







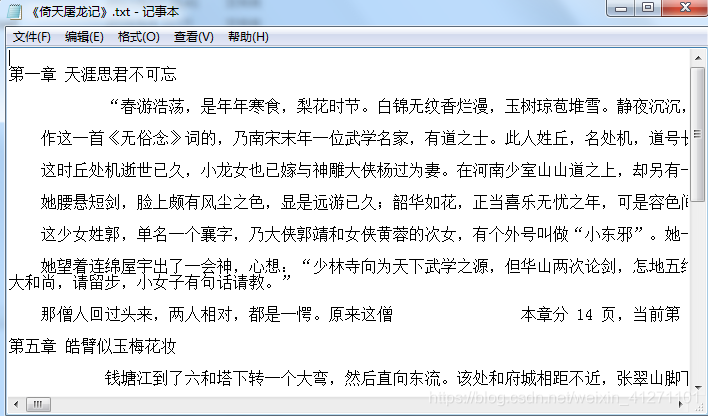
倚天屠龙记小说网址:https://www.2biqukan.com/fiction/zsczu.html
实现代码:
from urllib import request
from bs4 import BeautifulSoup
import time
import socket
def download_specified_chapter(chapter_url, header, coding, chapter_name=None):
#先生成一个request对象,传入url和headers
download_req = request.Request(chapter_url,headers=header)
#通过指定urlopen打开request对象中的url网址,并获得对应内容
response = request.urlopen(download_req)
#获取页面的html
download_html = response.read().decode(coding, 'ignore')
#request.close()#记得要关闭
#获取html的bs
origin_soup = BeautifulSoup(download_html, 'lxml')
#获取小说正文部分
content=origin_soup.find(id='novel-content', class_='font-size-middle')
#整理小说格式,将\xa0替换成回车
# html中的 ,在转换成文档后,变成\xa0
txt=content.text.replace('\xa0'*8,'\n')
# 将获得的正文 写入txt
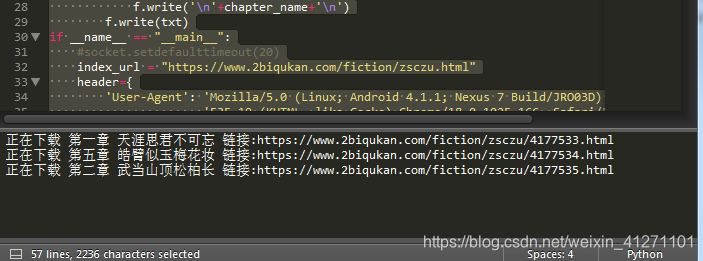
print("正在下载 {} 链接:{}".format(chapter_name,chapter_url))
with open('《倚天屠龙记》.txt','a') as f:
if chapter_name is None:
f.write('\n')
else :
f.write('\n'+chapter_name+'\n')
f.write(txt)
if __name__ == "__main__":
#socket.setdefaulttimeout(20)
index_url = "https://www.2biqukan.com/fiction/zsczu.html"
header={
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/'
'535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
}
#指定url,header生成request
url_req = request.Request(index_url,headers=header)
#打开url,并获得请求内容response
response = request.urlopen(url_req)
#读取response的内容,用utf-8解码,得到html内容
html = response.read().decode('utf-8', 'ignore')
#用BeautifulSoup处理得到的网页html
html_soup = BeautifulSoup(html,'lxml')
index = BeautifulSoup(str(html_soup.find_all('ul', class_='list-group novel-index row')),'lxml')
#print(index.find_all(['ul', ['li']]))
#判断是否找到了《倚天屠龙记》相对应的ul
body_flag = False
for element in index.find_all(['ul', ['li']]):
if element.name == 'ul':
body_flag = True
if body_flag is True and element.name == 'li':
chapter_name = element.string
chapter_url = "https://www.2biqukan.com"+element.a.get('href')
#print(" {} 链接地址:{}".format(chapter_name,chapter_url))
download_specified_chapter(chapter_url, header, 'UTF_8', chapter_name)
实现图片















 3748
3748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











