






kubernetes作为云原生不可或缺的重要组件,在编排调度系统中一统天下,成为事实上的标准,如果kubernetes出现问题,那将是灾难性的。而我们在容器化推进的过程中,就遇到了很多有意思的故障,今天我们就来分析一个“雪崩”的案例。
微信公众号原文: kubernetes "雪崩"了 (qq.com)
问题描述
第一次故障
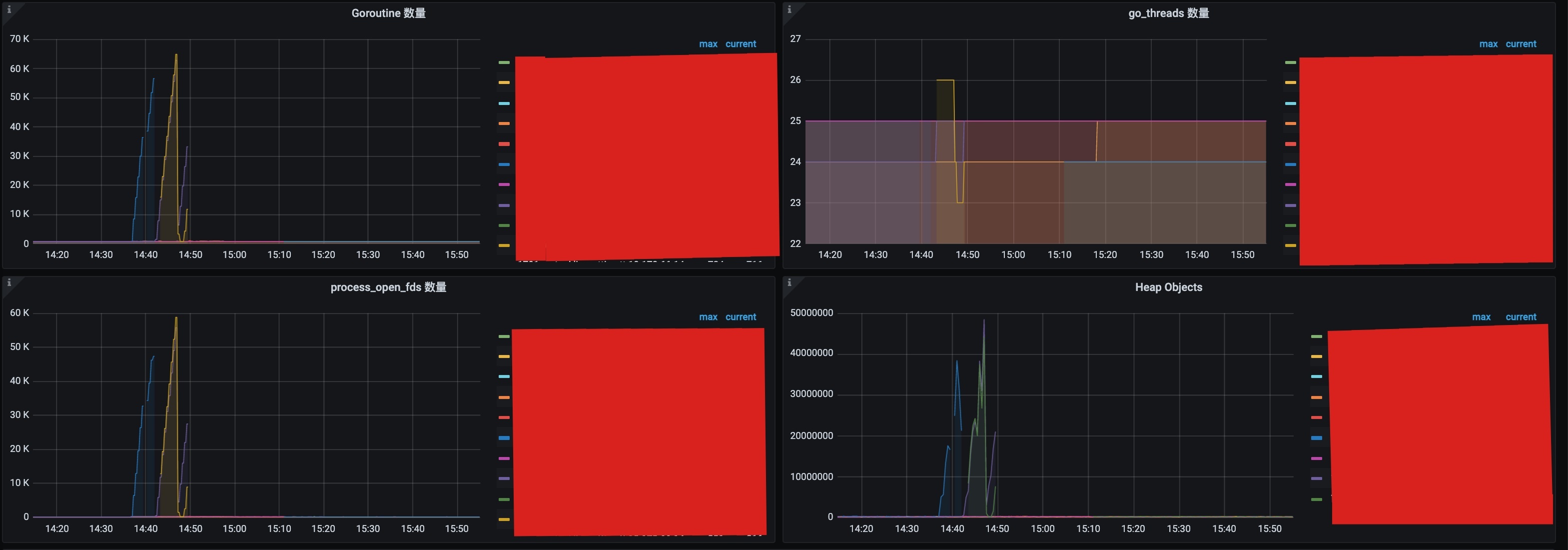
一个黑色星期三,突然收到大量报警:服务大量5xx;某台kubernetes宿主机器CPU飚高到近80%;内存增速过快等等。
赶紧打开监控,发现一些服务的超时请求很多,内存急剧增高,gc变慢,CPU、goroutines暴涨等等。
粗略分析看不出到底哪个是因哪些是果,于是启动应急预案,赶紧将此机器上的POD迁移到其他机器上,迁移后服务运行正常,流量恢复。
初步解决问题,开始详细分析原因,从监控看实在分析不出原因,也没有内核日志,只有故障4分钟后的一条OOM kill的日志,没有什么价值。
但是从监控上看A服务在此机器上的POD问题尤为严重。
