一个例子
a.xml
<table>
<tr>
<td>Apples</td>
<td>Bananas</td>
</tr>
</table>
b.xml
<table>
<name>African Coffee Table</name>
<width>80</width>
<length>120</length>
</table>
假如这两个 XML 文档被一起使用,由于两个文档都包含带有不同内容和定义的
元素,就会发生命名冲突。XML 解析器无法确定如何处理这类冲突。XML解决方案:
在 XML 中的命名冲突可以通过使用名称前缀从而容易地避免。
该 XML 携带某个 HTML 表格和某件家具的信息:
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
这个前缀,就用命名空间来展示
当命名空间被定义在元素的开始标签中时,所有带有相同前缀的子元素都会与同一个命名空间相关联。命名空间,可以在他们被使用的元素中或者在 XML 根元素中声明:
语法:
xmlns:前缀名=“…”
<root xmlns:h="http://www.w3.org/TR/html4/"
xmlns:f="http://www.w3cschool.cc/furniture">
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
</root>
默认命名空间
我们取消掉 :前缀,就变成默认的命名空间,默认命名空间,在xml里面就不用使用 前缀: 来标注元素了
语法:xmlns=“namespaceURI”
<root xmlns="http://www.w3.org/TR/html4/"
xmlns:f="http://www.w3cschool.cc/furniture">
<table>
<tr>
<td>Apples</h:td>
<td>Bananas</h:td>
</tr>
</table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
</root>
在实战中,如果一个xml里有多个命名空间,我们一半把使用得最多得那个,作为默认命名空间
3.XML验证
3.1xml语法验证
如果XML语法错误,解析器会自动验证
- XML 文档必须有一个根元素
- XML元素都必须有一个关闭标签
- XML 标签对大小写敏感
- XML 元素必须被正确的嵌套
- XML 属性值必须加引号
3.2自定义验证
就是希望写一个xml需要遵循哪些要求,如有多少元素,元素的结构怎么样,元素属性和数据类型是哪些,这里要用到XML自定义验证,XML提供 DTD和Schema两种语法机制
3.2.1 XML DTD
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE note SYSTEM "Note.dtd">
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
Note.dtd
<!DOCTYPE note
[
<!ELEMENT note (to,from,heading,body)> <!--有哪些元素-->
<!ELEMENT to (#PCDATA)> <!--to 元素内容是可解析的内容-->
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
3.2.2 XML Schema
W3C 支持一种基于 XML 的 DTD 代替者,它名为 XML Schema,Schema比DTD更有扩展性
note.xsd文件:
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3schools.com"
xmlns="http://www.w3schools.com"
elementFormDefault="qualified">
<xs:element name="note">
<xs:complexType><!--note是一个复合类型,还有子元素-->
<xs:sequence> <!--元素必须按照顺序出现-->
<xs:element name="to" type="xs:string"/> <!--子元素名,和数据类型-->
<xs:element name="from" type="xs:string"/>
<xs:element name="heading" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
xml里面引用
<?xml version="1.0"?>
<note
xmlns="http://www.w3schools.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3schools.com note.xsd">
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
上述只简单介绍了dtd和schema,了解其基本意思,更多语法可查看schema相关的学习资源,在schema的基础扩展出WSDL语言,描述XML接口,是SOA技术的基础
3.2.3PCDATA和CDATA区别
XML 文档中的所有文本均会被解析器解析。只有 CDATA 区段中的文本会被解析器忽略。
默认情况被解析器解析的文本就是PCDATA
术语 CDATA 是不应该由 XML 解析器解析的文本数据。像 “<” 和 “&” 字符在 XML 元素中都是非法的。
“<” 会产生错误,因为解析器会把该字符解释为新元素的开始。
“&” 会产生错误,因为解析器会把该字符解释为字符实体的开始。
某些文本,比如 JavaScript sql代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。CDATA 部分中的所有内容都会被解析器忽略。
CDATA 部分由 “<![CDATA[" 开始,由 "]]>” 结束:
eg:
<name><first>Bill</first><last>Gates</last></name>
里面内容是要被解析的,最终效果如下:
<name>
<first>Bill</first>
<last>Gates</last>
</name>
eg:
< script>里面的<我们不希望被解析,则可使用 “<![CDATA[" 开始,由 "]]>” 包围起来
<script>
<![CDATA[
