







在数字化时代,个性化内容的创造已成为趋势。最近,一项名为MoA(Mixture-of-Attention)的新技术在个性化图像生成领域取得了显著进展。这项由Snap Inc.团队开发的架构,不仅提升了图像生成的个性化水平,还保持了原始模型的强大功能。本文将深入探讨MoA的方法论、实验成果及其应用前景。

MoA架构如何实现个性化图像生成

在个性化图像生成领域,MoA(Mixture-of-Attention)架构带来了一种创新的方法,它通过精心设计的注意力机制,实现了个性化内容的生成,同时保留了原始模型的生成能力。以下是MoA方法的详细解析:
Mixture-of-Attention (MoA) 层
MoA层是MoA架构的核心,它扩展了传统的注意力机制,通过引入多个注意力块(即“专家”),并由一个路由网络软性地结合这些专家的输出。MoA层包含两个分支:
- 固定“先验”分支:复制自原始网络,保持不变,以保留原始模型的先验知识。
- 可训练“个性化”分支:针对图像输入进行微调,学习嵌入由输入图像表示的主体。
此外,MoA层引入了一个路由网络,负责在两个分支之间分配像素,优化个性化内容和通用内容的混合。
注意力层的工作原理
在MoA层中,每个注意力层都有自己的投影参数。注意力层首先计算注意力图,然后将其应用于值(Value)向量。在自注意力层中,条件(Condition)是隐藏状态本身;在MoA的交叉注意力层中,条件是文本条件,这有助于模型更好地理解文本提示。
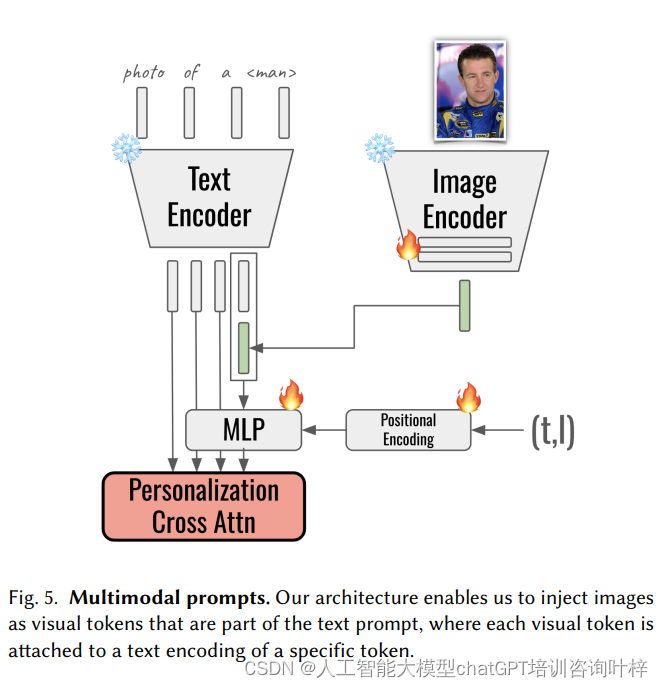
多模态提示
MoA支持将主体图像作为视觉标记注入到文本提示中。通过使用预训练的图像编码器提取图像特征,并将这些特征与文本嵌入拼接,形成多模态嵌入。这些嵌入进一步受到扩散时间步和U-Net层条件的影响,以增强身份保持。
训练策略
MoA的训练包括三个主要部分:
- 掩蔽重建损失:优化前景(主体)的重建,忽略背景。
- 路由损失:训练路由网络,使得背景像素更多地利用“先验”分支,而前景像素则由“个性化”分支生成。
- 对象损失:使用平衡的L1损失,进一步优化个性化分支的性能。
训练过程
MoA层代替了预训练扩散U-Net中的所有注意力层。在推理过程中,MoA块接收输入图像特征,并将它们传递给路由网络,路由网络决定如何在个性化注意力输出和原始注意力块输出之间平衡权重。

