







基本概念
类集框架的简介
类集的主要用处是在于其实现了动态对象数组的操作,并且定义了大量的操作。
单对象保存父接口:Collection
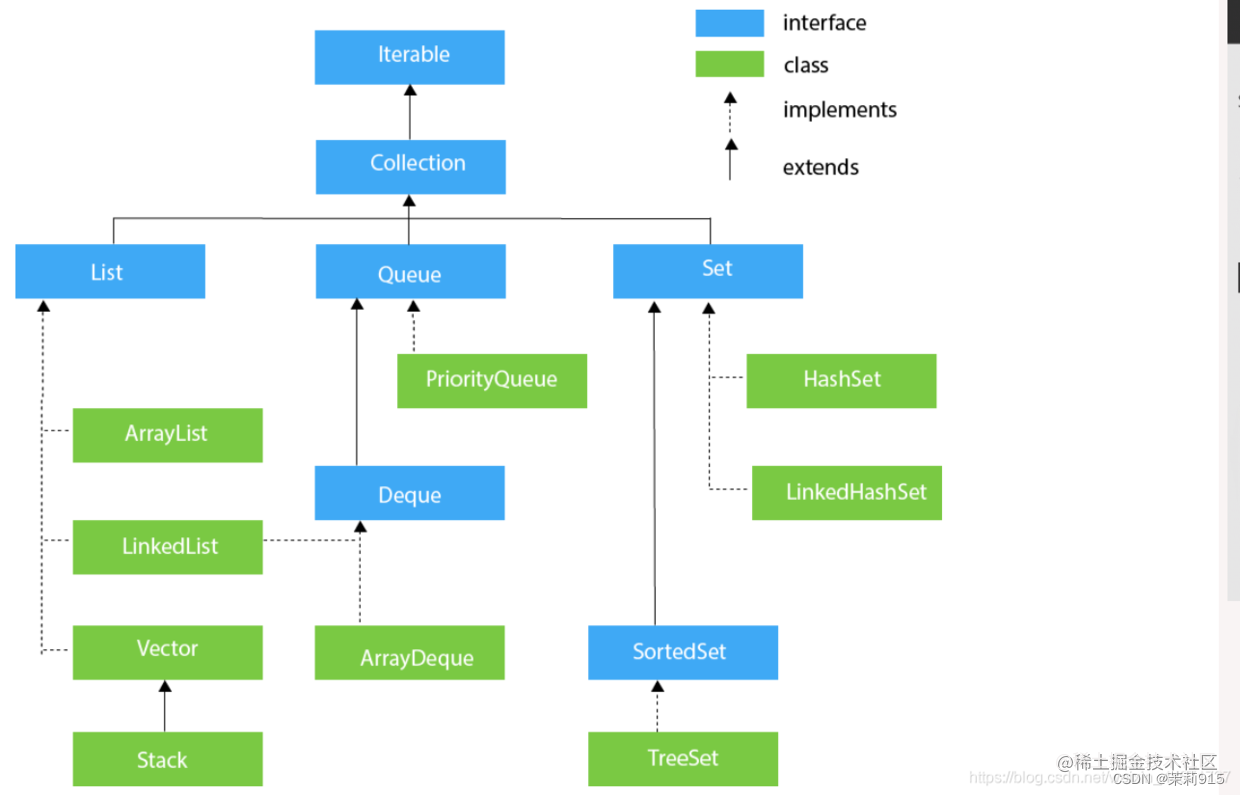
java.util.Collection是进行单对象保存的最大父接口,即每次利用Collection接口都只能保存
一个对象信息。
// A code block
public interface Collection<E> extends Iterable<E>
Collection接口的核心方法
| NO. | 方法名称 | 类型 | 描述 |
|---|---|---|---|
| 1 | public boolean add(E e) | 普通 | 向集合里面保存数据 |
| 2 | public boolean addAll(Collection<? extends E> c) | 普通 | 追加一个集合 |
| 3 | public void clear() | 普通 | 清空集合,根元素为null |
| 4 | public boolean contains(Object o) | 普通 | 判断是否包含指定内容,需要equals()支持 |
| 5 | public boolean isEmpty() | 普通 | 判断是否是空集合(不是null) |
| 6 | public boolean remove(Object o) | 普通 | 删除对象,需要equals()支持 |
| 7 | public int size() | 普通 | 取得集合中保存的元素个数 |
| 8 | public Object[] toArray() | 普通 | 将集合变为对象数组保存 |
| 9 | public Iterator< E > iterator() | 普通 | 为Iterator接口实例化(Interator接口定义) |
| 对于表中的方法,一定要记住add()与iterator()两个方法。 |
Collection及其子接口继承关系

List子接口
List子接口最大的功能是里面所保存的数据可以存在有重复内容,并且在Collection子接口中List子接口是最为常用的一个子接口,在List接口中对Collection接口的功能进行了扩充
| NO. | 方法名称 | 类型 | 描述 |
|---|---|---|---|
| 1 | public E get(int index) | 普通 | 取得索引编号内容 |
| 2 | public E set(int index, E element) | 普通 | 修改指定索引编号的内容 |
| 3 | public ListIterator< E> listIterator() | 普通 | 为ListIterator接口实例化 |
新的子类:ArrayList
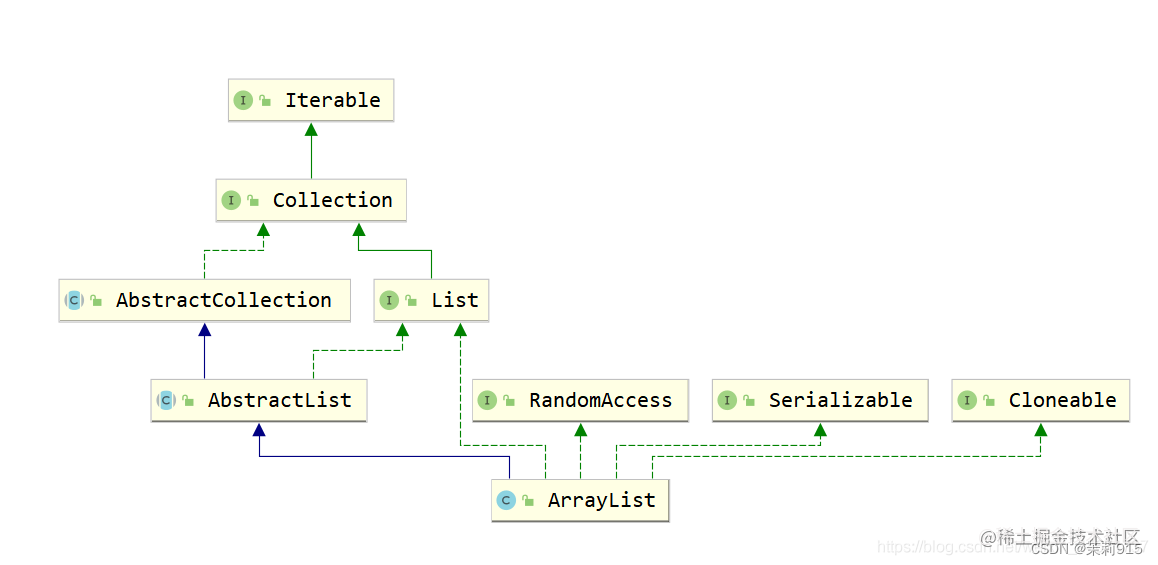
ArrayList子类是List子接口中最常用的一个子类。
常见用法
// An highlighted block
public class Demo{
public static void main(String[] args){
List<String> all = new ArrayList<>();
System.out.println("长度:"+all.size()+",是否为空:"+all.isEmpty());
//添加数据
all.add("hello");
all.add("hello");
all.add("world");
//删除数据,有重复的删除第一个
all.remove("hello");
//将list转化为数组
String[] strings = all.toArray(new String[all.size()]);
//for循环
for(int x = 0; x < all.size(); x++){
String str = all.get(x);
System.out.println(str);
}
//foreach循环
for(String s : all){
System.out.println(s);
}
//iterator迭代器
Iterator<String> iterator = all.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
//remove需要在next方法之后操作
iterator.remove();
}
}
}
执行结果:长度:0,是否为空:true
hello
world
hello
world
hello
world
请解释ArrayList和LinkedList的区别
实际上在List子接口中还存在一个LinkedList子类,而使用时大部分情况下都是利用子类为父接口实例化。
- ArrayList中采用顺序式的结果进行数据保存,并且可以自动生成相应的索引信息;
- LinkedList集合保存的是前后元素,也就是说,它每一个节点保存的是两个元素对象,一个它对应的下一个节点,以及另外一个它对应的上一个节点,所以LinkedList要占用比ArrayList更多的内存空间。同时LinkedList比ArrayList多实现了一个Queue队列数据接口。
旧的子类:Vector
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
List<String> all = new Vector<String>();
System.out.println("长度:"+all.size()+",是否为空:"+all.isEmpty());
