






“又西三百五十里曰天山,多金玉,有青雄黄,英水出焉,而西南流注于汤谷。有神鸟,其状如黄囊,赤如丹火,六足四翼,浑敦无面目,是识歌舞,实惟帝江也。”——《山海经》,华为诺亚频域LLM「帝江」:仅需1/50训练成本,7B模型媲美LLaMA,推理加速5倍
基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
此前,研究者们提出了线性 Transformer、Mamba、RetNet 等。这些方案可以大幅降低 Transformer 计算成本,并且取得媲美原有模型的精度,但是由于架构更换,模型重训练带来的巨大成本令人望而却步。
本文着眼于大语言模型的训练和使用代价,提出一种从频域角度降低 LLM 的成本的 [帝江] 大语言模型。减少 Transformer 架构使用成本的一种常见方法是基于线性注意力机制 (Linear Attention),但是构建带有线性注意力机制的 Transformer 就需要重新训练整个模型,花费的计算代价太高了,对于巨量参数的 LLM 显然不切实际。
因此,本文提出频域核化 (Frequency Domain Kernelization) 方法:使用离散余弦变换 (DCT) 有效且精准地将 Transformer 的 Query 和 Key 映射到频域。这种映射能够有效地消除 Self-Attention 机制中的 Softmax 操作,使注意力计算复杂度转化为线性。而且,作者从理论上证明,这种频域映射是与原始注意力机制等效近似,允许预训练的原始 Transformer 模型在训练成本很小的情况下,转换为线性复杂度模型。
本文提出的加权准蒙特卡罗方法提供了优越的逼近效率。为了进一步降低计算复杂度,核化方法基于离散余弦变换 (Discrete Cosine Transform, DCT) 操作。本文所提出的方法实现了与原始 Transformer 相当的性能,但大大降低了训练成本 (约 1/10) 和更快的推理速度 (最快约 10 倍) 。
为了解决这一问题,最近的一篇论文提出了一种基于频域的大语言模型架构 — 帝江(源于山海经的一种神话生物,以跑得快而闻名),同时解决了现有大模型的两大痛点:推理成本和训练成本。
- 论文地址:https://arxiv.org/abs/2403.19928
- 开源链接:https://github.com/YuchuanTian/DiJiang