由于当时急于恢复流量,没有保留好现场,以为是某个服务出现什么问题导致的(当时还猜测可能linux某部分隔离性没有做好引发的)。
服务故障部分监控
宿主机
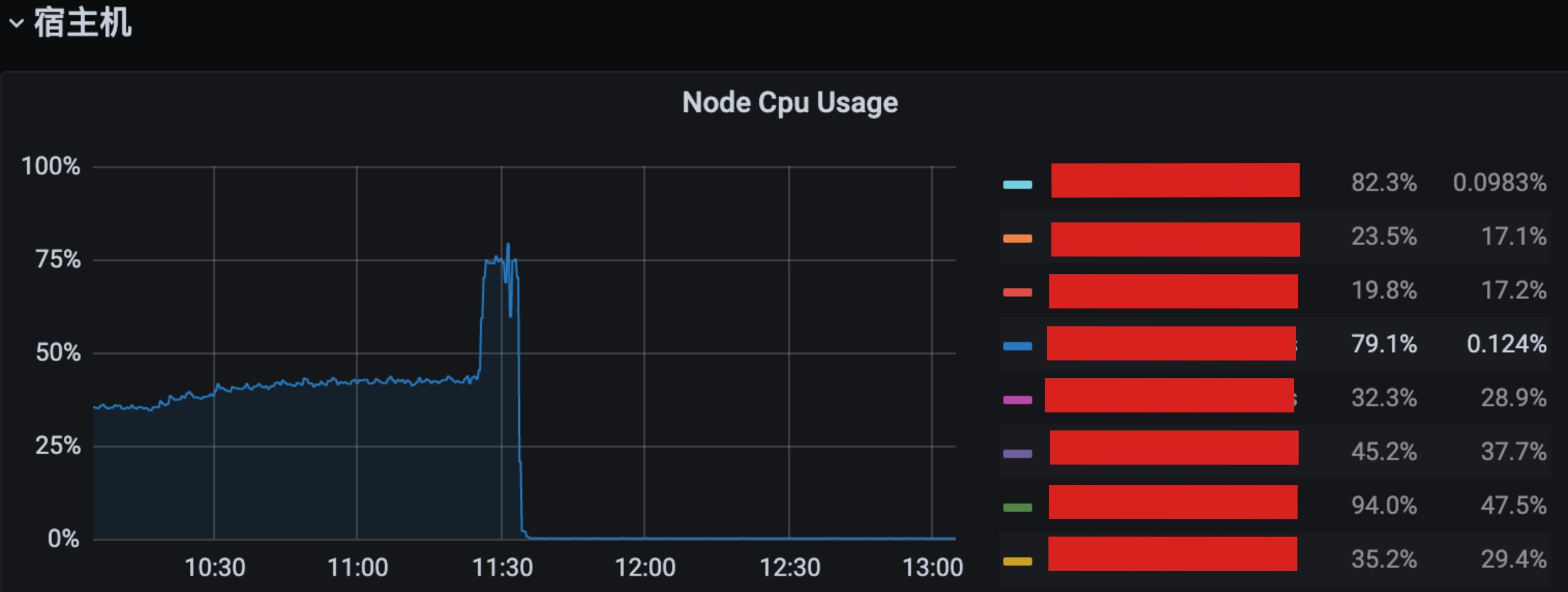
内核OOM日志
第二次故障
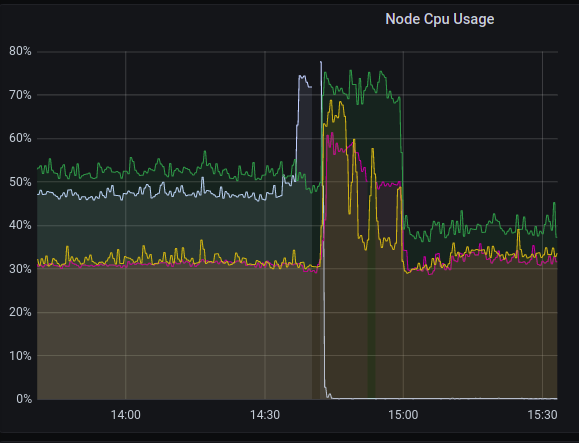
3个小时后,又一台机器发生故障,先恢复故障的同时使用perf捕获了调用栈,然后又继续骚操作将POD迁移走,这一次就导致其他3台宿主机出现问题了,这3台宿主机上的服务以及依赖这些服务的服务也相继出现问题。
这时,才意识到是什么达到了临界,才会导致其他机器相继出现问题。于是赶紧将一些服务转移到物理机部署,宿主机立即恢复正常)。
宿主机CPU利用率
top查看到很多服务的CPU使用率都很高
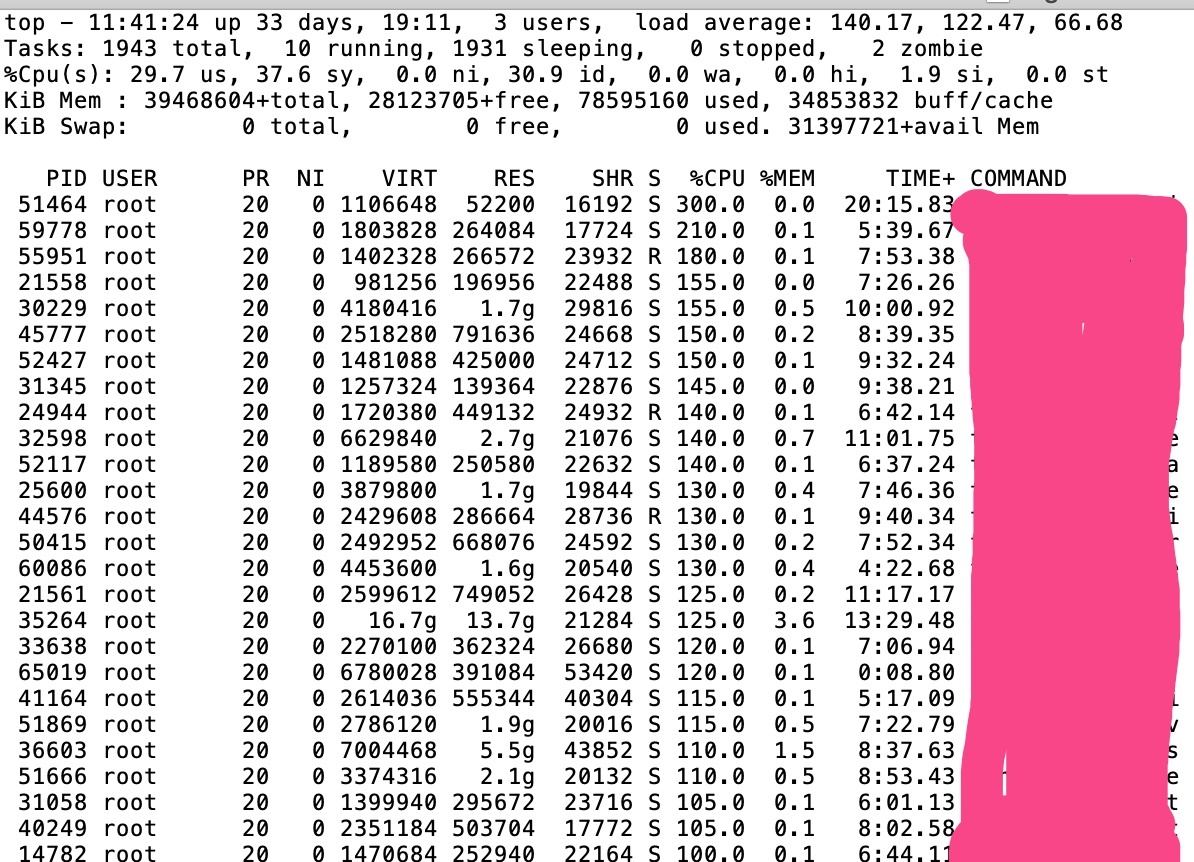
perf record

初步分析
虽然问题初步解决了,但还得继续分析根本原因。
从perf record来看,大多数进程的调用都blocking在__write_lock_failed函数,大部分都是由于__neigh_create调用造成的,于是先google,搜索到相似问题的文章:
但还不能如此草率的下定论,仍然需要进一步分析才能盖棺定论。
内核源码分析
线上机器内核较老,3.10.0-1160.36.2.el7.x86_64版本,由于有tcp流量也有udp流量,所以两种协议都要进行分析。
系统调用
从系统调用send开始分析
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
unsigned int, flags)
{
return sys_sendto(fd, buff, len, flags, NULL, 0);
}
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
unsigned int, flags, struct sockaddr __user *, addr,
int, addr_len)
{
......