all.add("hello");
all.add("hello");
all.add("world");
System.out.println("长度:"+all.size()+",是否为空:"+all.isEmpty());
for(int x = 0; x < all.size();x++){
String str = all.get(x);
System.out.println(str);
}
}
}
执行结果:长度:0,是否为空:true
长度:3,是否为空:false
hello
hello
world
ArrayList和Vector子类的区别:
| No | 区别点 | ArrayList(90%) | Vector(10%) |
|---|---|---|---|
| 1 | 推出时间 | JDK1.2推出,属于新的类 | JDK1.0推出,属于旧的类 |
| 2 | 性能 | 采用异步处理 | 采用同步处理 |
| 3 | 数据安全 | 非线程安全 | 线程安全 |
| 4 | 输出 | Iterator、ListIterator、foreach | Iterator、ListIterator、foreach、Enumeration |
Set子接口
在Collection接口下又有另外一个比较常用的子接口为Set子接口,但是Set子接口并不像List子接口那样对Collection接口进行了大量的扩充,而是简单地继承了Collection接口。也就是说无法使用get()方法根据索引取得保存数据的操作。在Set接口下有两个常用的子类:HashSet、TreeSet。
HashSet是散列存放数据,而TreeSet是有序存放的子类。在实际开发中,如果要使用TreeSet子类则必须同时使用比较器的概念,而HashSet子类相对于TreeSet子类更加容易一些,所以如果没有排序要求应优先考虑HashSet子类。
使用HashSet子类的特点
- HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
- HashSet 允许有 null 值。
- HashSet 是无序的,即不会记录插入的顺序。
- HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对
HashSet 的并发访问。
添加元素和删除元素
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
Set<String> all = new HashSet<String>();
all.add("jixianit");
all.add("mldn");
all.add("yootk");
all.add("yootk");
all.remove("mldn");
System.out.println(all);
}
}
执行结果:[jixianit, yootk]
可以看出在Set集合中不允许保存重复数据。
迭代 HashSet
public class App
{
public static void main( String[] args )
{
Set<String> all = new HashSet<>();
all.add("jixianit");
all.add("mldn");
all.add("yootk");
//使用foreach迭代
for(String str : all){
System.out.println(str);
}
//使用迭代器
Iterator<String> iterator = all.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
关于"Hash"的说明
这种算法就是利用二进制的计算结果来设置保存的空间,根据数值的不同,最终保存空间的位置也不同,所以利用Hash算法保存的集合都是无序的,但是查找速度较快。
使用TreeSet子类
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
Set<String> all = new TreeSet<String>();
all.add("jixianit");
all.add("mldn");
all.add("yootk");
all.add("yootk");
System.out.println(all);
}
}
执行结果:[jixianit, mldn,yootk]
TreeSet子类属于排序的类集结构,所以当使用TreeSet子类实例化Set接口后,所保存的数据将变为有序,默认情况按字母的升序排列。
关于数据排序的说明
TreeSet子类保存的内容可以进行排序,但是其排序是依靠比较器接口(Comparable)实现的,即如果要利用TreeSet子类保存任意类的对象,那么该对象所在的类必须要实现java.lang.Comparable接口。
// An highlighted block
class Book implements Comparable<Book>{
private String title;
private double price;
public Book(String title,double price){
this.title = title;
this.price = price;
}
@Override
public String toString(){
return "书名:"+this.title+",价格:"+this.price;
}
@Override
public int compareTo(Book o) {
