







Registration:
注册是为脸的所有点建立对应关系的过程。
采用改进的最优阶梯非刚性ICP算法,将其应用于三角网格的三维域。
https://github.com/charlienash/nricp
计算机视觉【1】非刚性ICP配准(Non-rigid ICP)算法分析_船头尺的博客-CSDN博客_非刚性配准
模板S=(V,E),V是顶点,有n个;E是边。
每个顶点的变换矩阵Xi大小是3∗4,所有顶点的变换矩为X=[X1,...,Xn]T,大小为3*4n。
Data loss:从3d face(T)中找到与模板顶点i最近的点,然后计算距离。
Smoothness loss:使变换后的模板尽量平滑。
Landmarks loss: 关键点一一对应。![]()
一、UV position map
GitHub - YadiraF/PRNet: Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network (ECCV 2018)Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network
设计UV位置映射图,用2D图像记录所有面部点云3D坐标,在每个UV多边形中保留语义信息;
设计位置映射回归网络(PRN)(编码-解码),从单张2D人脸图像中回到UV位置映射。
为了保持点的语义,基于3DMM(BFM)创建了UV坐标。使用参数化的UV坐标,将网格边界映射为正方形。由于BFM中的角点超过50K,因此使用256作为位置映射的大小,能够得到比较高的精度。
从 3d obj 到 2d 图像的rendering mesh:使用光栅渲染(rasterization render )
1\一般,render func包括camera、light、raterize。这里只考虑raterize;
2\一般,输入顶点被归一化为 [-1,1] 并以 [0, 0] 为中心。(在世界空间中)
这里顶点使用图像坐标,它以 [w/2, h/2] 为中心,进行插值
- 根据实现的技术不同,渲染主要分为
- 光栅化( rasterization):将矢量顶点组成的图形进行像素化的过程
- 光线投射(ray casting):正向投射。从图像的每一个像素,沿视线方向发射光线,光线穿越整个图像序列,并在这个过程中,对图像序列进行采样获取颜色信息,同时依据光线吸收模型将颜色值进行累加,直至光线穿越整个图像序列,最后得到的颜色值就是渲染图像的颜色。
- 光线跟踪(Ray tracing):逆向跟踪。沿着到达视点的光线的反方向跟踪,经过屏幕上每一个象素,找出与视线相交的物体表面点,并继续跟踪,找出影响点光强的所有光源,从而算出点上精确的光线强度。
3D人脸重建——PRNet网络输出的理解_风翼冰舟的博客-CSDN博客_prnet
二、VRN
https://github.com/AaronJackson/vrn
https://github.com/amadeuzou/vrn-pytorch
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric Regression
将mesh转成voxel(binvox工具),变成一个192*192*200的矩阵,进行训练
voxel转mesh: demo.py
渲染voxel:
vrn/rendervol.m at master · AaronJackson/vrn · GitHub
三、Weakly-Supervised 3D Face Reconstruction base 3DMM
https://github.com/microsoft/Deep3DFaceReconstruction
Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set
CVPR 2019 | 基于弱监督学习的精确3D人脸重建 - 知乎
网络输出239个系数:
80个id系数,64个表情系数,80个纹理系数:

9个光照系数:

6个旋转平移系数
损失函数:
人脸区域皮肤颜色的损失:(皮肤置信度加权的像素颜色l2损失)

关键点损失:(68像素点坐标l2损失)

感知层损失:(人脸识别网络facenet特征的内积相似度)

模型系数正则化损失:
![]()
颜色连续性的损失:生成图像在r,g,b三个通道的脸颊、鼻子和前额的皮肤区域的方差
![]()
四、SFS:shape from shading
一张灰度图的亮度信息由4个因素决定:
1、相机:内部参数和外部参数
2、光照:方向,位置和光的能量分布
3、物体的表面反射率:albedo,由物体表面的材质决定。
4、物体表面的几何性状:
在给定一个3D模型、光照以及物体的反射率,可以模拟相机渲染出一张2D图片。sfs是这个过程的逆向:给定一张图片,光照以及模型的表面反射率,求出物体的3D结构(法向量、深度)。
法向量与光照共同决定了图片亮度的生成,
曲面上的某一点(x,y,z)的单位法向量n使用曲面Z=Z(x,y)上点(x,y,Z(x,y))的梯度(p,q)T表示:
,其中p,q分别是x,y对Z的偏导,
![]() ,
,![]()
假设曲面是Lambertian曲面,且所有点的的反射率都为ρ,那么曲面上某一点的反射函数为:
![]()
假设相机为正交投影,3D点(X,Y,X)投影后的2D点为(x,y)=(mX, mY)
(假设相机为透视投影,3D点(X,Y,X)投影后的2D点为(x,y)= (X/Z , Y/Z ))
2D图像的亮度直接等于曲面反射函数:
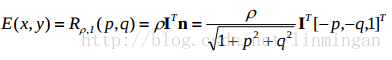
如果知道了2D图片、光照方向和曲面反射率,那么物体曲面重构的就是要,求物体的Z=Z(x,y)。先求曲面顶点的法向量,再求曲面梯度p\q
3D【7】人脸重建:Hands on Shape from Shading阅读笔记_DCD_LIN的博客-CSDN博客
人脸识别 光照预处理_Cecilia_He-CSDN博客_人脸识别光线















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









