






分布式消息队列--kafka工作原理
Topic&Partition
broken
kafka集群中的每一个节点称之为一个broken
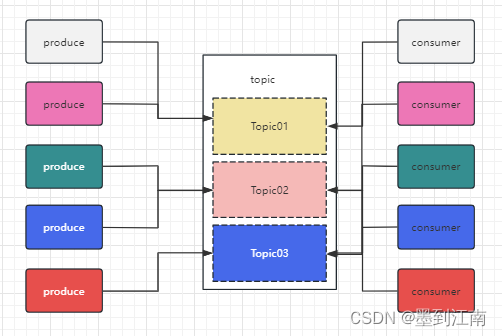
Topic
kafka中topic是一个储存消息的逻辑概念,可以理解成一类消息的集合,每条发送到kafka的消息都有一个类别,即一个Topic。物理上Topic以partition的形式分布在每一个broken。每个topic可以多个生产者向它提供消息,也可以多个消费者对它进行消息消费
partition
kafka中partition是一个存储的物理概念,每一个broken包含一个或多个partition,而在逻辑上,每一个partition又属于某一个Topic,每一条消息具体存储在某一个broken的某一个partition上,每一条消息被添加到分区时都会分配一个唯一的offset(偏移量)指定每一条消息在partition中的位置,kafka通过offset保证消息在分区里的有序性,offset是不跨partition的,即kafka只能保证同partition内的消息之间的有序性,不同partition之间的消息的顺序性无法保证。
Partition是以文件的形式存储在文件系统中,比如在一个单机的kafka上创建一个名为firstTopic的topic,其中有3个partition
./kafka-topics.sh --create --replication-factor 1--partitions 3 --topic firstTopic --bootstrap-server192.168.11.156:9092
那么在kafka的数据目录(默认为/tmp/kafka-log,可在配置文件中修改)中就有3个目录,firstTopic-0-3,命名规则是<topic_name>-<partition_id>
消息分发策略
消息是kafka中最基本的数据单元,在kafka中一条消息由key、value两部分组成,再发送一条消息是可以指定消息的key,producer会根据key和partition机制来判断当前这条消息应该发送并存储到哪个partition中。可以根据需要进行扩展producer的partition机制。
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
* 自定义produce的partition机制
*/
public class MyPartition implements Partitioner {
private Random random=new Random();
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获得分区列表
List<PartitionInfo> partitionInfos=cluster.partitionsForTopic(topic);
int partitionNum=0;
if(key==null){
partitionNum=random.nextInt(partitionInfos.size()); //随机分区
}else{
partitionNum=Math.abs((key.hashCode())%partitionInfos.size());
}
System.out.println("key ->"+key+"->value->"+value+"->"+partitionNum);
return partitionNum; //指定发送的分区值
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
消息默认的分发机制
默认情况下,kafka采用的是hash取模的分区算法。如果Key为 null,则会随机分配一个分区。这个随机是在这个参数"metadata.max.age.ms"的时间范围内随机选择一个。对于这个时间段内,如果key为null,则只会发送到唯一的分区。这个值默认情况下是10分钟更新一次。
关于Metadata,简单理解就是Topic/Partition 和 broker 的映射关系,每一个topic的每一个partition,需要知道对应的 broker列表是什么,leader是谁、follower是谁。这些信息都是存储在Metadata这个类里面。
消息消费原理
kafka消息消费原理
在实际生产过程中,每个 topic 都会有多个 partitions,多个 partitions 的好处在于,一方面能够对 broker 上的数据进行分片有效减少了消息的容量从而提升 io性能。另外一方面,为了提高消费端的消费能力,一般会通过多个consumer 去消费同一个 topic,也就是消费端的负载均衡机制,也就是在多个partition以及多个consumer的情况下,消费者是如何消费消息的。kafka存在consumer group的概念,也就是 group.id一样的 consumer,这些consumer 属于一个consumer group,组内的所有消费者协调在一起来消费订阅主题的所有分区。当然每一个分区只能由同一个消费组内的consumer来消费,那么同一个consumer group 里面的 consumer 是怎么去分配该消费哪个分区里的数据的呢?如下图所示,3个分区,3个消费者,那么哪个消费者消分哪个分区?
