







一、赛题
赛题地址:https://www.sodic.com.cn/competitions/900010
赛题背景: 企业自主填报安全生产隐患,对于将风险消除在事故萌芽阶段具有重要意义。企业在填报隐患时,往往存在不认真填报的情况,“虚报、假报”隐患内容,增大了企业监管的难度。采用大数据手段分析隐患内容,找出不切实履行主体责任的企业,向监管部门进行推送,实现精准执法,能够提高监管手段的有效性,增强企业安全责任意识。
赛题任务: 本赛题提供企业填报隐患数据,参赛选手需通过智能化手段识别其中是否存在“虚报、假报”的情况。
二、解决方法
该赛题抽象成模型问题,总体来看是一个文本分类任务,下面主要采取baseline、nlp传统模型、nlp深度模型以及一些前沿的方法进行提升。
一、baseline模型
# baseline 方法 (albert)
# encoding = 'utf-8'
import random
import numpy as np
import pandas as pd
from bert4keras.backend import keras,set_gelu
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam,extend_with_piecewise_linear_lr
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import open
from keras.layers import Lambda, Dense
# 相关参数及预训练模型
set_gelu("tanh")
num_classes = 2
maxlen = 128
batch_size = 32
config_path = "../model/albert_small_zh_google/albert_config_small_google.json"
checkpoint_path = '../model/albert_small_zh_google/albert_model.ckpt'
dict_path = '../model/albert_small_zh_google/vocab.txt'
# 建立分词器
tokenizer = Tokenizer(dict_path, do_lower_case=True)
# 定义模型
bert = build_transformer_model(config_path=config_path,
checkpoint_path=checkpoint_path,
model='albert',
return_keras_model=False)
output = Lambda(lambda x: x[:,0], name='CLS-token')(bert.model.output)
output = Dense(units=num_classes,activation='softmax',kernel_initializer=bert.initializer)(output)
model = keras.models.Model(bert.model.input, output)
model.compile(loss='sparse_categorical_crossentropy',optimizer=Adam(1e-5),metrics=['accuracy'])
# 加载数据与处理
df_train_data = pd.read_csv("../data/train.csv")
df_test_data = pd.read_csv("../data/test.csv")
train_data, valid_data, test_data = [], [], []
valid_rate = 0.3
for row_i, data in df_train_data.iterrows():
id, level_1, level_2, level_3, level_4, content, label = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + str(level_3) + '\t' + str(level_4) + '\t' + str(content), label
if random.random() > valid_rate:
train_data.append((id,text,int(label)))
else:
valid_data.append((id,text,int(label)))
for row_i, data in df_test_data.iterrows():
id, level_1, level_2, level_3, level_4, content = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + str(level_3) + '\t' + str(level_4) + '\t' + str(content), 0
test_data.append((id, text, int(label)))
# 定义data_generator
class data_generator(DataGenerator):
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end,(id, text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
# 转换数据集
train_generator = data_generator(train_data, batch_size)
valid_generator = data_generator(valid_data, batch_size)
# 评估与保存
class Evaluator(keras.callbacks.Callback):
def __init__(self):
self.best_val_acc = 0.
def on_epoch_end(self, epoch, logs=None):
val_acc = evaluate(valid_generator)
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
model.save_weights('best_model.weights')
test_acc = evaluate(valid_generator)
print(
u'val_acc: %.5f, best_val_acc: %.5f, test_acc: %.5f\n' %
(val_acc, self.best_val_acc, test_acc)
)
# 训练和验证
evaluator = Evaluator()
# 训咯模型
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=10,
callbacks=[evaluator]
)
# 加载模型
model.load_weights("best_model.weights")
print(u"final test acc: %05f\n" % (evaluate(valid_generator)))
# 评价指标
def data_pred(test_data):
id_ids, y_pred_ids = [], []
for id, text, label in test_data:
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
token_ids = sequence_padding([token_ids])
segment_ids = sequence_padding([segment_ids])
y_pred = int(model.predict([token_ids, segment_ids]).argmax(axis=1)[0])
id_ids.append(id)
y_pred_ids.append(y_pred)
return id_ids, y_pred_ids
# 模型预测及保存结果
id_ids, y_pred_ids = data_pred(test_data)
df_save = pd.DataFrame()
df_save['id'] = id_ids
df_save['label'] = y_pred_ids
# 结果打印
df_save.head()
id label
0 0 0
1 1 0
2 2 1
3 3 0
4 4 0
二、NLP经典模型
""" tf-idf """
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
import lightgbm as lgb
base_dir = "../"
train = pd.read_csv(base_dir + "train.csv")
test = pd.read_csv(base_dir + "test.csv")
results = pd.read_csv(base_dir + "results.csv")
# 数据去重
train = train.drop_duplicates(['level_1', 'level_2', 'level_3', 'level_4', 'content', 'label'])
