




一,使用pycharm创建项目
我创建的项目下只有两个文件,一个停分词文件,一个脚本代码文件
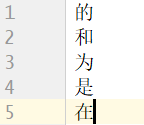
停分词文件(stopwords.txt):作用:在用jieba分词库对文件进行分词处理时,有些无用却频繁出现的分词,像“的”、“得”、“地”、“是”等,我们并不希望这些分词也被进行词频统计,因为统计这些分词没有什么意义,所以事先建立一个停分词文件,等会代码中利用这些停分词进行数据清洗
注意:文件中一个停分词必须按照独占一行的格式来写
二,全部代码如下:
import os
import os.path
import codecs
filePaths=[]
fileContents=[]
# c盘的Documents文件夹下放好自己要进行词频统计的txt文件
# os.walk()方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下
for root,dirs,files in os.walk('C:\\Documents'):
for name in files:
print(name)
filePath = os.path.join(root,name)
filePaths.append(filePath)
f=codecs.open(filePath,'r','utf-8')
fileContent =f.read()
f.close()
fileContents.append(fileContent)
# 数据清洗
Contents=""
for i in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9577
9577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