// 根据fd找到socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
// 构造msghdr
iov.iov_base = buff;
iov.iov_len = len;
msg.msg_name = NULL;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
// 发送数据
err = sock_sendmsg(sock, &msg, len);
......
}
int sock_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
......
ret = __sock_sendmsg(&iocb, sock, msg, size);
......
}
static inline int __sock_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size)
{
.....
return err ?: __sock_sendmsg_nosec(iocb, sock, msg, size);
}
static inline int __sock_sendmsg_nosec(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size)
{
......
// AF_INET 协议族提供的是inet_sendmsg函数来发送数据
return sock->ops->sendmsg(iocb, sock, msg, size);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
inet_sendmsg会调用不同协议的发送函数,
- udp协议:udp_sendmsg
- tcp协议:tcp_sendmsg
协议层
udp
int udp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t len)
{
......
/* Lockless fast path for the non-corking case. */
if (!corkreq) {
// 构造skb
skb = ip_make_skb(sk, fl4, getfrag, msg->msg_iov, ulen,
sizeof(struct udphdr), &ipc, &rt, msg->msg_flags);
err = PTR_ERR(skb);
if (!IS_ERR_OR_NULL(skb))
err = udp_send_skb(skb, fl4);
goto out;
}
......
return err;
}
EXPORT_SYMBOL(udp_sendmsg);
//
static int udp_send_skb(struct sk_buff *skb, struct flowi4 *fl4)
{
......
// 填充UDP头,checksum
uh = udp_hdr(skb);
uh->source = inet->inet_sport;
uh->dest = fl4->fl4_dport;
uh->len = htons(len);
......
uh->check = csum_tcpudp_magic(fl4->saddr, fl4->daddr, len,
sk->sk_protocol, csum);
......
// 发送
err = ip_send_skb(sock_net(sk), skb);
if (err) {
if (err == -ENOBUFS && !inet->recverr) {
UDP_INC_STATS_USER(sock_net(sk), UDP_MIB_SNDBUFERRORS, is_udplite);
err = 0;
}
} else
......
return err;
}
int ip_send_skb(struct net *net, struct sk_buff *skb)
{
int err;
err = ip_local_out(skb);
if (err) {
if (err > 0)
err = net_xmit_errno(err);
if (err)
IP_INC_STATS(net, IPSTATS_MIB_OUTDISCARDS);
}
return err;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
最终调用到ip_local_out函数
tcp
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size)
{
......
struct tcp_sock *tp = tcp_sk(sk);
lock_sock(sk);
......
/* Ok commence sending. */
// 获取⽤户传递过来的数据和标志
iovlen = msg->msg_iovlen;
iov = msg->msg_iov; // 数据地址
copied = 0;
......
// 遍历用户层的数据块
while (--iovlen >= 0) {
size_t seglen = iov->iov_len;
unsigned char __user *from = iov->iov_base; // 待发送数据块
iov++;
......
while (seglen > 0) {
int copy = 0;
int max = size_goal;
// 获取发送队列,列队最后一个skb,尝试将现在数据加入skb
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len;
}
if (copy <= 0) { // 需要申请新的skb
// 申请 skb,并添加到发送队列的尾部
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
skb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation);
if (!skb)
goto wait_for_memory;
......