该论文基于频域自注意力变换核,寻找到一种原始自注意力的线性逼近,使得原有的 Transformer 模型可以经过少量数据(1/10-1/50)的微调,可以近乎无损地变形为论文提出的帝江模型。具体来说,在 LLaMA2-7B 上仅仅需要使用 40B 左右的训练数据,就可以取得最多 5 倍的推理加速,且在各个评测集上取得相当的精度。

DiJIang-7B 模型和 LLaMA-7B 的精度对比
DiJIang-7B 模型和 LLaMA-7B 的速度对比
研究背景
Transformer 架构自从推出以来,彻底革新了自然语言处理(NLP)领域,并在多种任务中取得了杰出成果。这一成功导致了大型语言模型(LLMs)主导的时代的到来,在这个时代中,Transformer 结构被放大以处理越来越复杂的任务。然而,这种规模的扩大也带来了巨大的计算需求,特别是由于需要每个 token 之间的计算的自注意力机制。
面对更高效 Transformer 模型的迫切需求,研究者们提出了线性 Transformer、Mamba、RetNet 等方案,虽然这些方案可以大幅降低 Transformer 计算成本,并且取得媲美原有模型的精度,但是由于架构更换,模型重训练带来的巨大成本令人望而却步。
然而,大多数现有的优化 Transformers 方法,特别是与优化注意力机制有关的,需要对模型从头重新训练。这一重新训练过程是一个巨大的挑战,特别是对于参数庞大的模型,需要大量的计算资源和时间投入。例如,像 LLaMA-7B 这样的大型模型的训练需要大约 8 万多 GPU hours。尽管有部分研究如 Performer 努力寻找注意力机制的快速近似方法,但这些方法在大型语言模型中还没有得到彻底的验证。
为了解决大型语言模型中快速注意力近似的问题,论文对现有的线性注意力方案和自注意力近似方案进行了彻底的分析。论文发现,这些方法中近似误差的主要来源是基于蒙特卡洛方法的采样。因此,论文提出采用加权拟蒙特卡洛采样来代替蒙特卡洛采样进行映射,论文进一步引入频域离散余弦变换(DCT)来作为拟蒙特卡洛采样的值,从而高效且准确地将 Transformer 的 query 和 key 映射到频域。使得注意力机制中的 softmax 操作可以被去除,达到线性的计算复杂度。论文还从理论上证明了,这种频域映射是与原始注意力机制的一个近似等效,从而使得帝江模型可以不需要从头开始训练,只需要少量数据就可以从 Transformer 的参数中进行微调继承。论文的实验表明,论文的方法达到了与原始 Transformer 相当的性能,但训练成本大大减少(<1/10),同时也受益于更快的推理速度(在不同模型上最高约 10 倍)。
