






两者大概的区别:
dfs是可一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯)。
bfs是先把本节点所连接的所有节点遍历一遍,走到下一个节点的时候,再把连接节点的所有节点遍历一遍,搜索方向更像是广度,四面八方的搜索过程。
就地递归函数的下面,例如如下代码:
回溯算法,其实就是dfs的过程,这里给出dfs的代码框架:

797.所有可能的路径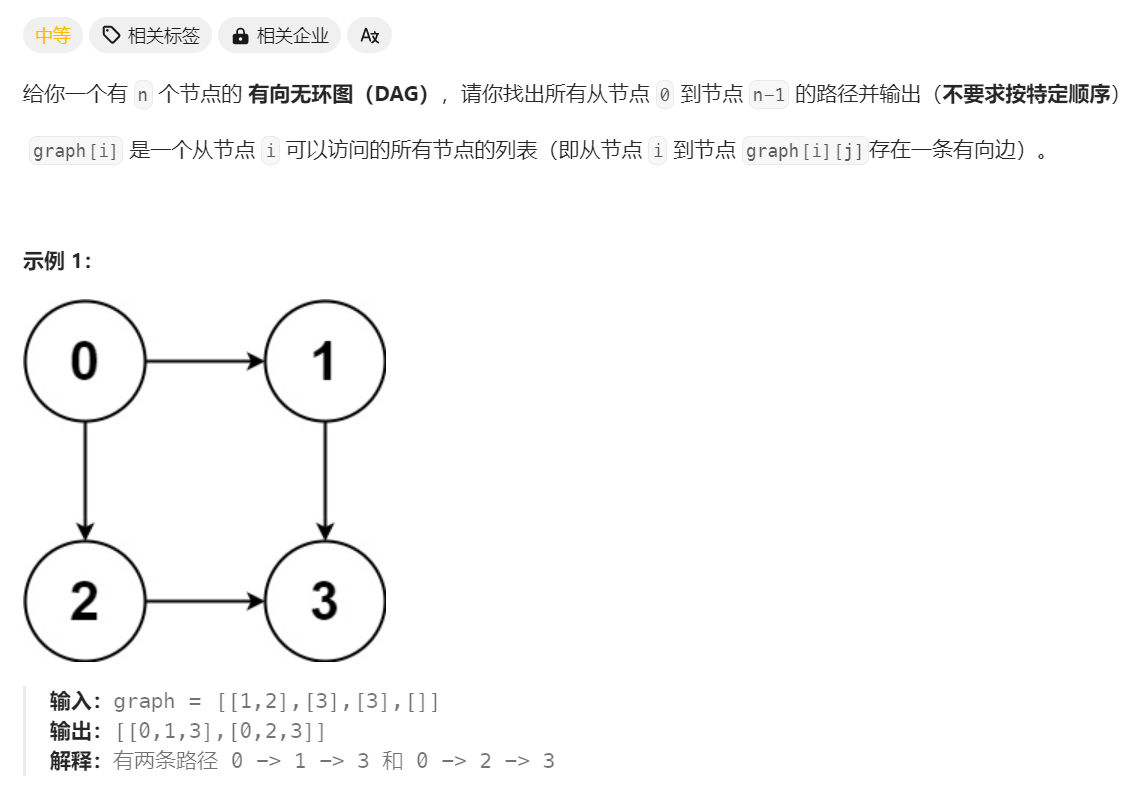
深搜三部曲来分析题目:
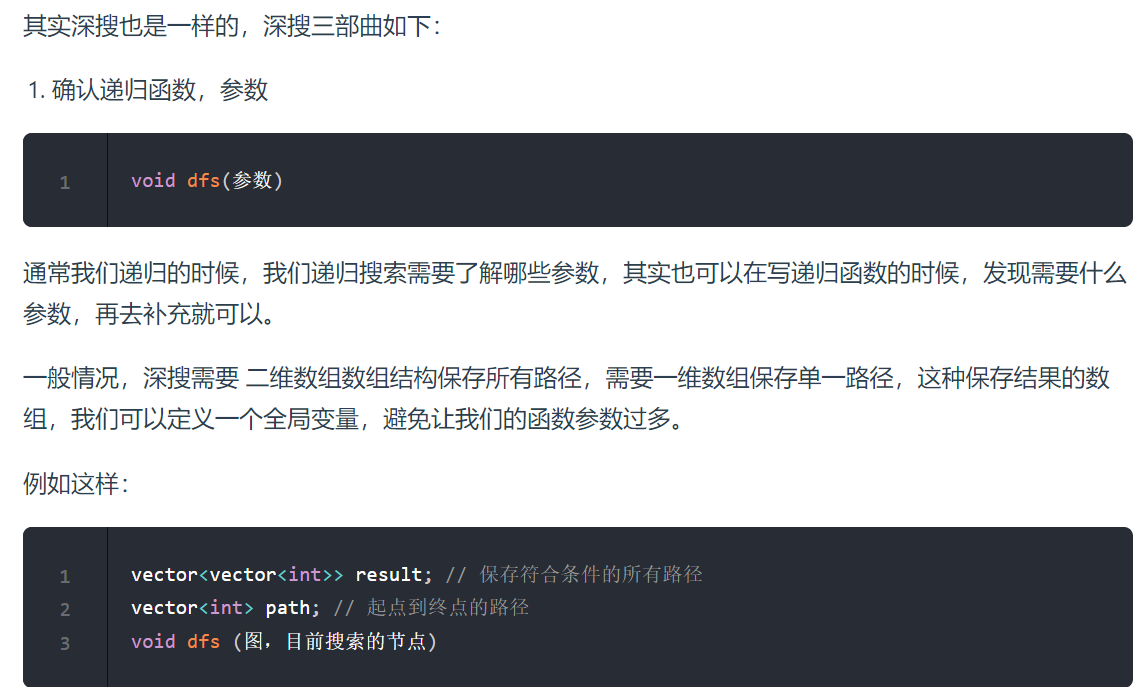
1;确认递归函数,参数
首先我们dfs函数一定要存一个图,用来遍历的,还要存一个目前我们遍历的节点,定义为x
至于 单一路径,和路径集合可以放在全局变量,那么代码是这样的:
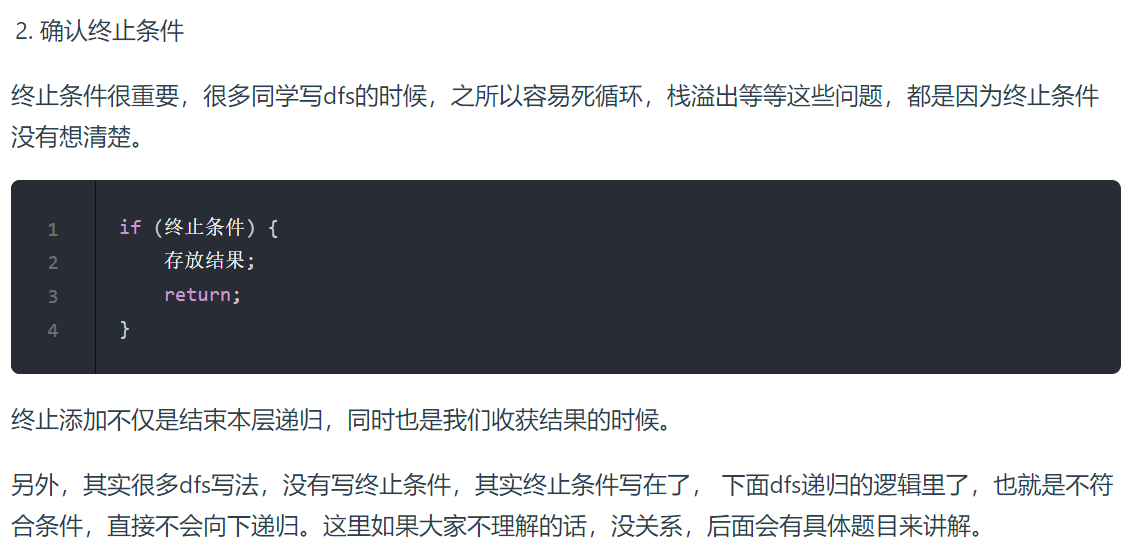
2;确认终止条件
什么时候我们就找到一条路径了?
