







 本文深入探讨了三种ID生成策略:UUID、数据库自增主键及SnowFlake算法。解析了每种方法的工作原理,对比了它们在性能上的优劣,并详细介绍了SnowFlake算法的实现细节及其在分布式系统中的优势。
本文深入探讨了三种ID生成策略:UUID、数据库自增主键及SnowFlake算法。解析了每种方法的工作原理,对比了它们在性能上的优劣,并详细介绍了SnowFlake算法的实现细节及其在分布式系统中的优势。
非常感谢程序员小灰


————— 第二天 —————





方法一:UUID
UUID是通用唯一识别码 (Universally Unique Identifier),在其他语言中也叫GUID,可以生成一个长度32位的全局唯一识别码。
String uuid = UUID.randomUUID().toString()
结果示例:
046b6c7f-0b8a-43b9-b35d-6489e6daee91

为什么无序的UUID会导致入库性能变差呢?
这就涉及到 B+树索引的分裂:

众所周知,关系型数据库的索引大都是B+树的结构,拿ID字段来举例,索引树的每一个节点都存储着若干个ID。
如果我们的ID按递增的顺序来插入,比如陆续插入8,9,10,新的ID都只会插入到最后一个节点当中。当最后一个节点满了,会裂变出新的节点。这样的插入是性能比较高的插入,因为这样节点的分裂次数最少,而且充分利用了每一个节点的空间。
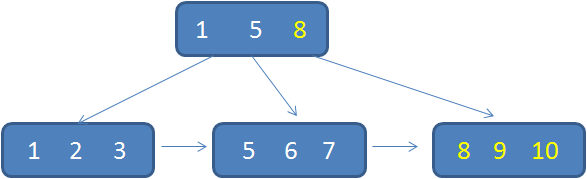
但是,如果我们的插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。


方法二:数据库自增主键
假设名为table的表有如下结构:
id feild
35 a
每一次生成ID的时候,访问数据库,执行下面的语句:
begin;
REPLACE INTO table ( feild ) VALUES ( ‘a’ );
SELECT LAST_INSERT_ID();
commit;
REPLACE INTO 的含义是插入一条记录,如果表中唯一索引的值遇到冲突,则替换老数据。
这样一来,每次都可以得到一个递增的ID。
为了提高性能,在分布式系统中可以用DB proxy请求不同的分库,每个分库设置不同的初始值,步长和分库数量相等.
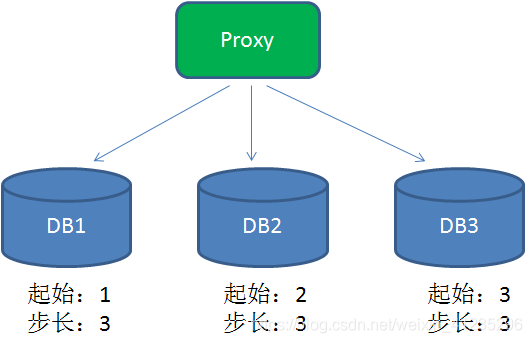
这样一来,DB1生成的ID是1,4,7,10,13…,DB2生成的ID是2,5,8,11,14…









初识SnowFlake
snowflake算法所生成的ID结构是什么样子呢?我们来看看下图:
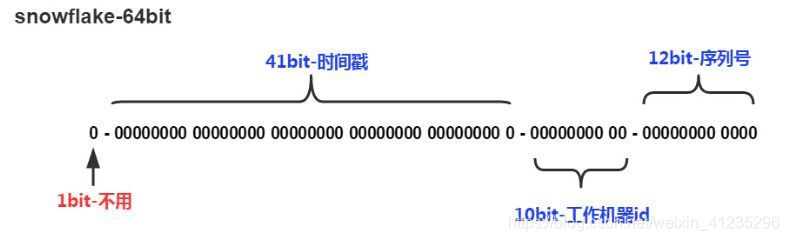
SnowFlake所生成的ID一共分成四部分:
1.第一位
占用1bit,其值始终是0,没有实际作用。
2.时间戳
占用41bit,精确到毫秒,总共可以容纳约69 年的时间。
3.工作机器id
占用10bit,其中高位5bit是数据中心ID(datacenterId),低位5bit是工作节点ID(workerId),做多可以容纳1024个节点。
4.序列号
占用12bit,这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。
SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢?只需要做一个简单的乘法:
同一毫秒的ID数量 = 1024 X 4096 = 4194304
这个数字在绝大多数并发场景下都是够用的。
SnowFlake的代码实现


public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_TIMESTAMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATA_CENTER_BIT = 5; //数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
private long dataCenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastTimeStamp = -1L; //上一次时间戳
/**
* 根据指定的数据中心ID和机器标志ID生成指定的序列号
*
* @param dataCenterId 数据中心ID
* @param machineId 机器标志ID
*/
public SnowFlake(long dataCenterId, long machineId) {
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("DtaCenterId can't be greater than MAX_DATA_CENTER_NUM or less than 0!");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("MachineId can't be greater than MAX_MACHINE_NUM or less than 0!");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currTimeStamp = getNewTimeStamp();
if (currTimeStamp < lastTimeStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currTimeStamp == lastTimeStamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currTimeStamp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastTimeStamp = currTimeStamp;
return (currTimeStamp - START_TIMESTAMP) << TIMESTAMP_LEFT //时间戳部分
| dataCenterId << DATA_CENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewTimeStamp();
while (mill <= lastTimeStamp) {
mill = getNewTimeStamp();
}
return mill;
}
private long getNewTimeStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(1, 1);
for (int i = 0; i < 1000000; i++) {
//10进制
System.out.println(snowFlake.nextId());
}
}
}
SnowFlake的优势和劣势


SnowFlake算法的优点:
1.生成ID时不依赖于DB,完全在内存生成,高性能高可用。
2.ID呈趋势递增,后续插入索引树的时候性能较好。
SnowFlake算法的缺点:
依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。


















 7044
7044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