if(this.price > o.price){
return 1;
}else if(this.price < o.price){
return -1;
}else {
return this.title.compareTo(o.title);
}
}
}
public class TestDemo {
public static void main(String args[]) {
Set<Book> all = new TreeSet<Book>();
all.add(new Book("Java开发实战经典",79.8));
all.add(new Book("Java开发实战经典",79.8));
all.add(new Book("JSP开发实战经典",79.8));
all.add(new Book("Android开发实战经典",89.8));
System.out.println(all);
}
}
执行结果:[书名:JSP开发实战经典,价格:79.8, 书名:Java开发实战经典,价格:79.8, 书名:Android开发实战经典,价格:89.8]
本程序首先利用TreeSet子类保存了若干个Book类对象,由于Book类实现了Comparable接口,所以会自动将保存的Book类对象强制转换为Comparable接口对象,然后调用compareTo()方法进行排序,如果发现比较结果为0则认为是重复元素,将不再进行保存。因此TreeSet数据的排序以及重复元素的消除依靠的都是Comparable接口。
关于重复元素说明
TreeSet利用Comparable接口实现重复元素的判断,但是这样的操作只适合支持排序类集操作环境下;而其他子类(例如:HashSet)如果要消除重复元素,则必须依靠Object类中提供的两个方法。
- 取得哈希码:public int hashCode();
先判断对象的哈希码是否相同,依靠哈希码取得一个对象的内容; - 对象比较:public boolean equals(Object obj)。
再将对象的属性进行依次的比较。
利用HashSet子类保存自定义对象。
// An highlighted block
class Book {
private String title;
private double price;
public Book(String title,double price){
this.title = title;
this.price = price;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Double.compare(book.price, price) == 0 &&
Objects.equals(title, book.title);
}
@Override
public int hashCode() {
return Objects.hash(title, price);
}
@Override
public String toString(){
return "书名:"+this.title+",价格:"+this.price;
}
}
public class TestDemo {
public static void main(String args[]) {
Set<Book> all = new HashSet<>();
all.add(new Book("Java开发实战经典",79.8));
all.add(new Book("Java开发实战经典",79.8));
all.add(new Book("JSP开发实战经典",79.8));
all.add(new Book("Android开发实战经典",89.8));
System.out.println(all);
}
}
执行结果:[书名:JSP开发实战经典,价格:79.8, 书名:Android开发实战经典,价格:89.8, 书名:Java开发实战经典,价格:79.8]
直接通过idea工具生成操作步骤:【Source】→【Generate hashCode() and equals()】
集合排序
对整型进行排序
public class App {
public static void main( String[] args ) {
List<Integer> list = new ArrayList<>();
list.add(5);
list.add(1);
list.add(8);
//升序排列
Collections.sort(list); //java.util.Collections
System.out.println(list);
//降序排列
Collections.reverse(list);
System.out.println(list);
}
}
结果:[1, 5, 8]
[8, 5, 1]
对字符串进行排序
根据首字母ascii码中的值来比较大小
public class App {
public static void main( String[] args ) {
List<String> list = new ArrayList<>();
list.add("orange");
list.add("tomato");
list.add("apple");
Collections.sort(list); //java.util.Collections
System.out.println(list);
}
}
结果:[apple, orange, tomato]
根据Comparator接口进行排序
定义一个比较器实现Comparator接口中的compare()方法
根据名字进行升序排序(升序为从小到大)