方法介绍
论文首先回顾了 Attention 的计算方式:

论文提供了理论证明,来表明提出的 WPFF 映射核是一种更优的映射方式,具体的证明内容详见论文附录:

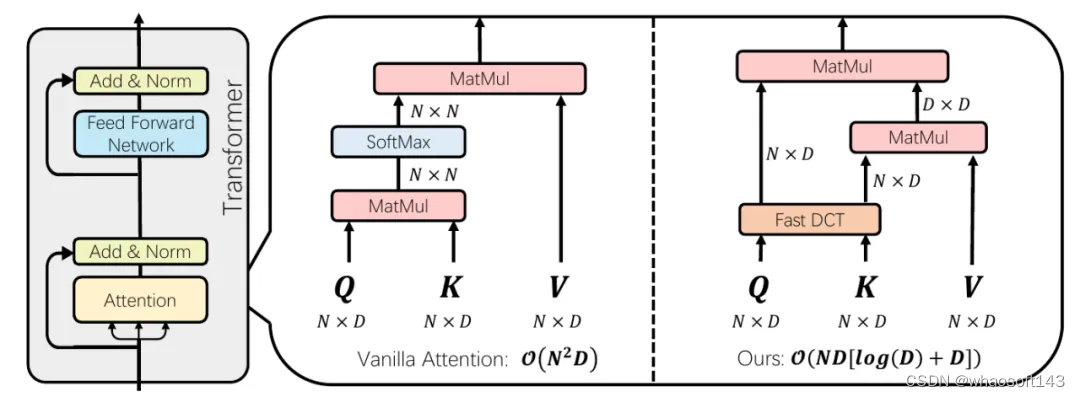
帝江模型和传统自注意力计算的区别
上图展示了帝江模型和传统自注意力计算的区别,在 Transformer 的注意力机制中,key 和 value 的计算通过快速离散余弦变换(DCT)高效地映射到频域。这种映射有效地消除了 softmax 操作,从而显著降低了 Transformer 的计算复杂度。
实验结果
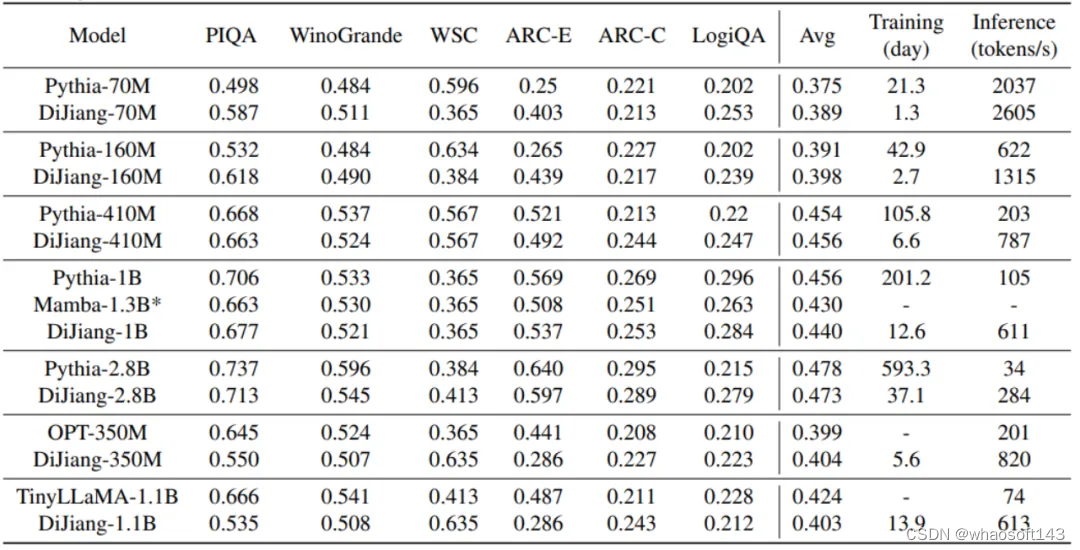
不同模型大小的对比
上表展示了提出的帝江模型在不同大小的 scale 上的结果,可以看到,提出的帝江模型可以取得和原始模型基本相同的精度,并且拥有更快的推理速度和更低的训练成本,显著解决了现有 LLM 遇到的训推成本过大的问题。此外,模型在 1B 的模型量级上超越了 1.3B 大小的 Mamba 模型。需要注意的是,尽管传统 Transformer 可以通过 Flash Attention 的方式进行进一步加速,但由于针对帝江模型的加速框架尚未开发,为了公平对比模型本身的速度,推理速度的测试都是在模型都不使用加速框架的前提下进行的。
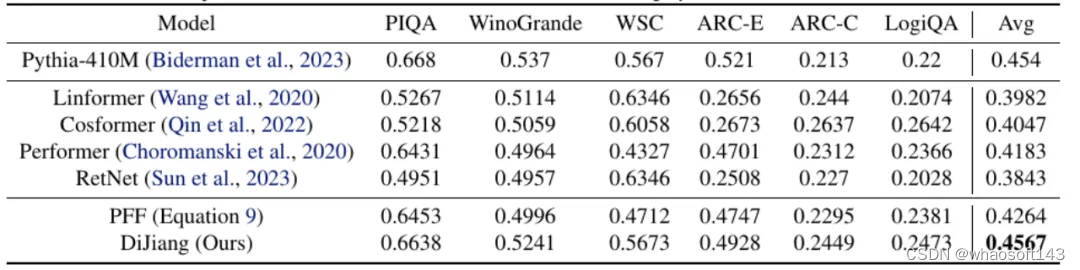
与不同 Transformer 改进方案精度对比
论文还展示了帝江和其他 Transformer 模型的改进方案进行了进一步的对比,可以发现,帝江模型具有比其他模型更好的效果,这得益于其通过更好的核映射近似了原始的 Transformer 模型计
论文还同时提供了帝江 - 7B 模型的续写样例展示,可以看到,帝江 - 7B 的续写结果,和 LLaMA2-7B 相比毫不逊色,甚至条理性上要略胜一筹。
总结
论文提出了一种新的 LLM 架构:帝江,在 7B 以下的模型量级,所提出的模型可以大幅降低 LLM 所需的训练和计算成本,为未来 LLM 的高效部署提出了一种新的思路。帝江架构是否会在更大的模型与多模态 VLM 等其他 Transformer 的应用领域中大放光彩,让我们拭目以待。
大语言模型需要极简注意力机制
