







在人工智能领域,大型语言模型(LLMs)的发展日新月异,而YuLan-Mini正是这一领域的最新突破。由中国人民大学高瓴人工智能学院(Gaoling School of Artificial Intelligence, Renmin University of China)的研究团队开发的YuLan-Mini,是一款具有2.42亿参数的轻量级语言模型,它在数学和代码领域表现出色,并且在性能上可与训练数据量更大的行业领先模型相媲美。

核心特性
YuLan-Mini的核心特性体现在以下几个方面:
- 数据高效:尽管YuLan-Mini仅在1.08T个token上进行了预训练,但其性能却达到了与训练数据量更大的模型相当的水平。
- 长上下文能力:YuLan-Mini的上下文长度扩展到了28,672个token,这使得它在处理长文本任务时更加出色,同时在短文本任务中也保持了高准确率。
- 先进的训练技术:通过精心设计的数据管道、系统优化方法和有效的退火方法,YuLan-Mini减少了对大规模数据集的依赖,同时确保了高质量的学习效果,并有效避免了训练过程中的常见问题,如损失激增和梯度爆炸。
性能基准
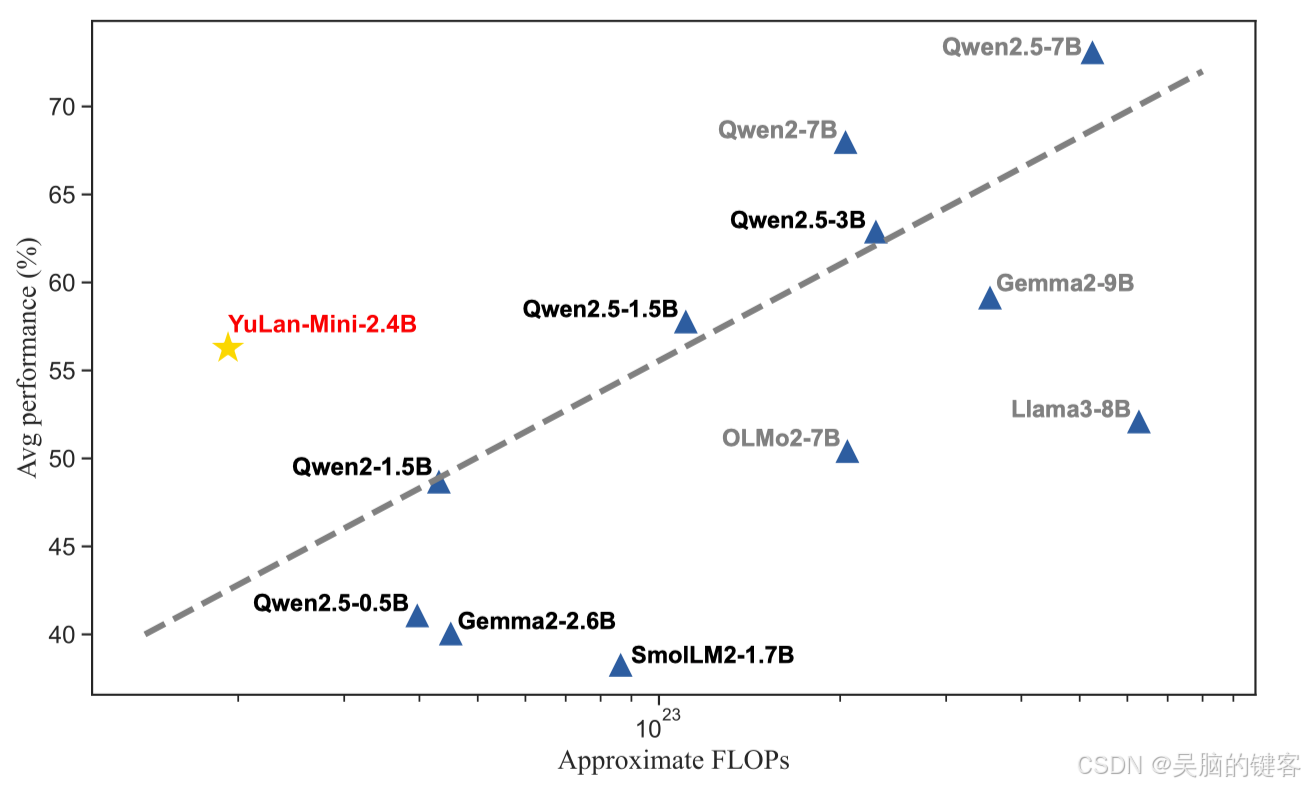
YuLan-Mini在多个基准测试中的表现令人瞩目:
- 在零样本场景下的HumanEval测试中获得了64.00的高分。
- 在四样本设置下的MATH-500测试中获得了37.80的成绩。
- 在五样本任务中的MMLU测试中得分为49.10
| Models | Model Size | # Train Tokens | Context Length | MATH 500 | GSM 8K | Human Eval | MBPP | RACE Middle | RACE High | RULER |
|---|---|---|---|---|---|---|---|---|---|---|
| MiniCPM | 2.6B | 1.06T | 4K | 15.00 | 53.83 | 50.00* | 47.31 | 56.61 | 44.27 | N/A |
| Qwen-2 | 1.5B | 7T | 128K | 22.60 | 46.90* | 34.80* | 46.90* | 55.77 | 43.69 | 60.16 |
| Qwen2.5 | 0.5B | 18T | 128K | 23.60 | 41.60* | 30.50* | 39.30* | 52.36 | 40.31 | 49.23 |
| Qwen2.5 | 1.5B | 18T | 128K | 45.40 | 68.50* | 37.20* | 60.20* | 58.77 | 44.33 | 68.26 |
| Gemma2 | 2.6B | 2T | 8K | 18.30* | 30.30* | 19.50* | 42.10* | - | - | N/A |