train['text'] = (train['content']).map(lambda x:' '.join(list(str(x))))
test['text'] = (test['content']).map(lambda x:' '.join(list(str(x))))
vectorizer = TfidfVectorizer(analyzer='char')
train_X = vectorizer.fit_transform(train['text']).toarray()
test_X = vectorizer.transform(test['text']).toarray()
train_y = train['label'].astype(int).values
# 参数
params = {
'task':'train',
'boosting_type':'gbdt',
'num_leaves': 31,
'objective': 'binary',
'learning_rate': 0.05,
'bagging_freq': 2,
'max_bin':256,
'num_threads': 32,
# 'metric':['binary_logloss','binary_error']
}
skf = StratifiedKFold(n_splits=5)
for index,(train_index, test_index) in enumerate(skf.split(train_X, train_y)):
X_train, X_test = train_X[train_index], train_X[test_index]
y_train, y_test = train_y[train_index], train_y[test_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(params,
lgb_train,
num_boost_round=1000,
valid_sets=lgb_eval,
early_stopping_rounds=10)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
pred = gbm.predict(test_X, num_iteration=gbm.best_iteration)
if index == 0:
pred_y_check, true_y_check = list(y_pred), list(y_test)
pred_out=pred
else:
pred_y_check += list(y_pred)
true_y_check += list(y_test)
pred_out += pred
#验证
for i in range(10):
pred = [int(x) for x in np.where(np.array(pred_y_check) >= i/10.0,1,0)]
scores = f1_score(true_y_check,pred)
print(i, scores)
""" n-gram模型 """
# encoding='utf-8'
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
import lightgbm as lgb
# 读取数据
base_dir = "../"
train = pd.read_csv(base_dir + "train.csv")
test = pd.read_csv(base_dir + "test.csv")
results = pd.read_csv(base_dir + "results.csv")
train = train.drop_duplicates(['level_1', 'level_2', 'level_3', 'level_4', 'content', 'label'])
# 构建特征
train['text'] = (train['content']).map(lambda x:' '.join(list(str(x))))
test['text'] = (test['content']).map(lambda x:' '.join(list(str(x))))
vectorizer = CountVectorizer(analyzer='char', ngram_range=(1, 3), stop_words=[])
train_X = vectorizer.fit_transform(train['text']).toarray()
test_X = vectorizer.transform(test['text']).toarray()
train_y = train['label'].astype(int).values
# 交叉验证,训练模型
params = {
'task':'train',
'boosting_type':'gbdt',
'num_leaves': 31,
'objective': 'binary',
'learning_rate': 0.05,
'bagging_freq': 2,
'max_bin':256,
'num_threads': 32,
# 'metric':['binary_logloss','binary_error']
}
skf = StratifiedKFold(n_splits=5)
for index,(train_index, test_index) in enumerate(skf.split(train_X, train_y)):
X_train, X_test = train_X[train_index], train_X[test_index]
y_train, y_test = train_y[train_index], train_y[test_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(params,
lgb_train,
num_boost_round=1000,
valid_sets=lgb_eval,
early_stopping_rounds=10)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
pred = gbm.predict(test_X, num_iteration=gbm.best_iteration)
if index == 0:
pred_y_check, true_y_check = list(y_pred), list(y_test)
pred_out=pred
else:
pred_y_check += list(y_pred)
true_y_check += list(y_test)
pred_out += pred
# 验证
for i in range(10):
pred = [int(x) for x in np.where(np.array(pred_y_check) >= i/10.0,1,0)]
scores = f1_score(true_y_check,pred)
print(i, scores)"""word2vec"""
import pandas as pd
import numpy as np
import jieba
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
from gensim.models import Word2Vec
# 读取数据
base_dir = "../"
train = pd.read_csv(base_dir + "train.csv")
test = pd.read_csv(base_dir + "test.csv")
results = pd.read_csv(base_dir + "results.csv")
# 训练集去重
train = train.drop_duplicates(['level_1', 'level_2', 'level_3', 'level_4', 'content', 'label'])
# 构建特征,使用word2vec
train['text'] = (train['content']).map(lambda x:' '.join(jieba.cut(str(x))))
test['text'] = (test['content']).map(lambda x:' '.join(jieba.cut(str(x))))
model_word = Word2Vec(train['text'].values.tolist(), size=100, window=5, min_count=1, workers=4)
def get_vec(word_list, model):
init = np.array([0.0]*100)
index = 0
for word in word_list:
if word in model.wv:
init += np.array(model.wv[word])
index += 1
if index == 0:
return init
return list(init / index)
# 向量取平均值
train['vec'] = train['text'].map(lambda x: get_vec(x, model_word))
