









一、shell命令
1.命令格式
在hadoop目录下
hdfs dfs -cmd<args>
2.使用HDFS shell处理移动通讯数据
(1)创建存放数据文件的目录
hdfs dfs -mkdir -p /hdfs/shell
hdfs dfs -ls /hdfs/shell
(2)将通讯数据上传到HDFS并查看
hdfs dfs -put /home/hadoop/data/mobile.txt /hdfs/shell
hdfs dfs -text /hdfs/shell/mobile.txt
(3)下载文件到本地
hdfs dfs -get /hdfs/shell/mobile.txt /home/hadoop
(3)删除文件
hdfs dfs -rm /hdfs/shell/mobile.txt
二、使用Java进行HDFS操作
1.在windows上配置环境变量
选择一个非中文目录,将下载解压好的Hadoop文件,右键我的电脑打开属性—》高级系统设置—》环境变量 进行配置
HADOOP_HOME
D:\hadoop\hadoop-2.6.0-cdh5.14.2

PATH下配置
%HADOOP_HOME%\bin
在命令行窗口任意目录输入
hadoop -version
查看配置是否成功

2.在IDEA中创建一个maven项目
(1)选择创建maven项目

(2)为项目起名
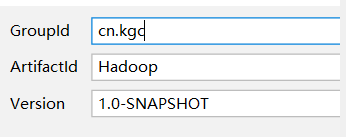
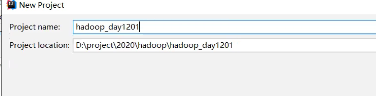
(3)在配置文件中添加依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
</dependencies>
下载需要挺久,请耐心等待
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
(4)创建一个文件夹
public class HdfsClient{
@Test
public void testMkdirs() throws IOException, InterruptedException,
URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
// configuration.set("fs.defaultFS", "hdfs://192.168.202.201:9000");
// FileSystem fs = FileSystem.get(configuration);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.202.201:9000"),
configuration, "root");
// 2 创建目录
fs.mkdirs(new Path("/kgc/hdfs/demo1"));
// 3 关闭资源
fs.close();
}
}


(5)HDFS 文件夹删除
@Test
public void testDelete() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "kgc");
// 2 执行删除
fs.delete(new Path("/kgc/"), true);
// 3 关闭资源
fs.close();
}
(6)HDFS文件改名
@Test
public void testRename() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "kgc");
// 2 修改文件名称
fs.rename(new Path("/hello.txt"), new Path("/hello2.txt"));
// 3 关闭资源
fs.close();
}
(7)hdfs文件详情查看
public void testListFiles() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "kgc");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new
Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
// 输出详情
// 文件名称
System.out.println(status.getPath().getName());
// 长度
System.out.println(status.getLen());
// 权限
System.out.println(status.getPermission());
// 组
System.out.println(status.getGroup());
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("----------------分隔-----------");
}
}
(8)HDFS 文件上传
@Test
public void testCopyFromLocalFile() throws IOException,
InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.202.201:9000"),configuration, "root");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyFromLocalFile(new Path("D:\\IDEA_project\\Hadoop_day1201\\src\\main\\java\\cn\\kgc\\hdfs\\HdfsClient.java"), new Path("/user"));
// 3 关闭资源
fs.close();
}
}
(9)HDFS 文件下载
@Test
public void testCopyToLocalFile() throws IOException,
InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.202.201:9000"),
configuration, "root");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/user/HdfsClient.java"), new
Path("d:/HdfsClient.java"),true);
// 3 关闭资源
fs.close();
}
三、HDFS 的 I/O 流操作
1.HDFS 文件上传
使用流的方式实现文件上传。
需求:将本地文件通过流的方式上传到 HDFS 文件系统。
代码如下:
@Test
public void putFileToHDFS() throws IOException, InterruptedException,
URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "kgc");
// 2 创建输入流
FileInputStream fis = new FileInputStream(new File("d:/hello.txt"));
// 3 获取输出流
FSDataOutputStream fos = fs.create(new Path("/hello4.txt"));
// 4 执行流拷贝
IOUtils.copyBytes(fis, fos, configuration);
// 5 关闭资源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
2.HDFS 文件下载
使用流的方式实现文件下载。
需求:从 HDFS 上下载文件到本地磁盘上。
代码如下:
// 文件下载
@Test
public void getFileFromHDFS() throws IOException,
InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "kgc");
// 2 获取输入流
FSDataInputStream fis = fs.open(new Path("/hello1.txt"));
// 3 获取输出流
FileOutputStream fos = new FileOutputStream(new
File("d:/hello1.txt"));
// 4 流的对拷
IOUtils.copyBytes(fis, fos, configuration);
// 5 关闭资源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
fs.close();
}
3.案例演示可以将 hadoop 安装包上传到 HDFS 文件系统。
(1)下载第一块
@Test
public void readFileSeek1() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "hadoop");
// 2 获取输入流
FSDataInputStream fis = fs.open(new
Path("/hadoop-2.6.0-cdh5.14.2.tar.gz"));
// 3 创建输出流
FileOutputStream fos = new FileOutputStream(new
File("d:/hadoop-2.6.0-cdh5.14.2.tar.gz.part1"));
// 4 流的拷贝
byte[] buf = new byte[1024];
for(int i =0 ; i < 1024 * 128; i++){
fis.read(buf);
fos.write(buf);
}
// 5 关闭资源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
(2)下载第二块
@Test
public void readFileSeek2() throws IOException, InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"),
configuration, "kgc");
// 2 打开输入流
FSDataInputStream fis = fs.open(new
Path("hadoop-2.6.0-cdh5.14.2.tar.gz"));
// 3 定位输入数据位置
fis.seek(1024*1024*128);
// 4 创建输出流
FileOutputStream fos = new FileOutputStream(new
File("d:/hadoop-2.6.0-cdh5.14.2.tar.gz.part2"));
// 5 流的对拷
IOUtils.copyBytes(fis, fos, configuration);
// 6 关闭资源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
(3)下载的进行合并
在 window 命令窗口中执行
type hadoop-2.6.0-cdh5.14.2.tar.gz.part2 >>hadoop-2.6.0-cdh5.14.2.tar.gz.part1
合并后就是完整的 hadoop 安装包文件
从上面的案例中可以看出,HDFS 提供的流读取数据的方式,可以从任意位
置开始读取数据。这与后面 MapReduce 获取数据分片相关。















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









