






Pytorch学习(第一次打卡)
一、softmax算法
1.算法基本思路
实际上这个算法思路比较简单,也就是传统的线性模型做了变形而已,参数项仍是传统的{W,b},为了实现对多分类问题的预测按照分类的标签个数引入了不同的参数组{W(i),b(i)}(i=1,2,3…k k为分类个数),对于一个样本数据x,计算W(i)*x+b(i)=y(i),可以得出k个y(i)数据的值,比较最大就可以判断x究竟属于哪一类。
然而上述算法以下问题:
1.上述算法计算的线性值没有实际意义,会出现负数的情况,不利于计算相应的损失函数
为解决上述问题只需作如下变化即可
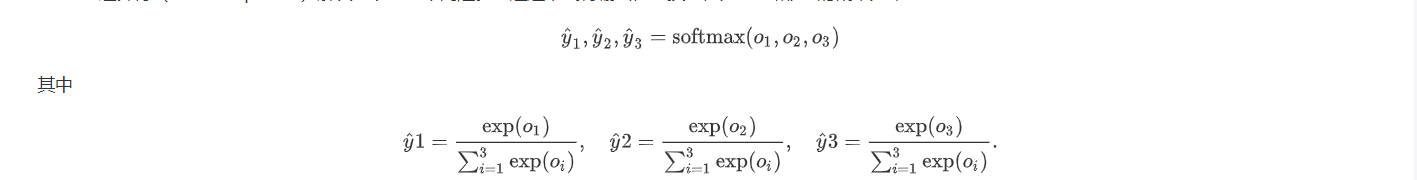
即exp(y(i))之后再次进行归一化,得到的每个值可以理解为概率
2.损失函数计算
有两种损失函数可以考虑进来,传统的线性回归用的平方损失函数,假设总类数有三类,观测结果表明o1=0,o2=0,o3=1即判别为第三类,而实际上我们计算的值这三个值,若分别为0.2,0.2,0.6,这与0.4,0,0.6计算结果不同,因此应该换一种计算损失函数的方式,改善上述问题的一个方法是使用更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:
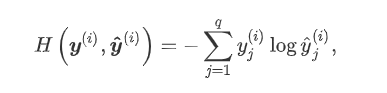
这个公式在决策树相关章节也会碰到,类似于信息熵,这么变幻的好处是,计算的损失函数值关注在预测类别正确与否而不用考虑未分类正确的其他种类的输出值。
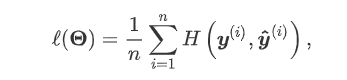
3. 梯度下降法迭代更新相关参数
有了损失函数,在设立初值之后就可以按照梯度下降法更新相关参数这里就不赘述了















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