test['vec'] = test['text'].map(lambda x: get_vec(x, model_word))
train_X = np.array(train['vec'].values.tolist())
test_X = np.array(test['vec'].values.tolist())
train_y = train['label'].astype(int).values
# 交叉验证
params = {
'task':'train',
'boosting_type':'gbdt',
'num_leaves': 31,
'objective': 'binary',
'learning_rate': 0.05,
'bagging_freq': 2,
'max_bin':256,
'num_threads': 32,
# 'metric':['binary_logloss','binary_error']
}
skf = StratifiedKFold(n_splits=5)
for index,(train_index, test_index) in enumerate(skf.split(train_X, train_y)):
X_train, X_test = train_X[train_index], train_X[test_index]
y_train, y_test = train_y[train_index], train_y[test_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(params,
lgb_train,
num_boost_round=1000,
valid_sets=lgb_eval,
early_stopping_rounds=10)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
pred = gbm.predict(test_X, num_iteration=gbm.best_iteration)
if index == 0:
pred_y_check, true_y_check = list(y_pred), list(y_test)
pred_out=pred
else:
pred_y_check += list(y_pred)
true_y_check += list(y_test)
pred_out += pred
# 验证
for i in range(10):
pred = [int(x) for x in np.where(np.array(pred_y_check) >= i/10.0,1,0)]
scores = f1_score(true_y_check,pred)
print(i/10.0, scores)
三、NLP深度模型
"""TextCNN"""
import random
import numpy as np
import pandas as pd
from bert4keras.backend import keras, set_gelu
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam, extend_with_piecewise_linear_lr
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import open
from keras.layers import *
import tensorflow as tf
set_gelu('tanh') # 切换gelu版本
num_classes = 2
maxlen = 128
batch_size = 32
config_path = '../model/albert_small_zh_google/albert_config_small_google.json'
checkpoint_path = '../model/albert_small_zh_google/albert_model.ckpt'
dict_path = '../model/albert_small_zh_google/vocab.txt'
# 建立分词器
tokenizer = Tokenizer(dict_path, do_lower_case=True)
# 加载bert模型
# 加载预训练模型
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
model='albert',
return_keras_model=False,
)
# keras辅助函数
expand_dims = Lambda(lambda X: tf.expand_dims(X,axis=-1))
max_pool = Lambda(lambda X: tf.squeeze(tf.reduce_max(X,axis=1),axis=1))
concat = Lambda(lambda X: tf.concat(X, axis=-1))
# 获取bert的char embedding
cnn_input = expand_dims(bert.layers['Embedding-Token'].output)
# 定义cnn网络
filters = 2
sizes = [3,5,7,9]
output = []
for size_i in sizes:
X = Conv2D(filters=2,
kernel_size=(size_i, 128),
activation='relu',
)(cnn_input)
X = max_pool(X)
output.append(X)
cnn_output = concat(output)
# 分类全连接
output = Dense(
units=num_classes,
activation='softmax'
)(cnn_output)
# 定义模型输入输出
model = keras.models.Model(bert.model.input[0], output)
# 编译模型
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(1e-5),
metrics=['accuracy'],
)
# 加载数据
def load_data(valid_rate=0.3):
train_file = "../data/train.csv"
test_file = "../data/test.csv"
df_train_data = pd.read_csv("../data/train.csv").\
drop_duplicates(['level_1', 'level_2', 'level_3', 'level_4', 'content', 'label'])
df_test_data = pd.read_csv("../data/test.csv")
train_data, valid_data, test_data = [], [], []
for row_i, data in df_train_data.iterrows():
id, level_1, level_2, level_3, level_4, content, label = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), label
if random.random() > valid_rate:
train_data.append( (id, text, int(label)) )
else:
valid_data.append( (id, text, int(label)) )
for row_i, data in df_test_data.iterrows():
id, level_1, level_2, level_3, level_4, content = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), 0
test_data.append( (id, text, int(label)) )
return train_data, valid_data, test_data
train_data, valid_data, test_data = load_data(valid_rate=0.3)
# 迭代器生成
class data_generator(DataGenerator):
def __iter__(self, random=False):
batch_token_ids, batch_labels = [], []
for is_end, (id, text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids], batch_labels
batch_token_ids, batch_labels = [], []
train_generator = data_generator(train_data, batch_size)
valid_generator = data_generator(valid_data, batch_size)
# 训练验证和预测
def evaluate(data):
total, right = 0., 0.
