










学习致谢
https://www.bilibili.com/video/BV1Xz4y1m7cv?p=61
小节:
读:spark.read.格式(路径)//底层spark.read.format(“格式”).load(路径)
写:df.write…格式(路径) //df.write.format(“格式”).save(路径)


代码实现
package sql
import java.util.Properties
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}
/**
* Author itcast
* Desc 演示使用spark-SQL-支持的外部数据源
* 支持的文件格式:text/json/csv/parquet/orc...
* 支持文件系统/数据库
*/
object Demo06_DataSource{
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//TODO 1.加载数据
spark.read.text("data/input/text")
val df: DataFrame = spark.read.json("data/input/json")
df.printSchema()
df.show()
df//底层format("json").load(paths:_*)
spark.read.csv("data/input/csv")
//TODO 2.处理数据
//TODO 3.输出数据
df.coalesce(1).write.json("data/output/json")//底层 format("json").save(path)
df.coalesce(1).write.csv("data/output/json")
df.coalesce(1).write.parquet("data/output/parquet")
df.coalesce(1).write.orc("data/output/orc")
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
df.coalesce(1).write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/bigdata?characteEncoding=UTF-8","person",prop)
//TODO 4.关闭资源
spark.close()
}
}
补充
(1)查看json源码

查看内部方法的json

可以看到调用了load方法

(2)同样的查看保存时json的底层方法,调用了save()方法
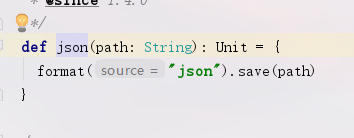
(3)mode
















 2500
2500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