// 把 skb 挂到socket的发送队列上
skb_entail(sk, skb);
copy = size_goal;
max = size_goal;
}
/* Try to append data to the end of skb. */
if (copy > seglen)
copy = seglen;
/* Where to copy to? */
// skb 中有⾜够的空间
if (skb_availroom(skb) > 0) {
// copy⽤户空间的数据到内核空间、计算校验和
// user space data ---- copy -----> skb
copy = min_t(int, copy, skb_availroom(skb));
err = skb_add_data_nocache(sk, skb, from, copy);
if (err)
goto do_fault;
} else {
......
}
......
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
// 发送数据
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now); // 发送
continue;
......
}
}
......
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss, int nonagle)
{
......
if (tcp_write_xmit(sk, cur_mss, nonagle, 0, sk_gfp_atomic(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp)
{
......
// 循环获取待发送的skb
while ((skb = tcp_send_head(sk))) {
......
// 滑动窗口管理
cwnd_quota = tcp_cwnd_test(tp, skb);
......
// 发送数据
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
repair:
tcp_event_new_data_sent(sk, skb);
tcp_minshall_update(tp, mss_now, skb);
sent_pkts += tcp_skb_pcount(skb);
if (push_one)
break;
}
if (likely(sent_pkts)) {
if (tcp_in_cwnd_reduction(sk))
tp->prr_out += sent_pkts;
/* Send one loss probe per tail loss episode. */
if (push_one != 2)
tcp_schedule_loss_probe(sk);
tcp_cwnd_validate(sk);
return false;
}
return (push_one == 2) || (!tp->packets_out && tcp_send_head(sk));
}
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask)
{
......
err = icsk->icsk_af_ops->queue_xmit(skb, &inet->cork.fl);
if (likely(err <= 0))
return err;
return net_xmit_eval(err);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
最终也调用到ip_local_out函数
网络层
int ip_local_out(struct sk_buff *skb)
{
int err;
err = __ip_local_out(skb); // 构造ip header,netfilter过滤
if (likely(err == 1)) // 允许数据通过
err = dst_output(skb);
return err;
}
int __ip_local_out(struct sk_buff *skb)
{
// 设置ip头
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph); // checksum
// netfilter的hook, iptables的实现
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL,
skb_dst(skb)->dev, dst_output);
}
static inline int dst_output(struct sk_buff *skb)
{
return skb_dst(skb)->output(skb); // 调用ip_output
}
int ip_output(struct sk_buff *skb)
{
......
// if !(IPCB(skb)->flags & IPSKB_REROUTED) 为真
// 将skb发给netfilter,过滤通过,则调用ip_finish_output
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
static int ip_finish_output(struct sk_buff *skb)
{
// 如果内核启用了 netfilter 和数据包转换(XFRM),
// 则更新 skb 的标志并通过 dst_output 来发送
#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
/* Policy lookup after SNAT yielded a new policy */
if (skb_dst(skb)->xfrm != NULL) {
IPCB(skb)->flags |= IPSKB_REROUTED;
return dst_output(skb);
}
#endif
// 如果数据包的长度大于 MTU 并且分片不会 offload 到设备,
// 则会调用 ip_fragment 在发送之前对数据包进行分片
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2);
else
return ip_finish_output2(skb);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
邻居子系统
重点来了!