class NameComparator implements Comparator<Cat>{
@Override
public int compare(Cat o1, Cat o2) {
String name1 = o1.getName();
String name2 = o2.getName();
int i = name1.compareTo(name2); //降序改为:name2.compareTo(name1);就行
return i;
}
}
public class App {
public static void main( String[] args ) {
List<Cat> list = new ArrayList<>();
list.add(new Cat("huahua",5,"英国短毛猫"));
list.add(new Cat("fanfan",2,"中华田园猫"));
list.add(new Cat("maomao",3,"中华田园猫"));
//实现比较器接口写法
Collections.sort(list,new NameComparator()); //第一个参数要排序的集合,第二个参数是比较器
//匿名内部类写法
Collections.sort(list, new Comparator<Cat>() {
@Override
public int compare(Cat o1, Cat o2) {
return o1.getName().compareTo(o2.getName());
}
});
//lambda写法
Collections.sort(list, (o1, o2) -> o1.getName().compareTo(o2.getName()));
Systemut.println(list);
}
}
结果:[Cat{name='fanfan', month=2, species='中华田园猫'}, Cat{name='huahua', month=5, species='英国短毛猫'}, Cat{name='maomao', month=3, species='中华田园猫'}]
根据年龄进行降序排序
class NameComparator implements Comparator<Cat>{
//如果要按照升序排序,则o1 小于o2,返回-1(负数),相等返回0,o1大于o2返回1(正数)
//如果要按照降序排序,则o1 大于o2,返回1(正数),相等返回0,o1小于o2返回-1(负数)
@Override
public int compare(Cat o1, Cat o2) {
int age1 = o1.getMonth();
int age2 = o2.getMonth();
return age2-age1; //升序改为age1-age2就行
}
}
public class App {
public static void main( String[] args ) {
List<Cat> list = new ArrayList<>();
list.add(new Cat("huahua",5,"英国短毛猫"));
list.add(new Cat("fanfan",2,"中华田园猫"));
list.add(new Cat("maomao",3,"中华田园猫"));
Collections.sort(list,new NameComparator()); //第一个参数要排序的集合,第二个参数是比较器
System.out.println(list);
}
}
结果:[Cat{name='huahua', month=5, species='英国短毛猫'}, Cat{name='maomao', month=3, species='中华田园猫'}, Cat{name='fanfan', month=2, species='中华田园猫'}]
根据Comparable接口进行排序
需要排序的集合类要实现Comparable接口中的compareTo()方法。
根据价格进行降序排序
// An highlighted block
class Book implements Comparable<Book>{
private String title;
private double price;
public Book(String title,double price){
this.title = title;
this.price = price;
}
@Override
public String toString(){
return "书名:"+this.title+",价格:"+this.price;
}
@Override
public int compareTo(Book o) {
double price1 = this.getPrice();
double price2 = o.getPrice();
int i = new Double(price2 - price1).intValue();
return i;
}
}
public class TestDemo {
public static void main(String args[]) {
Set<Book> all = new TreeSet<Book>();
all.add(new Book("Java开发实战经典",79.8));
all.add(new Book("JSP开发实战经典",99.8));
all.add(new Book("Android开发实战经典",89.8));
System.out.println(all);
}
}
