







1.最近邻
Nearest Neighbors官方网址:
https://scikit-learn.org/stable/modules/neighbors.html
GitHub文档地址:https://github.com/gao7025/iris_knn
2.工作原理:
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:K个最近的邻居,每个样本都可以用它最接近的K个邻居来代表,如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特征, KNN算法的结果很大程度取决于K的选择,其中K通常是不大于20的整数。距离有很多种计算方法,一般使用欧氏距离或曼哈顿距离即可。
换句话说,KNN就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,当K取值较大时,抗噪能力强,但K取值较小时,对噪声点的影响特别敏感。
主要步骤:
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
- 优点:
(1)简单方便,易于理解,无需训练,直接计算距离
(2)适用于多分类问题 - 缺点:
(1)当样本数据不平衡时,分类的效果不佳
(2)计算量较大,每一点都要计算K个最近的邻居的距离
3.代码示例
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import neighbors
from sklearn import metrics
iris = datasets.load_iris()
iris_features = iris.data[:, :2]
iris_target = iris.target
train_x, test_x, train_y, test_y = train_test_split(iris_features, iris_target, test_size=0.3, random_state=123)
clf = neighbors.KNeighborsClassifier(20)
clf.fit(train_x, train_y)
pred = clf.predict(test_x)
print('准确率:{:.1%}'.format(metrics.accuracy_score(test_y, pred)))

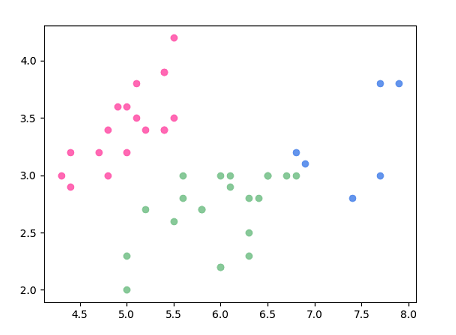
# 预测分类散点图
t = np.column_stack((test_x,pred))
plt.scatter(t[t[:, 2] == 0][:, 0], t[t[:, 2] == 0][:, 1], color = 'hotpink')
plt.scatter(t[t[:, 2] == 1][:, 0], t[t[:, 2] == 1][:, 1], color = '#88c999')
plt.scatter(t[t[:, 2] == 2][:, 0], t[t[:, 2] == 2][:, 1], color = '#6495ED')
plt.show()
分类如图:














 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