调用ip_finish_output2到达邻居子系统。
static inline int ip_finish_output2(struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev; // 出口设备
......
rcu_read_lock_bh();
// 下一跳
nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr);
// 根据下一跳和设备名去arp缓存表查询,如果没有,则创建
neigh = __ipv4_neigh_lookup_noref(dev, nexthop);
if (unlikely(!neigh))
neigh = __neigh_create(&arp_tbl, &nexthop, dev, false);
if (!IS_ERR(neigh)) {
int res = dst_neigh_output(dst, neigh, skb);
rcu_read_unlock_bh();
return res;
}
rcu_read_unlock_bh();
kfree_skb(skb);
return -EINVAL;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 下一跳为网关,则返回网关地址。
- 下一跳为POD的IP地址,所以对于macvlan的网络架构来说,同一宿主机的两个POD之间互相访问,都会产生两条ARP表项。
查找ARP表项
__ipv4_neigh_lookup_noref是根据 出口设备“唯一标示”和目标ip 计算一个hash值,然后在 arp hash table中查找是否存在此arp项所以arp hash table里面存储的条目是全局的
- dev:可以到达neighbour的设备,是dev设备指针的值,而此时在内核态,所以可以看作是设备的唯一标示
- ip:L3层目标地址(下一跳地址)
static inline struct neighbour *__ipv4_neigh_lookup_noref(struct net_device *dev, u32 key)
{
struct neigh_hash_table *nht = rcu_dereference_bh(arp_tbl.nht);
struct neighbour *n;
u32 hash_val;
// 将dev指针传递给hash函数
hash_val = arp_hashfn(key, dev, nht->hash_rnd[0]) >> (32 - nht->hash_shift);
for (n = rcu_dereference_bh(nht->hash_buckets[hash_val]);
n != NULL;
n = rcu_dereference_bh(n->next)) {
if (n->dev == dev && *(u32 *)n->primary_key == key)
return n;
}
return NULL;
}
static inline u32 arp_hashfn(u32 key, const struct net_device *dev, u32 hash_rnd)
{
u32 val = key ^ hash32_ptr(dev); // 计算的是ip + dev指针,
return val * hash_rnd;
}
static inline u32 hash32_ptr(const void *ptr)
{
unsigned long val = (unsigned long)ptr;
#if BITS_PER_LONG == 64
val ^= (val >> 32);
#endif
return (u32)val;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
创建邻居表项
如果ARP缓存表不存在此项,则创建,创建失败,返回-EINVAL。这就是问题所在了,没有任何内核日志,返回一个有歧义的错误码,也就导致无法快速定位原因。
还好在linux kernel 5.x内核代码中,会打印报错信息:neighbour: arp_cache: neighbor table overflow!
struct neighbour *__neigh_create(struct neigh_table *tbl, const void *pkey,
struct net_device *dev, bool want_ref)
{
// 分配neighbour
//
struct neighbour *n1, *rc, *n = neigh_alloc(tbl, dev);
struct neigh_hash_table *nht;
if (!n) {
rc = ERR_PTR(-ENOBUFS);
goto out;
}
......
out:
return rc;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
分配neighbour,同时如果ARP缓存表超过gc_thresh3,则强制做一次gc。
如果gc没有回收任何过期ARP记录且表项数超过gc_thresh3,则返回NULL,标识分配邻居表项失败
// 分配失败,返回NULL
static struct neighbour *neigh_alloc(struct neigh_table *tbl, struct net_device *dev)
{
struct neighbour *n = NULL;
unsigned long now = jiffies;
int entries;
entries = atomic_inc_return(&tbl->entries) - 1;
// 如果超过gc_thres3或者
// 超过gc_thresh2且5秒没有刷新(HZ一般为1000)
// 则强制gc
if (entries >= tbl->gc_thresh3 ||
(entries >= tbl->gc_thresh2 &&
time_after(now, tbl->last_flush + 5 * HZ))) {
if (!neigh_forced_gc(tbl) &&
entries >= tbl->gc_thresh3)
goto out_entries; // arp表项超过阈值 且回收失败,
}
n = kzalloc(tbl->entry_size + dev->neigh_priv_len, GFP_ATOMIC);
......
out:
return n;
out_entries:
atomic_dec(&tbl->entries);
goto out;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
对ARP表进行垃圾回收,回收期间需要获取写锁。
如果成功回收则返回1,否则返回0
static int neigh_forced_gc(struct neigh_table *tbl)
{
// 获取 arp 缓存hash table 锁
write_lock_bh(&tbl->lock);
nht = rcu_dereference_protected(tbl->nht,
lockdep_is_held(&tbl->lock));
for (i = 0; i < (1 << nht->hash_shift); i++) {
struct neighbour *n;
struct neighbour __rcu **np;
np = &nht->hash_buckets[i];
while ((n = rcu_dereference_protected(*np,
lockdep_is_held(&tbl->lock))) != NULL) {
/* Neighbour record may be discarded if:
* - nobody refers to it.