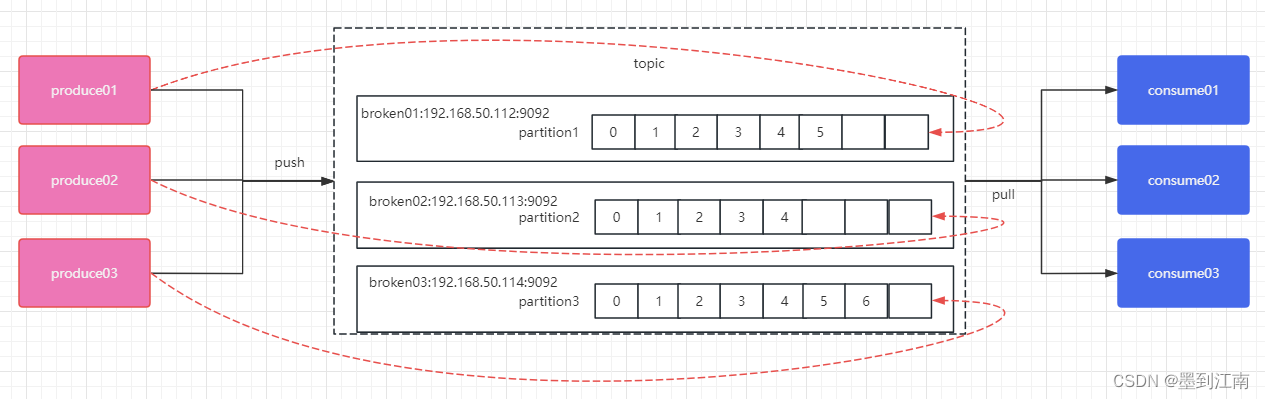
对于上面这个图来说,这3个消费者会分别消费 test 这个topic 的 3 个分区,也就是每个 consumer 消费一个partition。
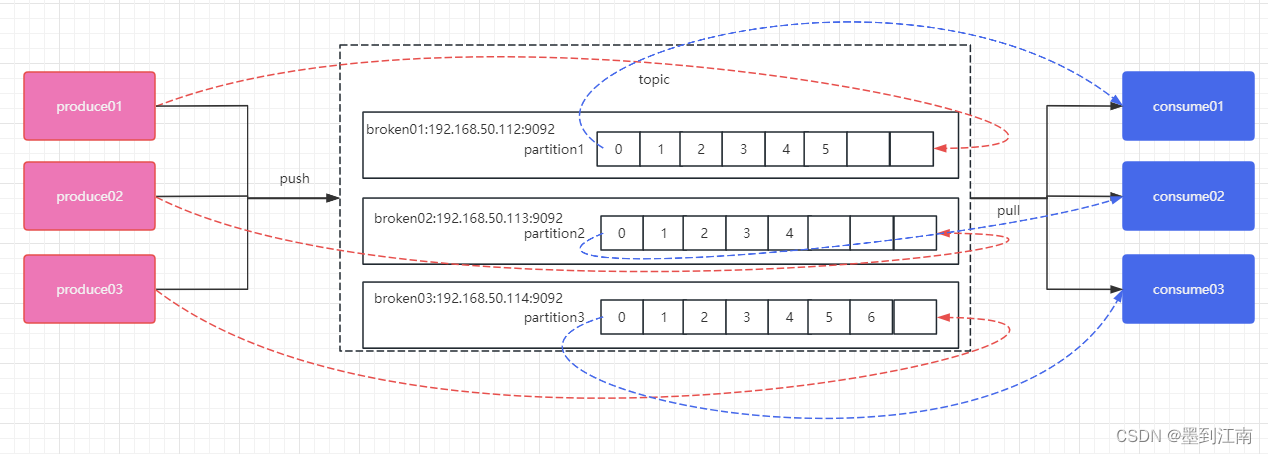
什么是分区策略
在kafka中,存在两种分区分配策略,一种是Range(默认)、另一种另一种还是RoundRobin(轮询)。通过partition.assignment.strategy 这个参数来设置。
Range strategy(范围分区)
Range 策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假设我们有10个分区,3个消费者,排完序的分区将会是 0,1,2,3,4,5,6,7,8,9;消费者线程排完序将会是C1-0,C2-0,C3-0。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有 10个分区,3 个消费者线程,10/3=3,而且除不尽,那么消费者线程C1-0将会多消费一个分区,所以最后分区分配
的结果看起来是这样的:
C1-0 将消费 0,1,2,3 分区
C2-0 将消费 4,5,6 分区
C3-0 将消费 7,8,9 分区
假如我们有 11 个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 0,1,2,3 分区
C2-0 将消费 4,5,6,7 分区
C3-0 将消费 8,9,10 分区
假如我们有2个主题(T1和 T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
C1-0将消费T1主题的0,1,2,3分区以及T2主题的0,1,2,3分区
C2-0将消费T1主题,4,5,6分区以及T2主题的4,5,6分区
C3-0将消费T1主题的7,8,9分区以及T2主题的7,8,9分区
可以看出,C1-0消费者线程比其他消费者线程多消费了2个分区,这就是 Range strategy 的一个很明显的弊端
RoundRobin strategy(轮询分区)
轮询分区策略是把所有 partition 和所有 consumer 线程都列出来,然后按照 hashcode 进行排序。最后通过轮询算法分配 partition 给消费线程。如果所有 consumer 实例的订阅是相同的,那么 partition 会均匀分布。
使用轮询分区策略必须满足两个条件
1.每个主题的消费者实例具有相同数量的流
2.每个消费者订阅的主题必须是相同的
什么时候会触发分区策略
当出现以下几种情况时,kafka会进行一次分区分配操作,也就是 kafka consumer的 rebalance
- 同一个 consumer group 内新增了消费者
- 消费者离开当前所属的consumer group,比如主动停机或者宕机
- topic新增了分区(也就是分区数量发生了变化)
kafka consuemr的rebalance机制规定了一个consumer group下的所有consumer如何达成一致来分配订阅topic的每个分区。而具体如何执行分区策略,就是前面提到过的两种内置的分区策略。而kafka对于分配策略这块,提供了可插拔的实现方式,也就是说,除了这两种之外,还可以创建自己的分配机制。
谁来执行 Rebalance 以及管理 consumer 的 group 呢?
