







数据库硬件兼容性问题(如新硬盘未被识别)的排查与大数据解决方案
一、问题原因分析
- 硬件兼容性冲突
- 新硬盘与服务器主板、电源或散热系统不兼容,可能导致系统无法识别。需查阅服务器与硬盘的官方兼容性列表,并咨询供应商技术支持 。
- 某些数据库(如分布式事务数据库)对硬件架构(如ARM、x86)有明确兼容性要求,需匹配CPU平台架构 。
2. 驱动与系统问题
- 操作系统缺少新硬盘驱动或驱动版本冲突,需下载安装最新驱动并检查与系统版本的匹配性 。
- 数据库软件(如MySQL、KingbaseES)可能因驱动过旧导致无法识别存储设备,需更新数据库客户端驱动 。
-
物理连接与配置错误
- 硬盘连接线松动、接口类型不匹配(如SATA/NVMe)是常见问题,需检查物理连接状态 。
- BIOS/UEFI设置中未启用新硬盘对应的存储模式(如AHCI/RAID)。
-
大数据集群的特殊场景
- 在分布式数据库(如NebulaGraph、TDSQL)中,新硬盘可能因副本同步机制未触发导致节点无法加入集群,需检查副本自动补齐功能 。
二、大数据驱动的解决思路
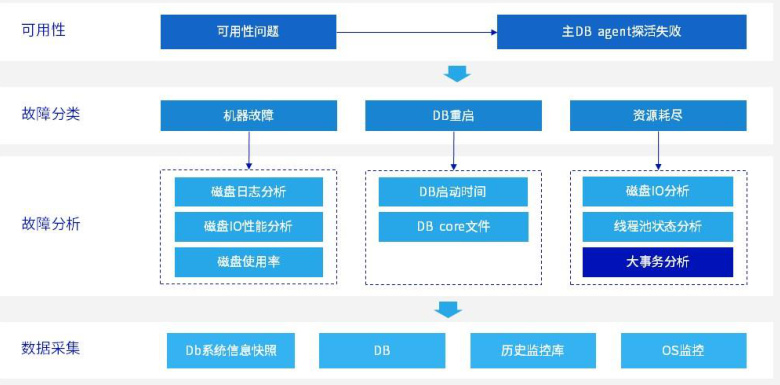
- 自动化硬件监控与预警
- 日志分析:通过ELK(Elasticsearch+Logstash+Kibana)实时采集服务器硬件日志,检测硬盘识别异常事件 。
# 示例:从系统日志中过滤硬盘识别错误
grep -E "disk not detected|IO error" /var/log/syslog
- 监控工具集成:利用Prometheus+Grafana监控硬盘状态指标(如
node_disk_io_now),设置阈值告警 。
- 分布式系统自愈机制
- 在支持高可用的数据库(如虚谷数据库、KingbaseES)中,通过主备切换自动隔离故障节点,并触发副本重新分配 。
- 使用Apache Spark进行集群级硬件健康度分析,预测兼容性问题:
# 示例:分析集群节点硬件兼容性
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("HardwareCompatibility").getOrCreate()
df = spark.read.json("hdfs://cluster/hardware_logs/*.json")
incompatible_disks = df.filter((df.vendor != "ApprovedVendor") | (df.interface_type != "NVMe" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











