







目标
《中华药典(第一部)》收录了大量药材和饮片、植物油脂和提取物、成方制剂和单味制剂等药材信息,以类似字典的形式进行组织。内容示例见下图:

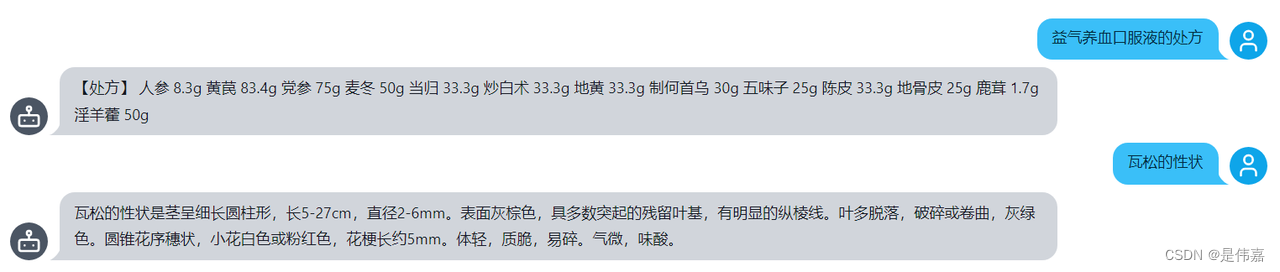
大语言模型根据《中华药典》文档,对用户输入的有关中华药典的问题进行回答。典型问题如“益气养血口服液的处方”、“瓦松的性状”等,都是询问药名、品名的某类特征。
效果示例
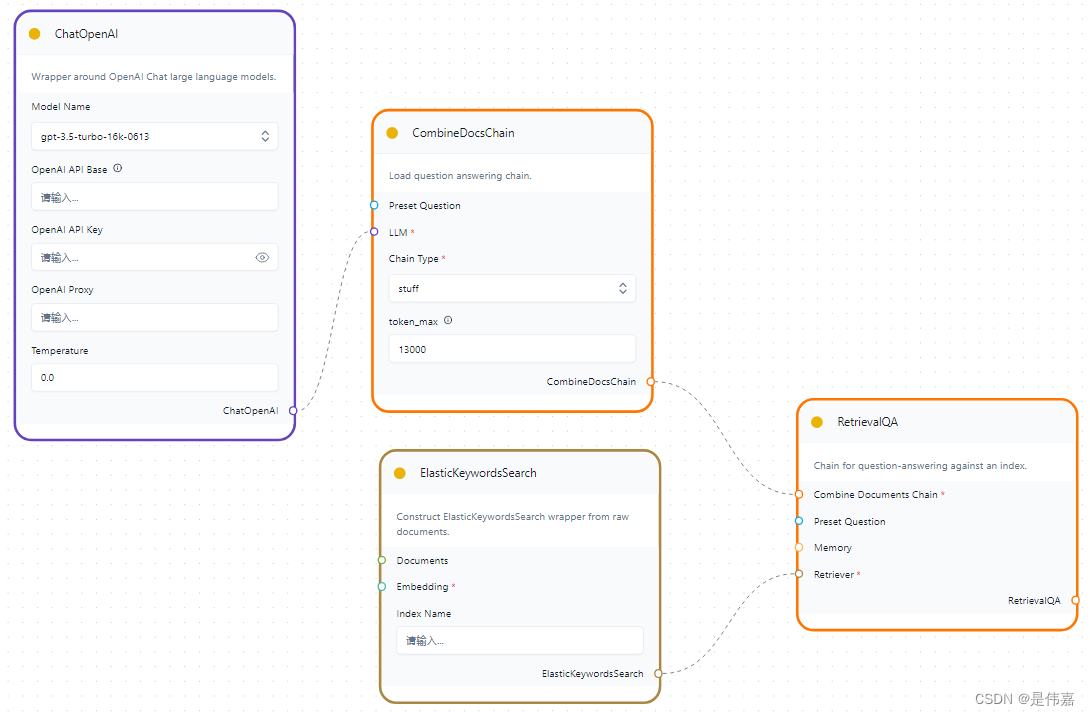
构建思路
- 需要对文本内容进行回答,因此选择语言模型ChatOpenAI组件(或其他语言模型组件)、RetrievalQA组件、CombineDocsChain组件;
- 因为中华药典中的内容很多都是专有名词,药品药材的名称是最关键的信息,因此相比向量语义搜索,通过关键词的搜索找到相关文本段落会更有效,因此选择ElasticKeywordsSearch组件;
- 连接示例
- 工作原理
用户输入的问题由ElasticKeywordsSearch组件对用户的query进行分词,然后通过这些词进行关键词匹配,返回匹配关键词的文本段落,再把问题与这些文本段落一同传递给大语言模型,由大语言模型输出答案。我们内部实验,在该场景下使用向量搜索最终回答的准确率不到50%,使用ES关键词搜索可以将准确率提升到85%以上。
- 组件参数设置
- ChatOpenAI
- Model Name:选择gpt-3.5-turbo-16k-0613,可以换为任意模型
- OpenAI API Key:API接口密钥
- OpenAI API Base/OpenAI Proxy:服务的地址,填写其中之一即可(如果是自己代理的国内的地址则填写OpenAI Proxy参数)
- CombineDocsChain
- Chain Type:选择“stuff”,原因详见CombineDocsChain
- token_max:“13000”,即对传给大模型的文本长度做限制,不能超过13000个token,详见CombineDocsChain
- ElasticKeywordsSearch
- Index Name:要搜索的数据库
- Search Kwargs:关键词搜索匹配的方式,参数的含义见ElasticKeywordsSearch
- ChatOpenAI
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









