









 博客介绍了学习图计算的原因,许多大数据以图形式呈现或会转换为图模型分析。阐述了图的基本概念,包括定义、术语和经典表示法。还介绍了Spark GraphX,其是Spark的分布式图计算API,有数据复用等特点,最后给出了在IDEA和虚拟机Spark - shell中的应用示例。
博客介绍了学习图计算的原因,许多大数据以图形式呈现或会转换为图模型分析。阐述了图的基本概念,包括定义、术语和经典表示法。还介绍了Spark GraphX,其是Spark的分布式图计算API,有数据复用等特点,最后给出了在IDEA和虚拟机Spark - shell中的应用示例。
引言:为什么要学计算
许多大数据以大规模图或网络的形式呈现
许多非图结构的大数据,常会被转换为图模型进行分析
图数据结构很好地表达了数据之间的关联性
一、图的基本概念
图是由顶点集合(vertex)及顶点间的关系集合(边edge)组成的一种网状数据结构
通常为二元组:Graph=(V,E)
可以对事物之间的关系建模
应用场景
在地图应用中寻找最短路径
社交网络关系
网页间超链接关系
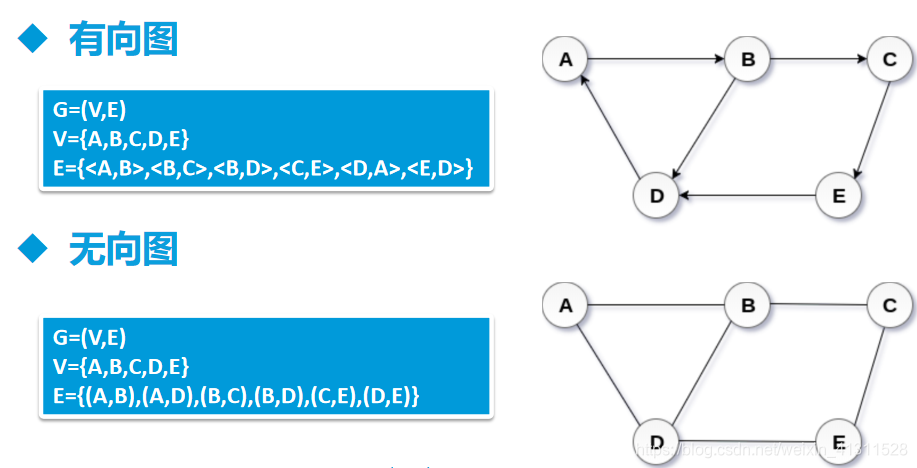
图的术语-1
顶点(Vertex)
边(Edge)
Graph=(V,E)
集合V={v1,v2,v3}
集合E={(v1,v2),(v1,v3),(v2,v3)}
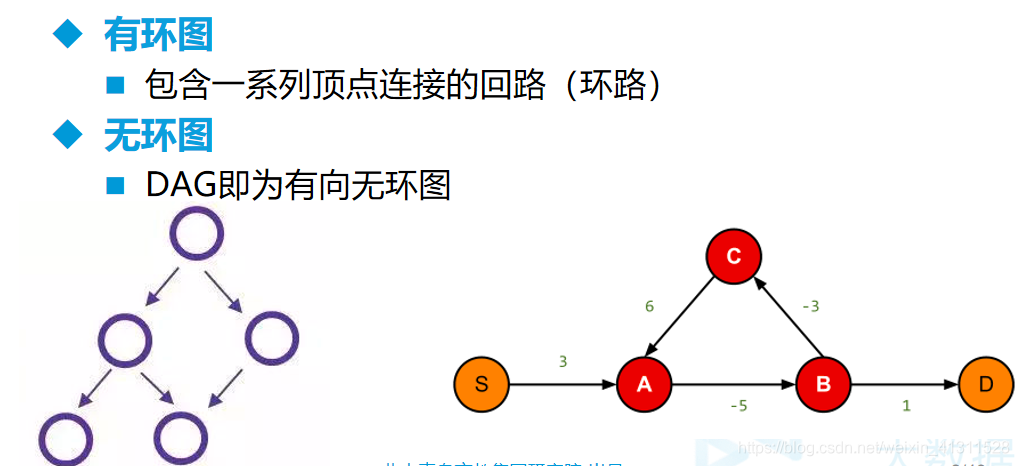
图的术语-2
图的术语-3
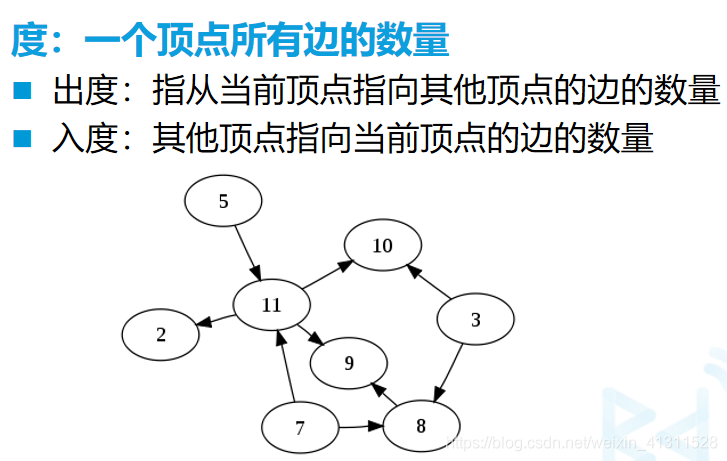
图的术语-4
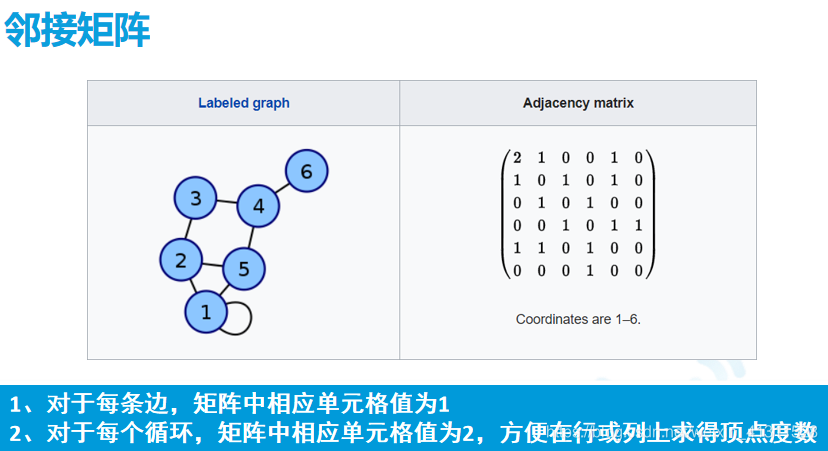
图的经典表示法
二、Spark GraphX简介
GraphX是Spark提供分布式图计算API
GraphX特点
基于内存实现了数据的复用与快速读取
通过弹性分布式属性图(Property Graph)统一了图视图与表视图
与Spark Streaming、Spark SQL和Spark MLlib等无缝衔接
三、 IDEA中应用示例
(1)
package cn.kgc.spark.graphX
import org.apache.spark.SparkContext
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* Created by wangchunhui on 2021/1/12 11:39
*/
object Demo01_CreateGraph {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getName)
.master("local[4]")
.getOrCreate()
// 创建SparkContext
val sc: SparkContext = spark.sparkContext
// 构建点集合的RDD
val vertices: RDD[(Long, Int)] = sc.makeRDD(Seq((1L,1),(2L,2),(3L,3)))
// 构建边集合的RDD
val edges: RDD[Edge[Int]] = sc.makeRDD(Seq(Edge(1L,2L,1),Edge(2L,3L,2)))
// 通过点集合和边集合构件图
val graph: Graph[Int, Int] = Graph(vertices,edges)
// 打印图的顶点, 顶点id-->顶点值
graph.vertices.foreach(x=>println(s"${x._1}-->${x._2}"))
// 打印图的边
graph.edges.foreach(x=>println(s"src:${x.srcId},dst:${x.dstId},attr:${x.attr}"))
// triplets带有属性的点和边
graph.triplets.foreach(x=>println(x.toString()))
}
}
(2)
package cn.kgc.spark.graphX
import org.apache.spark.SparkContext