* - it is not permanent
*/
write_lock(&n->lock);
if (atomic_read(&n->refcnt) == 1 &&
!(n->nud_state & NUD_PERMANENT)) {
rcu_assign_pointer(*np,
rcu_dereference_protected(n->next,
lockdep_is_held(&tbl->lock)));
n->dead = 1;
shrunk = 1;
write_unlock(&n->lock);
neigh_cleanup_and_release(n);
continue;
}
write_unlock(&n->lock);
np = &n->next;
}
}
tbl->last_flush = jiffies;
write_unlock_bh(&tbl->lock);
return shrunk;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
static inline int dst_neigh_output(struct dst_entry *dst, struct neighbour *n,
struct sk_buff *skb)
{
const struct hh_cache *hh;
if (dst->pending_confirm) {
unsigned long now = jiffies;
dst->pending_confirm = 0;
/* avoid dirtying neighbour */
if (n->confirmed != now)
n->confirmed = now;
}
hh = &n->hh;
// 如果下面三种情况之一,不需要ARP请求
// NUD_PERMANENT : 静态路由
// NUD_NOARP:多播地址,广播地址或者本地环回设备lookback
// NUD_REACHABLE:邻居表项状态是reachable
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len)
return neigh_hh_output(hh, skb);
else
return n->output(n, skb); // 非连接状态, neigh_resolve_output
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
ARP
下面的源码分析其实已经不重要了,
neigh_resolve_output会间接调用函数neigh_event_send(),实现邻居项状态从 NUD_NONE 到 NUD_INCOMPLETTE 状态的改变
/* Slow and careful. */
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb)
{
......
// 发送arp请求
if (!neigh_event_send(neigh, skb)) {
// 如果neigh已经连接,则发送skb
int err;
struct net_device *dev = neigh->dev;
unsigned int seq;
if (dev->header_ops->cache && !neigh->hh.hh_len)
neigh_hh_init(neigh, dst); // 初始化mac缓存值
do {
__skb_pull(skb, skb_network_offset(skb));
seq = read_seqbegin(&neigh->ha_lock);
err = dev_hard_header(skb, dev, ntohs(skb->protocol),
neigh->ha, NULL, skb->len);
} while (read_seqretry(&neigh->ha_lock, seq));
if (err >= 0)
rc = dev_queue_xmit(skb); // 真正发送数据
else
goto out_kfree_skb;
}
......
}
EXPORT_SYMBOL(neigh_resolve_output);
static inline int neigh_event_send(struct neighbour *neigh, struct sk_buff *skb)
{
......
if (!(neigh->nud_state&(NUD_CONNECTED|NUD_DELAY|NUD_PROBE)))
return __neigh_event_send(neigh, skb);
return 0;
}
int __neigh_event_send(struct neighbour *neigh, struct sk_buff *skb)
{
write_lock_bh(&neigh->lock);
......
// 初始化阶段
if (!(neigh->nud_state & (NUD_STALE | NUD_INCOMPLETE))) {
if (neigh->parms->mcast_probes + neigh->parms->app_probes) {
unsigned long next, now = jiffies;
atomic_set(&neigh->probes, neigh->parms->ucast_probes);
neigh->nud_state = NUD_INCOMPLETE; // 设置表项尾incomplete
neigh->updated = now;
next = now + max(neigh->parms->retrans_time, HZ/2);
neigh_add_timer(neigh, next); // 定时器:刷新状态后在neigh_update中发送skb
immediate_probe = true;
} else {
......
}
......
