







DeepFM 出自 IJCAI 2017 的论文 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction。
1. 背景
CTR (click-through rate) 预测,是指预测用户对某个物品的点击率,以便于推送用户最有可能点击的物品。广告平台当然希望有一个模型能够准确预测出用户最可能点击的广告,这样可以增加平台收益;在电商的推荐系统中,需要把用户可能感兴趣的商品从前到后的展示出来,这个顺序就是按照用户点击这个商品的概率从大到小排列出来的。
预测点击概率需要用到用户信息和物品信息,通常是将多种信息融合在一个向量中。离散的用户和物品的属性,就采用 one-hot 表示,连续的属性可以归一化后直接使用。训练样本为 (x,y),其中 x 是一个高维稀疏矩阵,其中包含 user 和 item 的信息,y∈{0,1} 表示用户是否点击了 item。
特征间的组合常常很有用,比如从用户点击数据中发现在吃饭的时间用户常常下载点外卖的软件,这说明 time 和 app category 有很大关系,这样可以构建一个特征 "time = 中午 & spp category = 外卖"。另外可能在数据中发现男孩子常常玩射击类游戏,这也可以构造特征 “gender = 男 & game category = 射击”。
要从数据中捕获以上提到的特征,需要模型能够组合不同的特征。为此人们做了特征工程,向线性模型中加入 这样的组合特征. 为了解决组合特征参数过多的问题,提出了 Factorization Machines。
但是 FM 因为计算量的问题也常常只能引入二阶特征(两个特征的组合),为了能够引入更加强大的特征组合。Wide & Deep 模型被提出,结合线性模型和深度神经网络,试图让模型学习到更加复杂的特征。
本文的 DeepFM 和 Wide & Deep 的动机,我感觉是差不多的,只是 DeepFM 提出了一种看起来更加简洁的模型。
2. DeepFM
DeepFM 的模型架构图如下:

单看此图肯定时看不明白的,稍加解释如下:
2.1 Sparse Features
 首先是最底下这一部分,可以看到field这个名词,这是因为在处理特征时候,我们需要对离散型数据进行one-hot转化,经过one-hot之后一列会变成多列,这样会导致特征矩阵变得非常稀疏。为了应对这一问题,我们把进行one-hot之前的每个特征都看作一个field,这样做的原因是为了在进行矩阵存储时候,我们可以把对一个大稀疏矩阵的存储,转换成对两个小矩阵 和 一个字典的存储。 (这个是deepFM最难理解的地方)
首先是最底下这一部分,可以看到field这个名词,这是因为在处理特征时候,我们需要对离散型数据进行one-hot转化,经过one-hot之后一列会变成多列,这样会导致特征矩阵变得非常稀疏。为了应对这一问题,我们把进行one-hot之前的每个特征都看作一个field,这样做的原因是为了在进行矩阵存储时候,我们可以把对一个大稀疏矩阵的存储,转换成对两个小矩阵 和 一个字典的存储。 (这个是deepFM最难理解的地方)
2.1.1 一个字典
为离散型特征每个特征的可能值都添加索引,对连续数据只给予一个特征索引,这样我们不必存储离散特征的onehot表示,而只需要存储离散特征值对应在字典中的编号就行了,用编号作为特征标识。
{'missing_feat': 0, 'ps_car_01_cat': {10: 1, 11: 2, 7: 3, 6: 4, 9: 5, 5: 6, 4: 7, 8: 8, 3: 9, 0: 10, 2: 11, 1: 12, -1: 13}, 'ps_car_02_cat': {1: 14, 0: 15}
missing_feat是个连续型特征,其特征编号为0. ps_car_01_cat 是个离散型特征,有12种可能的取值,特征编号为1~13.例如,当ps_car_01_cat取11时,其特征编号为2.
2.1.2 第一个小矩阵
第一个小矩阵是特征索引矩阵。如下是对其中两个样本的特征索引的打印,发现每个样本都有40个特征(长度为40)。这里说的“特征”,实际上是field。举个例子,180可能表示‘性别为男’、181表示‘性别为女’,在如下的例子中,第一列就是代表“性别”这个field。
[180, 186, 200, 202, 205, 213, 215, 217, 219, 221, 223, 225, 227, 229, 235, 248, 250, 251, 253, 254, 255, 3, 14, 16, 19, 30, 40, 50, 54, 56, 61, 147, 66, 172, 173, 175, 176, 0, 174]
[181, 185, 190, 202, 205, 213, 216, 217, 220, 221, 223, 225, 227, 229, 242, 248, 250, 251, 253, 254, 255, 7, 14, 16, 19, 31, 33, 50, 54, 55, 61, 79, 66, 172, 173, 175, 176, 0, 174]2.1.3 第二个小矩阵
第二个小矩阵是特征的值的矩阵,这里的特征值是和上面的特征索引矩阵相对应的,存储对应索引位置含义的特征的值,以下是两个样本的特征值的例子,可以发现在离散特征值都是为1的,这是因为我们只记录了样本对应的离散特征的索引,所以肯定是为1的,不可能为0。连续的特征值就是一个实数。
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.5, 0.3, 0.6103277807999999, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.316227766, 0.6695564092, 0.3521363372, 3.4641016150999997, 2.0, 0.4086488773474527],
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.9, 0.5, 0.7713624309999999, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.316227766, 0.6063200202000001, 0.3583294573, 2.8284271247, 1.0, 0.4676924847454411]经过以上过程,我们可以将原样本都转换成上面的两个小矩阵,并保留了特征索引字典,这样相对于对原始特征做了one-hot的转换,只不过用了一种特征抗稀疏化的方式,原来特征的长度是field_size个,现在one-hot后的特征长度也是field_size个,只不过可以假定为 feature_size个(应该的one-hot过的长度),因为我们之后会对每个离散特征值 跟 连续特征一起做处理。
对应看图中,每个连续型特征都可以对应为一个点,而每个离散特征(一个field)做one-hot之后根据其具有不同值的数量n可以对应n个点,其中有且只有一个点是1,其它点都是0.
2.2 Dense Embedding

