






论文笔记
题目
Mixture-of-Agents Enhances Large Language Model Capabilities
作者
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, James Zou
论文摘要
近年来,大型语言模型(LLMs)在自然语言理解和生成任务方面取得了显著进展。然而,单个模型在规模和训练数据上存在固有的限制,进一步扩展这些模型的成本非常高。因此,如何利用多个LLMs的集体优势成为一个有趣的研究方向。本文提出了一种新方法——代理混合(MoA),通过构建一个分层的MoA架构,每层包含多个LLM代理,每个代理在生成响应时参考前一层代理的输出。MoA模型在AlpacaEval 2.0、MT-Bench和FLASK等基准测试中表现优异,超越了GPT-4 Omni。例如,使用仅开源LLMs的MoA在AlpacaEval 2.0上得分为65.1%,相比GPT-4 Omni的57.5%有显著提高。
研究动机和背景
LLMs在自然语言处理任务中展示了强大的能力,但个别模型在规模和数据量上存在限制,扩展成本高昂。不同LLMs在任务方面具有独特优势,例如一些模型在复杂指令执行方面表现出色,而另一些则在代码生成方面更为擅长。本文探讨了多个LLMs是否可以协同合作以创建更强大和健壮的模型。
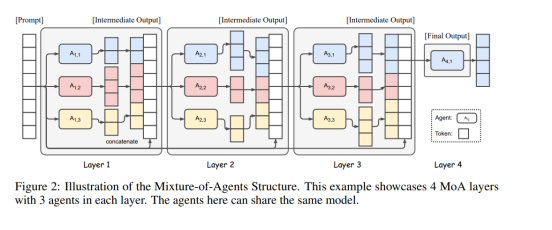
MoA方法
本文提出了代理混合(MoA)方法,利用多个LLMs的集体优势来提高生成质量。MoA结构分为多个层,每层包含多个代理。初始层的代理生成响应,随后层的代理基于前一层的输出进行进一步优化,直到生成更为完善的响应。关键在于选择适当的LLMs用于每一层,以性能指标和多样性为主要标准,确保模型输出的高质量。
实验结果
在AlpacaEval 2.0、MT-Bench和FLASK基准测试上的实验表明,MoA方法显著提升了模型的性能。在AlpacaEval 2.0上,MoA方法实现了65.1%的得分,比之前最佳的GPT-4 Omni提高了7.6%。在MT-Bench和FLASK测试中,尽管单个模型的改进较小,MoA方法仍然保持了领先地位,进一步验证了多模型协作的有效性。
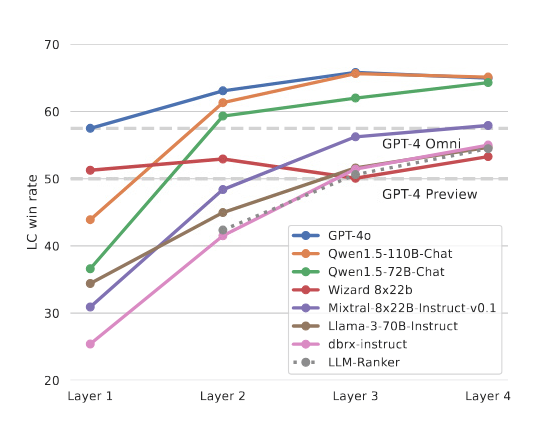
结论
本文提出的代理混合(MoA)方法通过多层次、多模型的协作显著提升了LLMs的输出质量。实验结果证明,利用不同模型的多样性和协作性,可以超越单一模型的性能。未来的研究可以进一步优化MoA架构,探索其在不同任务中的潜力。
通过这种方法,LLMs的性能得到了显著提升,展示了集体合作在自然语言处理中的巨大潜力。
代码实现
关键问题回答
论文目标
提出一种名为 Mixture-of-Agents (MoA) 的方法,通过集成多个 LLMs 来提升生成质量。
新颖性
- 发现 LLMs 在协作时能生成更高质量的响应。
- 提出了一个新的框架 MoA,利用多个 LLMs 的协作能力。
假设
LLMs 在参考其他模型的输出时,能够生成更高质量的响应。
相关研究
提到了 LLM 推理和模型集成方面的最新研究,包括 Chain of Thought (CoT)、多模型输出重排序和多代理协作等方法。
关键解决方案
MoA 架构:通过多个层次的 LLM 代理,每层生成响应并提供给下一层以进行进一步优化和整合。
实验设计
评估模型在 AlpacaEval 2.0、MT-Bench 和 FLASK 基准测试中的表现,分析 MoA 方法的有效性。
数据集
AlpacaEval 2.0、MT-Bench、FLASK 基准测试数据集。
开源代码
提供了开源代码: https://github.com/togethercomputer/moa
假设验证
通过实验证明 LLMs 在协作时能生成更高质量的响应,并且 MoA 在多个基准测试中表现优异。
贡献
- 提出了一种新框架 MoA。
- 发现了 LLMs 的协作性现象。
- 在多个基准测试中实现了新的性能记录。
未来工作
进一步优化 MoA 架构,探索分块聚合以降低响应时间。















 4429
4429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