创新点
MoA的主要创新在于其能够将个性化主体与生成的上下文解耦,同时保持对原始文本提示的响应性。这种设计不仅提高了个性化图像生成的质量,还为多种应用场景提供了可能性,如主体交换、风格迁移和真实图像编辑。
通过这些方法,MoA架构能够在生成个性化图像的同时,保持与原始模型一样的多样性和上下文互动,实现了个性化生成领域的一大突破。
MoA架构的定量与定性评估
MoA架构的实验部分旨在验证其在个性化图像生成任务中的有效性。实验通过一系列定量和定性评估来展示MoA如何实现主题与上下文的解耦控制,处理遮挡,以及生成多主题图像的能力。
实验设置
- 数据集:使用FFHQ数据集进行训练,该数据集包含由BLIP-2生成的标题和由MaskedFormer生成的分割掩码。定量评估使用了FFHQ测试集和CelebA数据集中的15个主题。
- 模型细节:预训练的文本到图像(T2I)模型使用了StableDiffusion v1.5。图像编码器使用了OpenAI的clip-vit-large-patch14视觉模型。
- 训练配置:在4个NVIDIA H100 GPU上进行训练,使用恒定的学习率1e-5和批量大小128。
定性评估
- 解耦的主体-上下文控制:MoA能够在单次前向传递中实现主体和上下文的解耦,即使在随机种子保持不变的情况下,通过改变输入主体,也能够实现对前景的局部化更改,而不影响背景。
- 图像质量、变化性和一致性:MoA的“在提示空间中的局部注入”特性令人惊讶地处理了遮挡问题。即使在主体被遮挡的情况下,面部细节和身体特征仍然得到了保留。
- 多主题组合:MoA能够生成具有密切互动的多主题图像,即使在跳舞等主体相互遮挡的情况下,生成的图像仍然保持全局一致性。
定量评估
- 评估指标:主要使用了身份保持(Identity Preservation, IP)和提示一致性(Prompt Consistency, PC)两个定量指标。
- 身份保持:使用FaceNet计算生成图像和输入图像之间的成对身份相似度。
- 提示一致性:根据之前的研究,使用CLIP-L/14计算图像-文本相似度的平均值。
实验结果
MoA在身份保持和提示一致性方面与FastComposer等基线方法表现相当。然而,MoA生成的图像在布局上展现了更多的变化性,并且在主体与上下文的互动方面表现得更好。

实验结果表明,MoA架构能够在个性化图像生成任务中实现主体与上下文的有效解耦,同时保持图像的高质量和一致性。此外,MoA的简单性和对现有技术的兼容性为未来的应用开发提供了广阔的空间。
MoA架构的应用
MoA的设计理念使其与现有的图像生成和编辑技术(如ControlNet和DDIM Inversion)天然兼容。这为个性化图像生成的应用提供了广阔的空间,包括但不限于:
- 可控个性化生成 — 利用ControlNet进行姿势控制,MoA可以在保持上下文不变的同时,调整图像中主体的姿态。
- 主体变形(Subject Morphing) — 通过在MoA中对图像特征进行插值,可以在不同主体间实现平滑的过渡,创造出新的虚拟角色。
- 真实图像编辑 — 结合DDIM Inversion技术,MoA可以用于真实照片的编辑,如主体替换,提供了一种新的图像编辑方法。
MoA能够与ControlNet结合使用,实现对生成图像中主体姿势的控制。例如,给定文本提示“在咖啡馆喝咖啡”,用户可以通过ControlNet调整图像中人物的姿势,无论是站立、坐着还是行走,MoA都能保持人物与上下文的一致性。

文本提示:“在埃菲尔铁塔前喝咖啡的人”
应用MoA和ControlNet后,可以生成一系列图像,展示同一人物在不同姿势下的场景。
MoA架构在个性化图像生成领域的强大潜力。无论是在艺术创作、媒体娱乐、教育还是广告设计等领域,MoA都能提供创新的解决方案,推动个性化内容创作的边界。
论文链接:https://arxiv.org/abs/2404.11565
项目地址:https://snap-research.github.io/mixture-of-attention/
















 4252
4252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