FM 模型会对每一个特征(field)学习到一个低维的稠密向量,可以视为特征的 Embedding。之后的FM(左边的部分)和Deep(右边的部分)都是共享这里的embedding结果的。
2.3 Factorization Machine Layers

其中,![]() 是FM的一阶计算部分,直接对原始特征做的一阶计算,其权重就是一阶权重
是FM的一阶计算部分,直接对原始特征做的一阶计算,其权重就是一阶权重.
![]() 对应FM的二阶计算阶段,对经过embedding的结果做二阶交叉计算,其权重为
对应FM的二阶计算阶段,对经过embedding的结果做二阶交叉计算,其权重为
FM计算的公式如下:
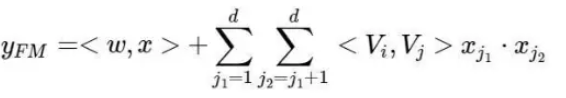
2.4 Hidden Layer

深度模型的输入为:
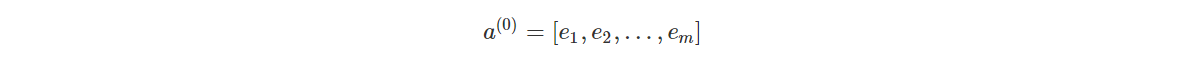
其中就是第 Field i 对应的 Dense Embedding,不同 Field 的 Embedding 拼接起来得到一个稠密向量,输入到全连接的神经网络中。神经网络模型可以表示为:
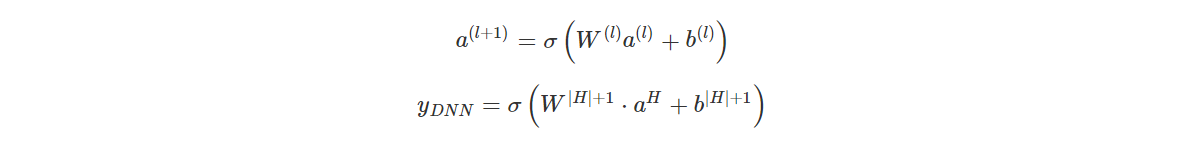
最终整个 DeepFM 模型可以表示为:
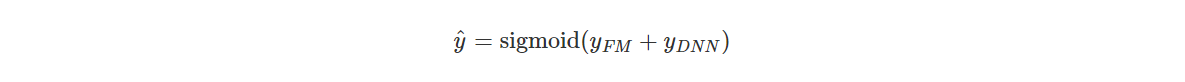
整个模型的权重:
具体计算时,主要涉及四个权重(embedding_size是进行embeding转化时指定的大小)
- weights['feature_bias']:维度是 [self.feature_size,1]。对应FM公式中的一维计算部分,就是每个feature相加的权重
- weights['feature_embeddings'] :维度是[self.feature_size,self.embedding_size]。这里表示存储对每个feature的embedding表示,用它来计算FM公式的二阶计算部分权重
- weights['layer_0']:维度是(上一层神经元树量,当前层神经元数量),对应deep部分神经元的权重部分
- weights['bias_0']:维度是(1,当前层神经元数量),对应深度计算的偏置部分。















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