Kafka 提供了一个角色:coordinator 来执行对于 consumer group 的管理,当 consumer group 的第一个 consumer 启动的时候,它会去和 kafka server 确定谁是它们组的 coordinator。之后该 group 内的所有成员都会和该 coordinator 进行协调通信
如何确定 coordinator
consumer group 如何确定自己的 coordinator , 消费者向 kafka 集群中的任意一 个 broker 发送一个 GroupCoordinatorRequest 请求,服务端会返回一个负载最小的 broker 节点的 id , 并将该 broker 设置为 coordinator
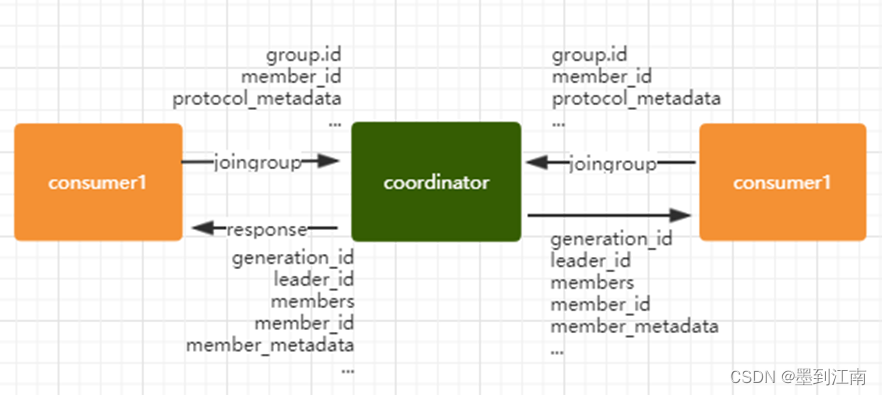
JoinGroup 的过程
在 rebalance 之前,需要保证 coordinator 是已经确定好了,整个 rebalance 的过程分为两个步骤,Join 和 Sync 。
join: 表示加入到 consumer group 中,在这一步中,所有 的成员都会向 coordinator 发送 joinGroup 的请求。一旦所有成员都发送了 joinGroup 请求,那么 coordinator 会选择一个 consumer 担任 leader 角色,并把组成员信息和订阅信息发送消费者
Synchronizing Group State 阶段
完成分区分配之后,就进入了 Synchronizing Group State 阶段 , 主要逻辑是向 GroupCoordinator 发送 SyncGroupRequest 请求,并且处理 SyncGroupResponse 响应,简单来说,就是 leader 将消费者对应的 partition 分配方案同步给 consumer group 中的所有 consumer
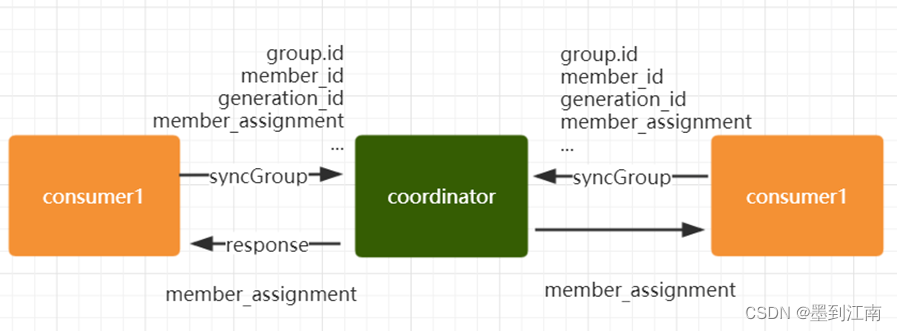
每个消费者都会向 coordinator 发送 syncgroup 请求,不 过只有 leader 节点会发送分配方案,其他消费者只是打打 酱油而已。当 leader 把方案发给 coordinator 以后, coordinator 会把结果设置到 SyncGroupResponse 中。这 样所有成员都知道自己应该消费哪个分区。
消费端如何消费指定的分区
通过下面的代码,就可以消费指定该topic下的0号分区。
其他分区的数据就无法接收
//消费指定分区的时候,不需要再订阅
//kafkaConsumer.subscribe(Collections.singletonList(topic));
//消费指定的分区
TopicPartition topicPartition=new TopicPartition(topic,0);
kafkaConsumer.assign(Arrays.asList(topicPartition));
消息的存储策略
多个分区在集群中的分配
如果对于一个 topic,在集群中创建多个 partition,那么 partition 是如何分布的呢?