| StableLM2 | 1.7B | 2T | 4K | - | 20.62 | 8.50* | 17.50 | 56.33 | 45.06 | N/A |
| SmolLM2 | 1.7B | 11T | 8K | 11.80 | - | 23.35 | 45.00 | 55.77 | 43.06 | N/A |
| Llama3.2 | 3.2B | 9T | 128K | 7.40 | - | 29.30 | 49.70 | 55.29 | 43.34 | 77.06 |
| YuLan-Mini | 2.4B | 1.04T | 4K | 32.60 | 66.65 | 61.60 | 66.70 | 55.71 | 43.58 | N/A |
| YuLan-Mini | 2.4B | 1.08T | 28K | 37.80 | 68.46 | 64.00 | 65.90 | 57.18 | 44.57 | 51.48 |
这些结果强调了YuLan-Mini在资源有限的情况下,仍能提供高性能的能力,这对于AI技术的可访问性至关重要
示例
Huggingface
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("yulan-team/YuLan-Mini")
model = AutoModelForCausalLM.from_pretrained("yulan-team/YuLan-Mini", torch_dtype=torch.bfloat16)
# Input text
input_text = "Renmin University of China is"
inputs = tokenizer(input_text, return_tensors="pt")
# Completion
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
vLLM Serve
vllm serve yulan-team/YuLan-Mini --dtype bfloat16
SGLang Serve
python -m sglang.launch_server --model-path yulan-team/YuLan-Mini --port 30000 --host 0.0.0.0
开源贡献
YuLan-Mini项目的所有数据和代码仅供学术研究使用,并遵循MIT许可。项目详细信息和模型权重可以在GitHub页面上找到
https://github.com/RUC-GSAI/YuLan-Mini
结论
YuLan-Mini以其数据高效和长上下文能力,为大型语言模型的发展树立了新的标杆。它的出现不仅展示了中国人民大学高瓴人工智能学院在AI领域的研究实力,也为全球AI社区提供了一个强大的工具。随着YuLan-Mini的进一步发展和应用,我们期待它在自然语言处理领域带来更多的创新和突破。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