当目前遍历的节点 为 最后一个节点的时候,就找到了一条,从 出发点到终止点的路径。
当前遍历的节点,我们定义为x,最后一点节点,就是 graph.size() - 1(因为题目描述是找出所有从节点 0 到节点 n-1 的路径并输出)。
所以 但 x 等于 graph.size() - 1 的时候就找到一条有效路径。 代码如下:
3;处理目前搜索节点出发的路径
接下来是走 当前遍历节点x的下一个节点。
首先是要找到 x节点链接了哪些节点呢? 遍历方式是这样的:
接下来就是将 选中的x所连接的节点,加入到 单一路径来。
二维数组中,graph[x][i] 都是x链接的节点,当前遍历的节点就是 graph[x][i] 。
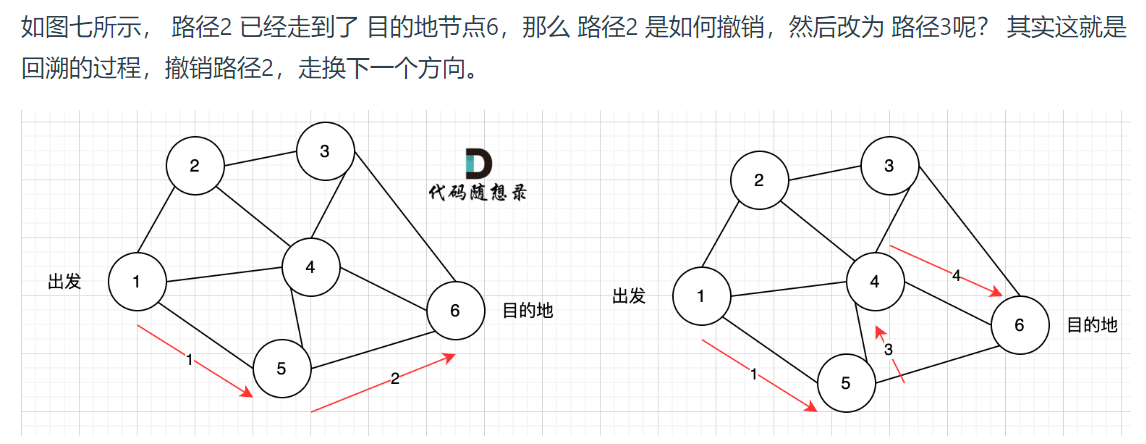
进入下一层递归
回溯算法,其实就是dfs的过程,这里给出dfs的代码框架:















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