for x_true, y_true in data:
y_pred = model.predict(x_true).argmax(axis=1)
y_true = y_true[:, 0]
total += len(y_true)
right += (y_true == y_pred).sum()
return right / total
class Evaluator(keras.callbacks.Callback):
def __init__(self):
self.best_val_acc = 0.
def on_epoch_end(self, epoch, logs=None):
val_acc = evaluate(valid_generator)
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
model.save_weights('best_model.weights')
test_acc = evaluate(valid_generator)
print(
u'val_acc: %.5f, best_val_acc: %.5f, test_acc: %.5f\n' %
(val_acc, self.best_val_acc, test_acc)
)
def data_pred(test_data):
id_ids, y_pred_ids = [], []
for id, text, label in test_data:
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
token_ids = sequence_padding([token_ids])
y_pred = int(model.predict([token_ids]).argmax(axis=1)[0])
id_ids.append(id)
y_pred_ids.append(y_pred)
return id_ids, y_pred_ids
# 训练和验证模型
evaluator = Evaluator()
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=1,
callbacks=[evaluator]
)
# 加载最好的模型
model.load_weights('best_model.weights')
# 验证集结果
print(u'final test acc: %05f\n' % (evaluate(valid_generator)))
# 训练集结果
print(u'final test acc: %05f\n' % (evaluate(train_generator)))
# 模型预测保存结果
id_ids, y_pred_ids = data_pred(test_data)
df_save = pd.DataFrame()
df_save['id'] = id_ids
df_save['label'] = y_pred_ids
df_save.to_csv('result.csv')
"""Bi-LSTM"""
import random
import numpy as np
import pandas as pd
from bert4keras.backend import keras, set_gelu
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam, extend_with_piecewise_linear_lr
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import open
from keras.layers import *
import tensorflow as tf
set_gelu('tanh') # 切换gelu版本
num_classes = 2
maxlen = 128
batch_size = 32
config_path = '../model/albert_small_zh_google/albert_config_small_google.json'
checkpoint_path = '../model/albert_small_zh_google/albert_model.ckpt'
dict_path = '../model/albert_small_zh_google/vocab.txt'
# 建立分词器
tokenizer = Tokenizer(dict_path, do_lower_case=True)
# 加载预训练模型
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
model='albert',
return_keras_model=False,
)
lstm_input = bert.layers['Embedding-Token'].output
X = Bidirectional(LSTM(128, return_sequences=True))(lstm_input)
lstm_output = Bidirectional(LSTM(128))(X)
output = Dense(
units=num_classes,
activation='softmax'
)(lstm_output)
model = keras.models.Model(bert.model.input[0], output)
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(1e-5),
metrics=['accuracy'],
)
def load_data(valid_rate=0.3):
train_file = "../data/train.csv"
test_file = "../data/test.csv"
df_train_data = pd.read_csv("../data/train.csv").\
drop_duplicates(['level_1', 'level_2', 'level_3', 'level_4', 'content', 'label'])
df_test_data = pd.read_csv("../data/test.csv")
train_data, valid_data, test_data = [], [], []
for row_i, data in df_train_data.iterrows():
id, level_1, level_2, level_3, level_4, content, label = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), label
if random.random() > valid_rate:
train_data.append( (id, text, int(label)) )
else:
valid_data.append( (id, text, int(label)) )
for row_i, data in df_test_data.iterrows():
id, level_1, level_2, level_3, level_4, content = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), 0
test_data.append( (id, text, int(label)) )
return train_data, valid_data, test_data
train_data, valid_data, test_data = load_data(valid_rate=0.3)
class data_generator(DataGenerator):
def __iter__(self, random=False):
batch_token_ids, batch_labels = [], []
for is_end, (id, text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids], batch_labels
batch_token_ids, batch_labels = [], []
train_generator = data_generator(train_data, batch_size)
valid_generator = data_generator(valid_data, batch_size)
def evaluate(data):
total, right = 0., 0.
for x_true, y_true in data:
y_pred = model.predict(x_true).argmax(axis=1)
y_true = y_true[:, 0]
total += len(y_true)
right += (y_true == y_pred).sum()
return right / total
class Evaluator(keras.callbacks.Callback):
def __init__(self):
self.best_val_acc = 0.