Transformer 彻底改变了自然语言处理的领域,也带来了大语言模型 (LLM) 所主导的时代。LLM 可以处理很复杂的任务,但同时也带来了大量的计算需求:显著的推理成本和能耗,使得在手机和机器人这类端侧设备的部署显著受阻。
在大量的模型压缩策略中,简化注意力机制 (simplifying the attention mechanism) 是一种极具前景的方法。比如 Linear Transformer[1],Performer[2]。还有很多经典的改进注意力机制复杂度的技术路线,比如:
- RWKV:RWKV: Reinventing RNNs for the Transformer Era
- RetNet:Retentive Network: A Successor to Transformer for Large Language Models
- Mamba:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
但是,大多数现有的优化 Transformer 的方法,通常需要对模型架构进行重大修改,且通常需要从头训练整个的模型以实现最佳性能。这样的重新训练过程对于 LLM 这种参数量巨大的模型而言,的确是个不小的挑战。比如,训练一个 LLaMA-7B[3] 量级的模型需要 82,432 GPU-hours,总功耗约为 36 MWh。对于这种量级的模型,再训练不仅会带来比较可观的经济问题,还会引发不小的环境问题。那么就需要更有效的方法来适应和优化这些大模型。简化的注意力机制建模方法在大语言模型上面还没有得到很完善的验证。
频域的核化注意力机制
这种频域中的核注意力机制不仅提高了 Transformer 的可扩展性,使其能够轻松处理更大的数据集和序列,而且还显着加快了训练和推理阶段。
1.3 不同尺寸的结果测评
作者使用 Pythia[6]来验证本文方法,这是一个具有完全公共数据集和训练过程的模型,从而可以实现公平比较。作者遵循 Pythia 使用的训练策略,包括学习率、优化器和其他超参数,并使用 Pile 数据集。Pile[7]数据集是一个 825 GiB 大小的英文文本语料库,专为训练大语言模型而设计。它由 22 个不同的高质量子集组成,其中许多来自于学术或者专业资源。这个全面多样的数据集是开发和微调大模型的基础。本文的 DiJiang 模型是从预训练的 Pythia 模型微调得到的。
作者在 Pythia 使用的6个公共数据集上评估了本文方法:
- PIQA[8]
- WinoGrande
- WSC[9]
- ARC-E
- ARC-C[10]
- LogiQA[11]