执行结果:[书名:JSP开发实战经典,价格:99.8, 书名:Android开发实战经典,价格:89.8, 书名:Java开发实战经典,价格:79.8]
集合输出
迭代输出:Iterator
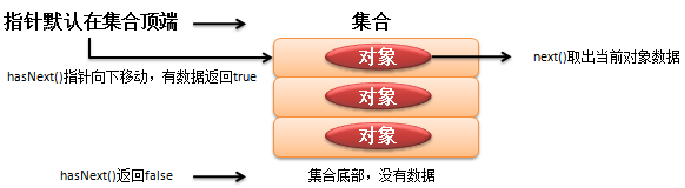
Iterator(迭代器)是集合输出操作中最为常见的接口,而在Collection接口中也提供了直接为Iterator接口实例化的方法(iterator()),所以任何集合类型都可以转换为Iterator接口输出。
Iterator接口中一共定义了两个抽象方法,
| NO. | 方法 | 类型 | 描述 |
|---|---|---|---|
| 1 | public boolean hasNext() | 普通 | 判断是否还有内容 |
| 2 | public E next() | 普通 | 取出当前内容 |
| 3 | public void remove() | 普通 | 删除当前元素 |
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
List<String> all = new ArrayList<>();
all.add("hello");
all.add("hello");
all.add("world");
Iterator<String> iter = all.iterator();
while (iter.hasNext()){
String str = iter.next();
System.out.println(str);
}
}
}
执行结果:hello
hello
world
关于Iterator接口中的remove()方法。
如果利用集合类(Collection、List、Set)提供的remove()方法会导致程序中断执行的问题,而如果非要进行集合元素的删除,只能利用Iterator接口提供的remove()方法才可以正常完成。
双向迭代:ListIterator
虽然利用Iterator可以实现集合的迭代输出操作,但是Iterator本身却存在一个问题:只能进行由前向后的输出。所以为了让输出变得更加灵活,在类集框架中就提供了一个ListIterator接口,利用此接口可以实现双向迭代。ListIterator属于Iterator的子接口,此接口常用方法如表:
| NO. | 方法 | 类型 | 描述 |
|---|---|---|---|
| 1 | public boolean hasPrevious() | 普通 | 判断是否有前一个元素 |
| 2 | public E previous() | 普通 | 取出前一个元素 |
| 3 | public E add() | 普通 | 向集合追加元素 |
| 4 | public E set() | 普通 | 修改集合元素 |
实际上迭代器本质上就是一个指针的移动操作,而ListIterator与Iterator的迭代处理原理类似。所以如果要进行由后向前迭代,则必须先进行由前向后迭代。
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
List<String> all = new ArrayList<>();
all.add("hello");
all.add("hello");
all.add("mldn");
all.add("world");
ListIterator<String> iter = all.listIterator();
while (iter.hasNext()){
String str = iter.next();
System.out.println(str);
}
System.out.println();
while(iter.hasPrevious()){
String str = iter.previous();
System.out.println(str);
}
}
}
执行结果:hello
hello
mldn
world
world
mldn
hello
hello
foreach输出
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
List<String> all = new ArrayList<>();
all.add("hello");
all.add("hello");
all.add("mldn");
all.add("world");
for(String str : all){
System.out.println(str);
}
}
}
执行结果:hello
hello
world
Enumeration输出
Enumeration(枚举输出)是与Vector类一起在JDK1.0时推出的输出接口
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
Vector<String> all = new Vector<>();
all.add("hello");
all.add("hello");
all.add("mldn");
all.add("world");
Enumeration<String> enu = all.elements();
while (enu.hasMoreElements()){
String str = enu.nextElement();
System.out.println(str);
}
}
}
执行结果:hello
hello
mldn
本程序与Iterator接口输出实现的最终效果是完全一致的,唯一的区别就是,如果要使用Enumeration接口实例化,就必须依靠Vector子类完成。
