






一、文档信息抽取
信息抽取通俗地说就是从给定的文本/图片等输入数据中抽取出结构化信息的过程。在信息抽取的落地过程中通常面临领域多变、任务多样、数据稀缺等许多挑战。针对信息抽取领域的难点和痛点,PaddleNLP信息抽取应用UIE统一建模的思想,提供了文档信息抽取产业级应用方案,支持文档/图片/表格和纯文本场景下实体、关系、事件、观点等不同任务信息抽取。该应用不限定行业领域和抽取目标,可实现从产品原型研发、业务POC阶段到业务落地、迭代阶段的无缝衔接,助力开发者实现特定领域抽取场景的快速适配与落地。
文档信息抽取应用亮点:
覆盖场景全面🎓: 覆盖文档信息抽取各类主流任务,支持多语言,满足开发者多样信息抽取落地需求。
效果领先🏃: 以在多模态信息抽取上有突出效果的模型UIE-X作为训练基座,具有广泛成熟的实践应用性。
简单易用⚡: 通过Taskflow实现三行代码可实现无标注数据的情况下进行快速调用,一行命令即可开启信息抽取训练,轻松完成部署上线,降低信息抽取技术落地门槛。
高效调优✊: 开发者无需机器学习背景知识,即可轻松上手数据标注及模型训练流程。
使用版本:
paddle-bfloat 0.1.7
paddle2onnx 1.1.0
paddlefsl 1.1.0
paddlenlp 2.7.1
paddleocr 2.7.0.3
paddlepaddle 2.6.0
pandas 1.3.5
label-studio 1.11.0
label-studio-tools 0.0.3
1.1 代码结构
.
├── deploy # 部署目录
│ └── simple_serving # 基于PaddleNLP SimpleServing 服务化部署
├── utils.py # 数据处理工具
├── finetune.py # 模型微调、压缩脚本
├── evaluate.py # 模型评估脚本
└── README.md
2.2 数据标注
2.2.1 安装
以下标注示例用到的环境配置:
Python 3.8+
label-studio == 1.6.0 --因为运行过程中报错,升级版本至1.11.0
paddleocr >= 2.6.0.1 --因为运行过程中报错,升级版本至2.7.0.3
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.11.0
安装完成后,运行以下命令行:
/root/.pyenv/versions/3.8.16/bin/python /root/.pyenv/versions/3.8.16/bin/label-studio start -p 8082 --username *** --password ***
在浏览器打开 http://*****:8082/projects/?page=1,输入用户名和密码登录,开始使用label-studio进行标注。
2.2.2 文档抽取任务标注
具体操作步骤查看:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/applications/information_extraction/label_studio_doc.md
2.2.3 数据导出
勾选已标注图片ID,选择导出的文件类型为JSON,导出数据:

备注:1. 针对上传的文档文件名,不能含中文名
2. 对导出的json文件,需要修改一下内容其中key值:将ocr 修改为image ,否则后续运行的时候会报错,可能是官方代码各个版本造成的问题
3. 修改代码:/usr/local/lib/python3.10/dist-packages/paddlenlp/utils/tools.py 400行和416行 rectanglelabels 修改为labels
2.3 数据转换
将导出的文件重命名为label_studio.json后,放入./document/data目录下,并将对应的标注图片放入./document/data/images目录下(图片的文件名需与上传到label studio时的命名一致)。通过label_studio.py脚本可转为UIE的数据格式。
路径示例
./document/data/
├── images # 图片目录
│ ├── b0.jpg # 原始图片(文件名需与上传到label studio时的命名一致)
│ └── b1.jpg
└── label_studio.json # 从label studio导出的标注文件
抽取式任务
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--save_dir ./data \
--splits 0.8 0.1 0.1\
--task_type ext
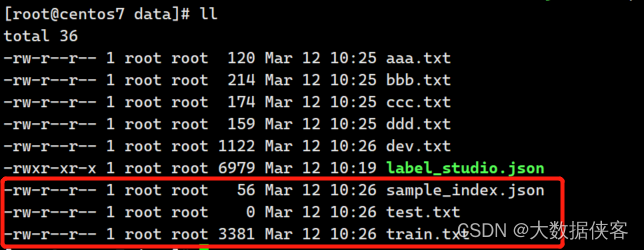
执行之后会产生多个文件:dev.txt sample_index.json test.txt train.txt
2.4 模型微调
python finetune.py \
--device gpu \
--logging_steps 5 \
--save_steps 25 \
--eval_steps 25 \
--seed 42 \
--model_name_or_path uie-x-base \
--output_dir ./checkpoint/model_best \
--train_path data/train.txt \
--dev_path data/dev.txt \
--max_seq_len 512 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--num_train_epochs 10 \
--learning_rate 1e-5 \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
可配置参数说明:
device: 训练设备,可选择 ‘cpu’、‘gpu’、‘npu’ 其中的一种;默认为 GPU 训练。
logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。
save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。
eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。
seed:全局随机种子,默认为 42。
model_name_or_path:进行 few shot 训练使用的预训练模型。默认为 “uie-x-base”。
output_dir:必须,模型训练或压缩后保存的模型目录;默认为 None 。
train_path:训练集路径;默认为 None 。
dev_path:开发集路径;默认为 None 。
max_seq_len:文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
per_device_train_batch_size:用于训练的每个 GPU 核心/NPU 核心/CPU 的batch大小,默认为8。
per_device_eval_batch_size:用于评估的每个 GPU 核心/NPU 核心/CPU 的batch大小,默认为8。
num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。
learning_rate:训练最大学习率,UIE-X 推荐设置为 1e-5;默认值为3e-5。
label_names:训练数据标签label的名称,UIE-X 设置为’start_positions’ ‘end_positions’;默认值为None。
do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。
do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。
do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。
export_model_dir:静态图导出地址,默认为None。
overwrite_output_dir: 如果 True,覆盖输出目录的内容。如果 output_dir 指向检查点目录,则使用它继续训练。
disable_tqdm: 是否使用tqdm进度条。
metric_for_best_model:最优模型指标,UIE-X 推荐设置为 eval_f1,默认为None。
load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。
save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints 输出目录,默认为None。
2.5 模型评估–非必要
2.6 定制模型一键预测
from pprint import pprint
from paddlenlp import Taskflow
from paddlenlp.utils.doc_parser import DocParser
schema = ['开票日期', '名称', '纳税人识别号', '开户行及账号', '金额', '价税合计', 'No', '税率', '地址、电话', '税额']
my_ie = Taskflow("information_extraction", model="uie-x-base", schema=schema, task_path='./checkpoint/model_best', precision='fp16')
doc_path = "./data/images/b199.jpg"
results = my_ie({"doc": doc_path})
pprint(results)
# 结果可视化
DocParser.write_image_with_results(
doc_path,
result=results[0],
save_path="./image_show.png")
二、文本信息抽取
与文档步骤一样















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