Pythia 的模型来自 HuggingFace[12]。实验结果如下图3所示。本文方法在从 70M 到 2.8B 参数的不同大小的模型中都取得了不错的结果。6个数据集上的平均性能与原始 Pythia 的性能几乎相同,但训练成本只有其约 1/16。而且,DiJiang 模型的推理速度明显快于原始的 Pythia。这些结果证实了本文方法可以在不影响性能的情况下提高大型语言模型的效率。
图3:不同尺寸模型的实验结果。训练时长在 A800 上测得,推理时使用 2048 的 token 长度
1.4 不同模型的结果测评
为了评估在不同模型的有效性,作者进一步将本文方法应用于 OPT-350M[13][14]和 TinyLLaMA-1.1B[15]模型。需要注意的是,由于它们的训练数据不能完全访问,因此作者继续使用 Pile 数据集来做微调。
最后,作者对著名的大语言模型 LLAMA2-7B 进行了实验,并将其微调到 DiJiang-7B 模型。图4为实验结果,可以看到 DiJiang-7B 模型在各种基准测试中实现了与原始 LLAMA2-7B 几乎相同的结果。值得注意的是,DiJiang 模型只需要 40B tokens 的训练数据,远远小于 LLAMA2-7B 的 2T tokens。这也证明了本文的方法可以扩展到 7B 参数量级别的模型中。
有趣的是,尽管使用的数据集十分有限,但本文方法的结果与原始模型相似,而且训练成本显著降低,速度也更快。这一结果进一步证明了本文方法的泛化性和灵活性。而且,在有些原始训练数据集不可用的情况下,也有一定潜在适用性。
图4:不同 Benchmark 上与 LLaMA2-7B 的对比
1.5 与线性 Transformer 的对比
为了比较本文方法与其他线性复杂度自注意力 Transformer 模型,作者验证了 Pythia-400M 在不同模型 (包括 Linformer、Performer、RetNet 和 Cosformer) 上的微调结果。
图5:与线性 Transformer 微调 Pythoia-410M 的结果对比
为了公平比较,作者采用了相同的训练设置和数据。如图5所示为比较结果。虽然现有的方法可以通过重新训练获得良好的结果,但在不重新训练,仅仅微调的情况下,大多数会遭受显著的精度损失。这主要是因为这些方法难以准确地逼近原始注意力机制,导致无法以最小的训练代价恢复原始模型的精度。