function matchwo(a,b)
{
if (a < b && a < 0) then
{
return 1;
}
else
{
return 0;
}
}
]]>
</script>
3.2.4 参考
spring的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans
<!-- 默认命名空间 -->
xmlns="http://www.springframework.org/schema/beans"
<!--带后缀的空间-->
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jee="http://www.springframework.org/schema/jee"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:context="http://www.springframework.org/schema/context"
<!--schema引用-->
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.2.xsd
http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-3.2.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.2.xsd"
default-lazy-init="true">
4.xml解析
4.1准备工作
用servler发布一个xml报文服务
@WebServlet(
urlPatterns = {"/myxml"}
)
public class XmlServlet extends HttpServlet {
public XmlServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/xml");
response.setHeader("Cache-Control", "no-cache");
response.setCharacterEncoding("utf-8");
StringBuffer returnXML = null;
int keyInt = true;
returnXML = new StringBuffer("<?xml version=\"1.0\" encoding=\"utf-8\"?>\n");
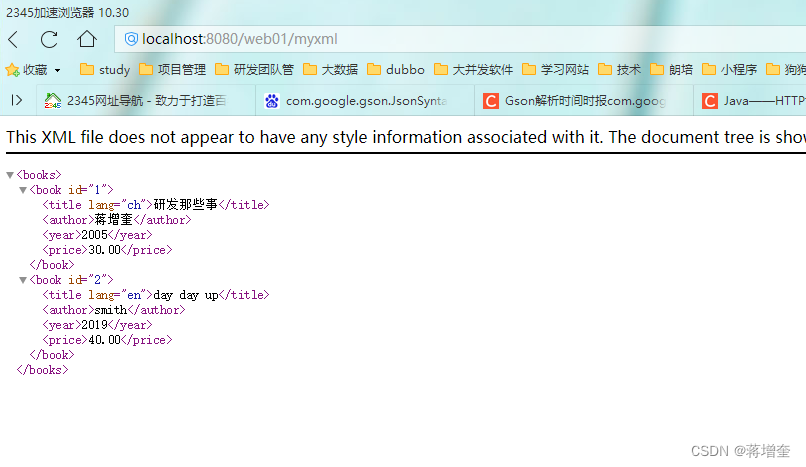
returnXML.append("<books> \n");
returnXML.append("<book id=\"1\"> \n");
returnXML.append(" <title lang=\"ch\">研发那些事</title>\n");
returnXML.append(" <author>蒋增奎</author>\n");
returnXML.append("<year>2005</year>\n");
returnXML.append(" <price>30.00</price>\n");
returnXML.append(" </book>\n");
returnXML.append("<book id=\"2\"> \n");
returnXML.append(" <title lang=\"en\">day day up</title>\n");
returnXML.append(" <author>smith</author>\n");
returnXML.append("<year>2019</year>\n");
returnXML.append(" <price>40.00</price>\n");
returnXML.append(" </book>\n");
returnXML.append("</books> \n");
PrintWriter out = response.getWriter();
try {
out.println(returnXML);
} finally {
out.close();
}
}
}
访问http://localhost:8080/web01/myxml
4.2 javascript解析
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>xml解析</title>
<script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js">
</script>
<script>
// 读取xml文件
function loadXMLDoc(filename) {
var xhttp;
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else {
// 针对老版本IE浏览器
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET", filename, false);
// try {
// xhttp.responseType = "msxml-document";
// } catch (err) {}
xhttp.send("");
return xhttp.responseXML;
}
// 解析xml文件
function parserXML(xml) {
var xmlDoc = loadXMLDoc(xml);
var books = xmlDoc.getElementsByTagName("book");
var ret="";
for (var i = 0; i < books.length; i++) {
var book = books[i];
var title = book.getElementsByTagName("title")[0].firstChild.nodeValue;
var author = book.getElementsByTagName("author")[0].firstChild.nodeValue;
var price = book.getElementsByTagName("price")[0].firstChild.nodeValue;
var year = book.getElementsByTagName("year")[0].firstChild.nodeValue;