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* Created by wangchunhui on 2021/1/12 11:57
*/
object Demo02_APPlication1 {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getName)
.master("local[4]")
.getOrCreate()
// 创建SparkContext
val sc: SparkContext = spark.sparkContext
// 构建用户的点集合
val users: RDD[(Long, (String, String))] = sc.parallelize(Array(
(3L, ("rxin", "student")),
(7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "professor")),
(2L, ("istoica", "professor"))
))
// 构建关系的边集合
val relationships: RDD[Edge[String]] = sc.parallelize(Array(
(Edge(3L, 7L, "collaborator")),
(Edge(5L, 3L, "advisor")),
(Edge(2L, 5L, "colleague")),
(Edge(5L, 7L, "PI"))
))
val graph = Graph(users,relationships)
// 打印图的顶点, 顶点id-->顶点值
graph.vertices.foreach(x=>println(s"${x._1}-->${x._2}"))
// 打印图的边
graph.edges.foreach(x=>println(s"src:${x.srcId},dst:${x.dstId},attr:${x.attr}"))
// triplets带有属性的点和边
graph.triplets.foreach(x=>println(x.toString()))
}
}
(3)
package cn.kgc.spark.graphX
import org.apache.spark.SparkContext
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* Created by wangchunhui on 2021/1/12 12:09
*/
object Demo03_Application2 {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getName)
.master("local[4]")
.getOrCreate()
// 创建SparkContext
val sc: SparkContext = spark.sparkContext
// 构建用户的点集合
val users: RDD[(Long, (String, Int))] = sc.parallelize(Array(
(1L, ("Alice", 28)),
(2L, ("Bob", 27)),
(3L, ("Charlie", 65)),
(4L, ("David", 42)),
(5L, ("Ed", 55)),
(6L, ("Fran", 50))
))
// 构建用户的边集合
val cntCall: RDD[Edge[Int]] = sc.parallelize(Array(
Edge(2L, 1L, 7),
Edge(2L, 4L, 2),
Edge(3L, 2L, 4),
Edge(3L, 6L, 3),
Edge(4L, 1L, 1),
Edge(5L, 2L, 2),
Edge(5L, 3L, 8),
Edge(5L, 6L, 3)
))
val graph = Graph(users, cntCall)
// 找出大于30岁的用户
println("大于30岁的用户为: ")