def on_epoch_end(self, epoch, logs=None):
val_acc = evaluate(valid_generator)
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
model.save_weights('best_model.weights')
test_acc = evaluate(valid_generator)
print(
u'val_acc: %.5f, best_val_acc: %.5f, test_acc: %.5f\n' %
(val_acc, self.best_val_acc, test_acc)
)
def data_pred(test_data):
id_ids, y_pred_ids = [], []
for id, text, label in test_data:
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
token_ids = sequence_padding([token_ids])
y_pred = int(model.predict([token_ids]).argmax(axis=1)[0])
id_ids.append(id)
y_pred_ids.append(y_pred)
return id_ids, y_pred_ids
evaluator = Evaluator()
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=1,
callbacks=[evaluator]
)
model.load_weights('best_model.weights')
print(u'final test acc: %05f\n' % (evaluate(valid_generator)))
print(u'final test acc: %05f\n' % (evaluate(train_generator)))
id_ids, y_pred_ids = data_pred(test_data)
df_save = pd.DataFrame()
df_save['id'] = id_ids
df_save['label'] = y_pred_ids
df_save.to_csv('result.csv')
最终结果: 开始的时候提交几版,后来没有时间优化也就不了了之啦
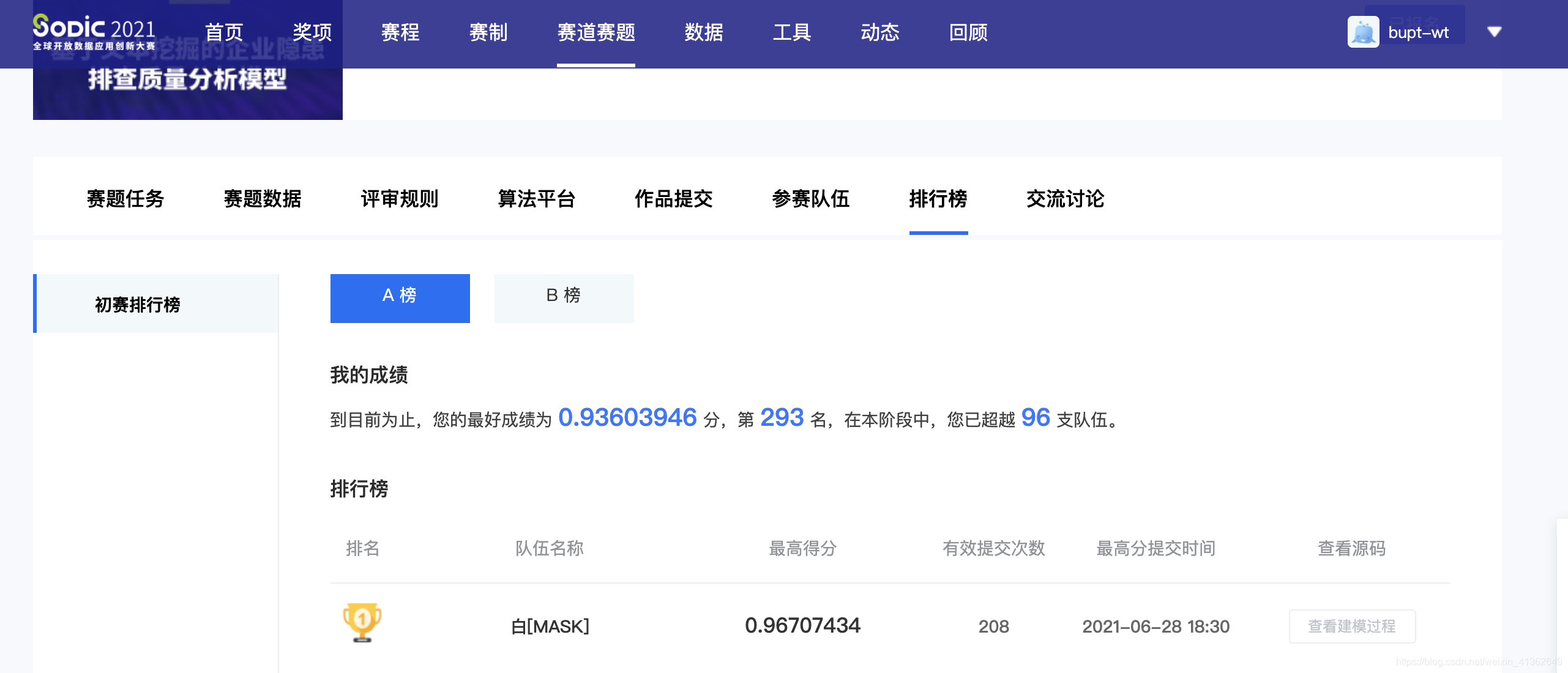
注:
相关资料链接:
1. 北大分词库地址: http://sighan.cs.uchicago.edu/bakeoff2005/
2. 腾讯词向量: https://ai.tencent.com/ailab/nlp/zh/embedding.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