偶对象保存:Map接口
Collection每次只能够保存一个对象,所以属于单值保存父接口。而在类集中又提供有保存偶对象的集合:Map集合,利用Map结合可以保存一对关联数据(按照“key = value”的形式),如图13-4所示。,这样就可以实现根据key取得value的操作。


Map接口的常用方法
| NO. | 方法 | 类型 | 描述 |
|---|---|---|---|
| 1 | public V put(K key, V value) | 普通 | 向集合中保存元素 |
| 2 | public V get(Object key) | 普通 | 根据key查找对应的value数据 |
| 3 | public Set<Map.Entry<K,V>> entrySet() | 普通 | 将Map集合转化为Set集合 |
| 4 | public Set keySet() | 普通 | 取出全部的key |
HashMap的使用
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
HashMap<String,Integer> map = new HashMap<>();
map.put("壹",1);
map.put("贰",2);
map.put("叁",3);
map.put("叁",33);
map.put("肆",4);
map.put("空",null);
map.put(null,0);
map.remove("壹");
System.out.println(map.get("叁"));
System.out.println(map.get(null));
System.out.println(map.get("空"));
}
}
执行结果:33
0
null
从上可以发现如下特点:
- 使用HashMap定义的Map集合是无序存放的;
- 如果发现了重复的key会进行覆盖,使用新的内容替换旧的内容;
- 使用HashMap子类保存数据时key或value可以保存为null。
遍历HashMap的key值
public class App
{
public static void main( String[] args )
{
HashMap<String,Integer> map = new HashMap<>();
map.put("壹",1);
map.put("贰",2);
map.put("叁",3);
map.put("叁",33);
map.put("肆",4);
map.put("空",null);
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
遍历HashMap的value值
public class App
{
public static void main( String[] args )
{
HashMap<String,Integer> map = new HashMap<>();
map.put("壹",1);
map.put("贰",2);
map.put("叁",3);
map.put("叁",33);
map.put("肆",4);
map.put("空",null);
Collection<Integer> values = map.values();
Iterator<Integer> iterator = values.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
Hashtable的使用
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
Map<String,Integer> map = new Hashtable<>();
map.put("壹",1);
map.put("贰",2);
map.put("叁",3);
map.put("叁",33);
map.put("肆",4);
System.out.println(map.get("叁"));
}
}
执行结果:33
使用Hashtable子类实例化的Map集合中,保存的key和value都不允许出现null,否则会出现"NullPointerException"异常
HashMap和Hashtable子类的区别:
| No | 区别点 | HashMap | Hashtable |
|---|---|---|---|
| 1 | 推出时间 | JDK1.2推出,属于新的类 | JDK1.0推出,属于旧的类 |
| 2 | 性能 | 采用异步处理 | 采用同步处理 |
| 3 | 数据安全 | 非线程安全 | 线程安全 |
| 4 | 设置null | 允许key或value内容为null | 不允许设置null |
利用Iterator输出Map集合
进行Map集合保存时,所保存的key与value会自动包装为Map.Entry接口对象,也就是说如果利用Iterator进行迭代,那么每当使用next()方法读取数据时返回的都会是一个Map.Entry接口对象,此接口定义如下:
public static interface Map.Entry<K,V> {}
Map.Entry接口定义的常用方法
| No | 方法 | 类型 | 描述 |
|---|---|---|---|
| 1 | public K getKey() | 普通 | 取得数据中的key |
| 2 | public V getValue() | 普通 | 取得数据中的value |
| 3 | public V setValue(V value) | 普通 | 修改数据中的value |
 | |||