1.将所有 N Broker 和待分配的 i 个 Partition 排序
2.将第 i 个 Partition 分配到第(i mod n)个 Broker 上
例如,在kafka集群里创建如下的topic:
| name | partition |
|---|---|
| topic01 | 6 |
| topic02 | 9 |
| topic03 | 6 |
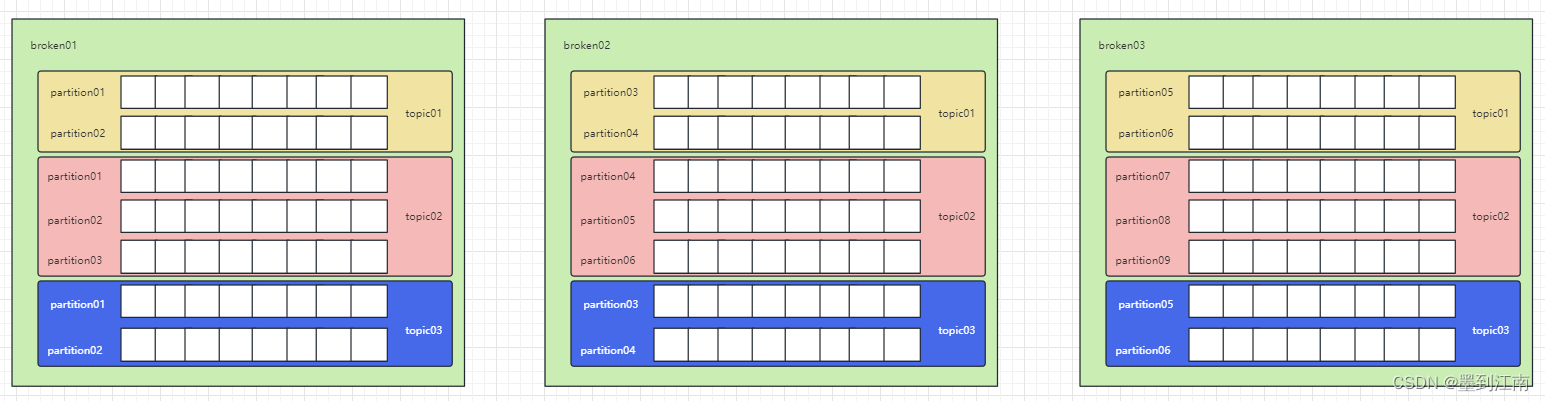
partition会均匀分配到每个broken上:
| broken上的topic | partitionNum |
|---|---|
| topic01 | 2 |
| topic02 | 3 |
| topic03 | 2 |
partition 的高可用副本机制
Kafka的每个topic都可以分为多个Partition, 并且多个 partition 会均匀分布在集群的各个节点下。虽然这种方式能够有效的对数据进行分片,但是对于每个 partition 来说,都是单点的,当其中一个 partition 不可用的时候,那么这部分消息就没办法消费。所以 kafka 为了提高 partition 的可靠性而提供了副本的概念(Replica),通过副本机制来实现冗余备份。每个分区可以有多个副本,并且在副本集合中会存在一个 leader 的副本,所有的读写请求都是由 leader 副本来进行处理。剩余的其他副本都做为 follower 副本,follower 副本会从 leader 副本同步消息日志 。这个有点 类似 zookeeper 中 leader 和 follower 的概念,但是具体的时间 方式还是有比较大的差异。所以我们可以认为,副本集会 存在一主多从的关系。 一般情况下,同一个分区的多个副本会被均匀分配到集群中的不同 broker 上,当 leader 副本所在的 broker 出现故障后,可以重新选举新的 leader 副本继续对外提供服务。 通过这样的副本机制来提高 kafka 集群的可用性。














 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