graph.vertices.filter { case (id, (name, age)) => age > 30 }.foreach(x=>println(x.toString()))
//graph.vertices.filter(_._2._2>30)
// 假设打call超过5次,表示真爱。请找出他(她)们
println("打call超过5次的为:")
graph.triplets.filter(_.attr>5).foreach(x=>println(s"${x.toString()}"))
}
}
四、在虚拟机Spark-shell中运行
scala> import org.apache.spark.SparkContext
import org.apache.spark.SparkContext
scala> import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.graphx.{Edge, Graph}
scala> import org.apache.spark.rdd.RDD
import org.apache.spark.rdd.RDD
scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession
scala> val users: RDD[(Long, (String, Int))] = sc.parallelize(Array(
| (1L, ("Alice", 28)),
| (2L, ("Bob", 27)),
| (3L, ("Charlie", 65)),
| (4L, ("David", 42)),
| (5L, ("Ed", 55)),
| (6L, ("Fran", 50))
| ))
users: org.apache.spark.rdd.RDD[(Long, (String, Int))] = ParallelCollectionRDD[0] at parallelize at <console>:28
scala> val cntCall: RDD[Edge[Int]] = sc.parallelize(Array(
| Edge(2L, 1L, 7),
| Edge(2L, 4L, 2),
| Edge(3L, 2L, 4),
| Edge(3L, 6L, 3),
| Edge(4L, 1L, 1),
| Edge(5L, 2L, 2),
| Edge(5L, 3L, 8),
| Edge(5L, 6L, 3)
| ))
cntCall: org.apache.spark.rdd.RDD[org.apache.spark.graphx.Edge[Int]] = ParallelCollectionRDD[1] at parallelize at <console>:28
scala> val graph = Graph(users, cntCall)
graph: org.apache.spark.graphx.Graph[(String, Int),Int] = org.apache.spark.graphx.impl.GraphImpl@10fef3d1
scala> graph.vertices.filter { case (id, (name, age)) => age > 30 }.foreach(x=>println(x.toString()))
[Stage 0:> (0 + 1) / 1[Stage 0:> (0 + 1) / 1][Stage 1:> (0 + 0) / 1](4,(David,42))
(6,(Fran,50))
(3,(Charlie,65))
(5,(Ed,55))
scala> graph.triplets.filter(_.attr>5).foreach(x=>println(s"${x.toString()}"))
((2,(Bob,27)),(1,(Alice,28)),7)
((5,(Ed,55)),(3,(Charlie,65)),8)
scala>

















 2606
2606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