| Iterator输出Map集合的操作步骤: | |||
| 1.利用entrySet()方法将Map接口数据中的数据转换为Set接口实例进行保存,此时Set接口中所使用的泛型类型为Map.Entry,而Map.Entry中的K与V的泛型类型则与Map集合定义的K与V类型相同; | |||
| 2.利用Set接口中的iterator()方法将Set集合转化为Iterator接口实例; | |||
| 3.利用Iterator接口进行迭代输出,每一次迭代取得的都是Map.Entry接口实例,而后利用此接口实例进行key与value的分离。 |
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
Map<String,Integer> map = new HashMap<>();
map.put("壹",1);
map.put("贰",2);
map.put("叁",3);
map.put("叁",33);
map.put("肆",4);
map.put("空",null);
map.put(null,0);
Set<Map.Entry<String,Integer>> set= map.entrySet();
Iterator<Map.Entry<String, Integer>> iterator = set.iterator();
while (iterator.hasNext()){
Map.Entry<String, Integer> next = iterator.next();
System.out.println(next.getKey()+"="+next.getValue());
}
}
}
执行结果:贰=2
null=0
叁=33
肆=4
壹=1
空=null
自定义Map集合的key类型
在使用Map接口的时候可以发现,几乎可以使用任意的类型来作为key或value的存在,那么也就表示也可以使用自定义的类型作为key。那么这个作为key的自定义的类必须要覆写Object类之中的hashCode()与equals()两个方法,因为只有靠这两个方法才能够确定元素是否重复,而在Map中指的是是否能够找到。
// An highlighted block
class Book{
private String title;
public Book(String title){
this.title = title;
}
@Override
public String toString() {
return "Book{" +
"title='" + title + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Objects.equals(title, book.title);
}
@Override
public int hashCode() {
return Objects.hash(title);
}
}
public class TestDemo {
public static void main(String args[]) {
Map<Book, String> map = new HashMap<>();
map.put(new Book("Java开发"),new String("Java"));
System.out.println(map.get(new Book("Java开发")));
}
}
执行结果:Java
Stack子类
栈也是一种动态对象数组,采用的是一种先进后出的数据结构形式,即:在栈中最早保存的数据最后才会取出,而最后保存的数据可以最先取出


java.util包中可以利用Stack类实现栈的功能,此类定义如下:
public class Stack extends Vector
Stack类的常用方法
| No | 方法 | 类型 | 描述 |
|---|---|---|---|
| 1 | public E push(E item) | 普通 | 数据入栈 |
| 2 | public E pop() | 普通 | 数据出栈,如果栈中没有数据,则调用此方法会抛出空栈异常(EmptyStackException) |
观察栈的操作
// An highlighted block
public class TestDemo {
public static void main(String args[]) {
Stack<String> all = new Stack<String>();
all.push("www.abc.com");
all.push("www.hhh.com");
all.push("www.trtr.com");
System.out.println(all.pop());
System.out.println(all.pop());
System.out.println(all.pop());
System.out.println(all.pop());
}
}
执行结果:Exception in thread "main" java.util.EmptyStackException
at java.util.Stack.peek(Stack.java:102)
at java.util.Stack.pop(Stack.java:84)
at chapter4.TestDemo.main(TestDemo.java:12)
www.trtr.com
www.hhh.com
www.abc.com















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