作者还可视化了不同方法的训练曲线,如图6所示。本文方法展示出最快的下降率,最终也实现了最低的损失值。这种快速收敛性也说明了本文可以快速达到与原始 Transformer 相似的性能水平,验证了本文方法在逼近注意力机制方面的有效性。这个结果进一步巩固了本文的结论,即本文方案作为 Transformer 线性替代方案的可行性。
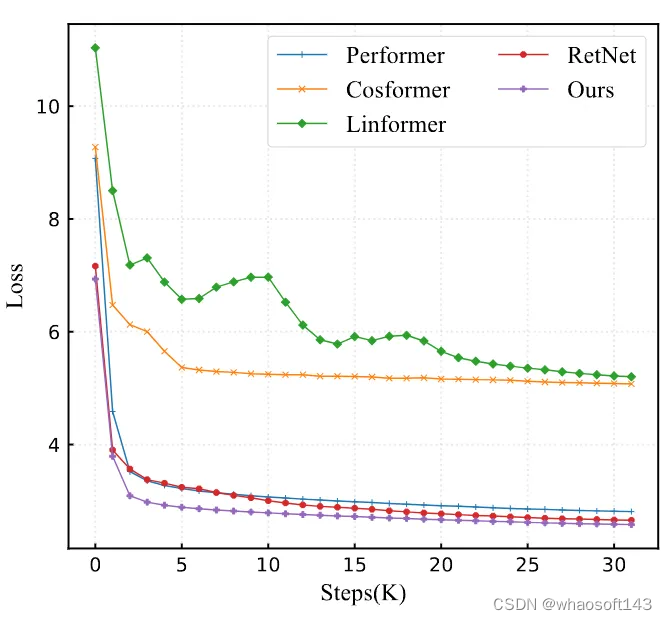
图6:不同方法的训练曲线对比
1.6 推理时间对比
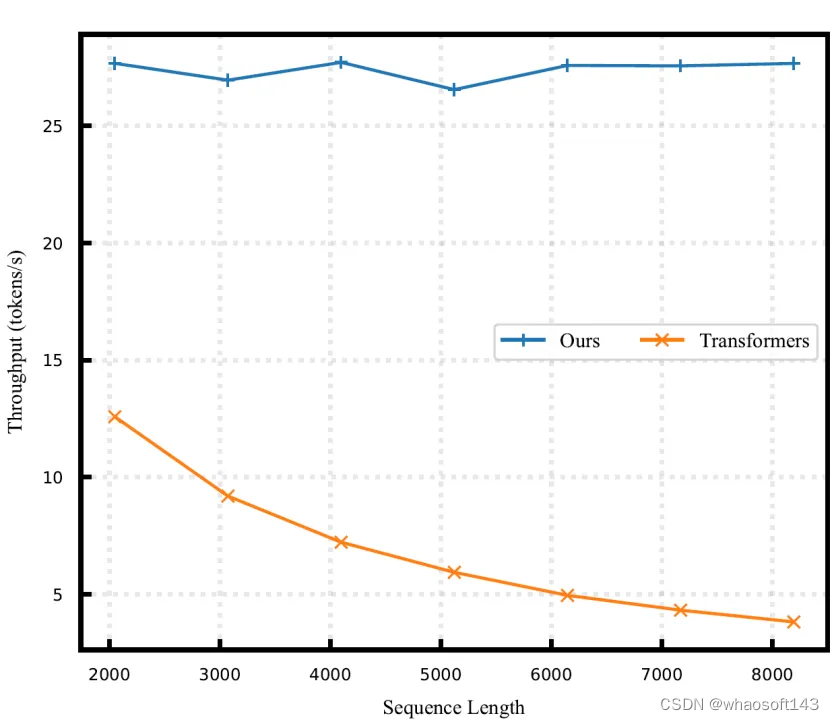
作者还评估了本文方法与 Transformer 模型相比的内存使用量和吞吐量。作者选择 Pythia-410M 模型分析。结果如图7所示。随着 tokens 长度的增加,本文模型的内存占用和推理速度不会变化。这一结果可以归结为本文方法的线性复杂度的注意力机制,表明其更有利于长序列的推理。
由于注意力机制呈二次方的计算复杂度,随 tokens 长度的增加,原始 Transformer 模型在推理时间和所需内存方面都持续增加。这个比较结果突出了本文方案的效率和实用性,尤其是当计算资源是瓶颈问题的长序列推理的情况下。
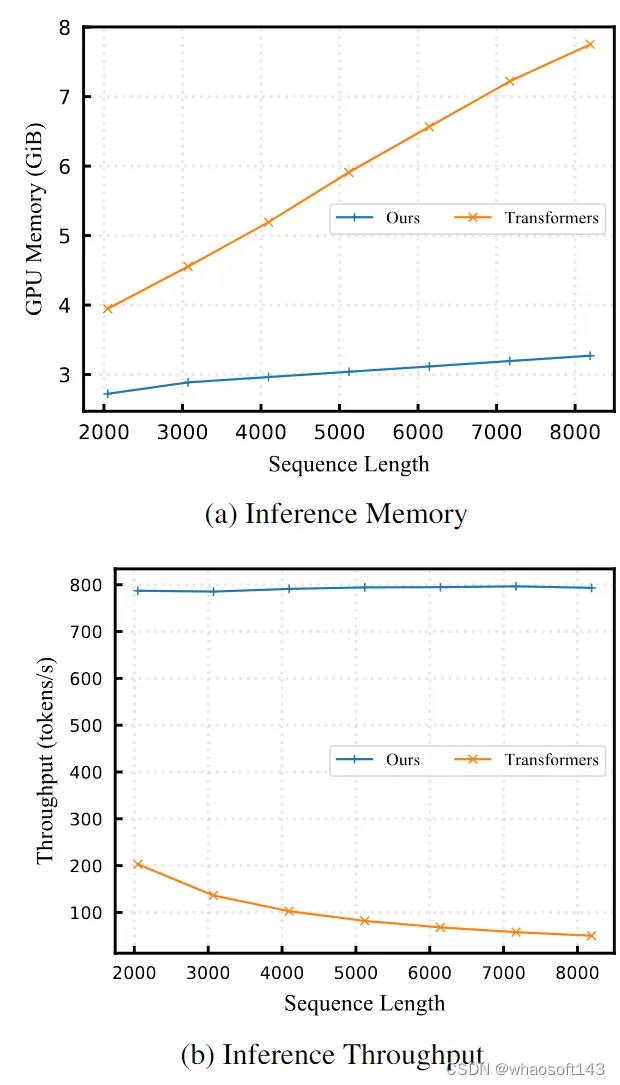
图7:DiJiang 和原始 Transformer 模型的内存使用量和吞吐量对比
1.7 可视化
为了进一步证明本文提出的模型和近似方案对注意力机制近似的有效性,作者绘制了不同方法得到的注意力图的可视化结果,如下图8所示。原始 Transformer 模型的注意力图 (图8(a)) 有丰富的信息,这为其鲁棒能力奠定了基础。相比之下,线性注意力机制 (例如 Performer (图8(b))) 产生的注意力图很难捕捉到 token 之间的关系,导致其映射与原始 Transformer 不同,最终导致模型精度下降。
本文方法 (图8(c)) 通过使用加权准蒙特卡罗方案,非常接近原始注意力机制。这就允许它有效地建模不同 token 之间的关系,实现与原始 Transformer 模型的结果几乎相同。这个比较结果突出了其他线性注意力方法在捕获 token 相互依赖性方面的不足,也展示了本文方法在准确逼近注意力机制的同时提高了计算效率。
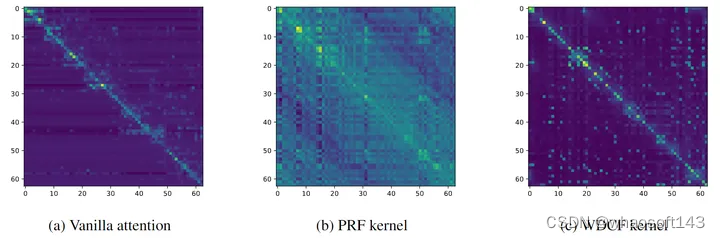
图8:不同架构的注意力图可视化结果

















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