console.log("Title: " + title + ", Author: " + author + ", price: " + price + ", Year: " + year);
ret+="<tr><td>"+title+"</td><td>"+author+"</td><td>"+price+"</td><td>"+year+"</td></tr>";
}
return ret;
}
// 调用解析xml文件的函数
//parserXML("books.xml");
function dd(){
// $("table").append("<tr><td>研发那些事</td><td>蒋增奎</td><td>40</td></tr>");
var ret= parserXML("http://localhost:8080/web01/myxml");
$("table").append(ret);
}
</script>
</head>
<body>
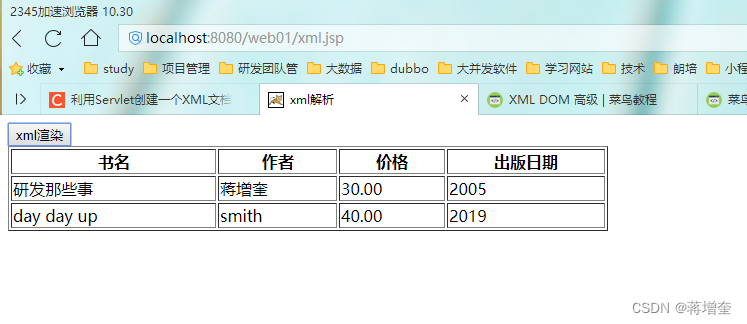
<input type="button" value="xml渲染" onclick="dd()">
<table width="600" border="1">
<thead>
<tr><th>书名</th><th>作者</th><th>价格</th><th>出版日期</th></tr>
</thead>
<tbody>
</tbody>
</table>
</body>
</html>
效果:
4.3 java解析
这里用到dom4j框架,细节可参考java三方框架
package com.jsoft.json;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Iterator;
/**
* @class: com.jsoft.json.XmlParse
* @description:
* @author: jiangzengkui
* @company: 教育家
* @create: 2023-12-11 23:09
*/
public class XmlParse {
/**
* 获得一个连接的源码
* @param httpUrl
* @return
*/
public static String doGet(String httpUrl) {
InputStream inputStream = null ;
StringBuffer result = null;
BufferedReader bufferedReader = null ;
HttpURLConnection httpURLConnection = null ;
try {
//初始化URL,传入想访问的地址
URL url = new URL(httpUrl);
//打开URL连接,并新建HttpURLConnection对象
httpURLConnection = (HttpURLConnection)url.openConnection();
//设置请求ban
httpURLConnection.setRequestMethod("GET");
httpURLConnection.setConnectTimeout(15000);
httpURLConnection.setReadTimeout(15000);
result = new StringBuffer() ;
httpURLConnection.connect();
if(httpURLConnection.getResponseCode() == 200) {
inputStream = httpURLConnection.getInputStream();
String inputLine;
if(inputStream != null) {
bufferedReader = new BufferedReader(new InputStreamReader(inputStream,"UTF-8"));
while((inputLine = bufferedReader.readLine()) != null) {
result = result.append(inputLine);
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e2) {
e2.printStackTrace();
}
}
if(inputStream != null) {
try {
inputStream.close();
} catch (IOException e2) {
e2.printStackTrace();
}
}
httpURLConnection.disconnect();
}
return result.toString();
}
public static void main(String arg[]) throws DocumentException {
String resultString = doGet("http://localhost:8080/web01/myxml");
System.out.println(resultString);
Document document = DocumentHelper.parseText(resultString);
Element root = document.getRootElement();
for (Iterator i = root.elementIterator(); i.hasNext();) {
Element element = (Element) i.next();
String title = element.elementText("title");
String author = element.elementText("author");
String year = element.elementText("year");
String price = element.elementText("price");
System.out.println("title="+title+";author="+author+";year="+year+";price="+price);
}
}
}
效果
















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