}
if (neigh->nud_state == NUD_INCOMPLETE) {
if (skb) {
while (neigh->arp_queue_len_bytes + skb->truesize >
neigh->parms->queue_len_bytes) {
struct sk_buff *buff;
// 丢弃
buff = __skb_dequeue(&neigh->arp_queue);
if (!buff)
break;
neigh->arp_queue_len_bytes -= buff->truesize;
kfree_skb(buff);
NEIGH_CACHE_STAT_INC(neigh->tbl, unres_discards);
}
skb_dst_force(skb);
__skb_queue_tail(&neigh->arp_queue, skb); //报文放入arp_queue队列中,arp_queue 队列用于缓存等待发送的数据包
neigh->arp_queue_len_bytes += skb->truesize;
}
rc = 1;
}
out_unlock_bh:
if (immediate_probe)
neigh_probe(neigh); // 进行探测,发送arp
else
write_unlock(&neigh->lock);
local_bh_enable();
return rc;
}
EXPORT_SYMBOL(__neigh_event_send);
static void neigh_probe(struct neighbour *neigh)
__releases(neigh->lock)
{
struct sk_buff *skb = skb_peek(&neigh->arp_queue); // 取出报文
/* keep skb alive even if arp_queue overflows */
if (skb)
skb = skb_copy(skb, GFP_ATOMIC);
write_unlock(&neigh->lock);
neigh->ops->solicit(neigh, skb); // 发送arp请求,arp_solicit
atomic_inc(&neigh->probes);
kfree_skb(skb);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
ARP响应的处理
static struct packet_type arp_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_ARP),
.func = arp_rcv,
};
void __init arp_init(void)
{
neigh_table_init(&arp_tbl);
dev_add_pack(&arp_packet_type); // add packet handler
......
}
static int arp_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt, struct net_device *orig_dev)
{
......
return NF_HOOK(NFPROTO_ARP, NF_ARP_IN, skb, dev, NULL, arp_process);
}
static int arp_process(struct sk_buff *skb) {
......
n = __neigh_lookup(&arp_tbl, &sip, dev, 0);
if (n) {
// 更新邻居项
neigh_update(n, sha, state, override ? NEIGH_UPDATE_F_OVERRIDE : 0);
}
......
}
int neigh_update(struct neighbour *neigh, const u8 *lladdr, u8 new, u32 flags)
{
......
write_lock_bh(&neigh->lock);
......
if (new & NUD_CONNECTED)
neigh_connect(neigh);
else
neigh_suspect(neigh);
if (!(old & NUD_VALID)) { // 源状态不为valid,则发送缓存的skb
struct sk_buff *skb;
while (neigh->nud_state & NUD_VALID &&
(skb = __skb_dequeue(&neigh->arp_queue)) != NULL) {
struct dst_entry *dst = skb_dst(skb);
struct neighbour *n2, *n1 = neigh;
write_unlock_bh(&neigh->lock);
rcu_read_lock();
n2 = NULL;
if (dst) {
n2 = dst_neigh_lookup_skb(dst, skb);
if (n2)
n1 = n2;
}
n1->output(n1, skb); // 调用neigh的output函数,此时已经改成connect函数
if (n2)
neigh_release(n2);
rcu_read_unlock();
write_lock_bh(&neigh->lock);
}
skb_queue_purge(&neigh->arp_queue);
neigh->arp_queue_len_bytes = 0;
}
......
write_unlock_bh(&neigh->lock);
......
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
自旋锁
对邻居表进行修改需要获取写锁,而这个锁的实现为自旋锁。
static inline void __raw_write_lock_bh(rwlock_t *lock)
{
local_bh_disable();
preempt_disable();
rwlock_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_write_trylock, do_raw_write_lock);
}
# define do_raw_write_trylock(rwlock) arch_write_trylock(&(rwlock)->raw_lock)
static inline void arch_write_lock(arch_rwlock_t *rw)
{
u32 val = __insn_fetchor4(&rw->lock, __WRITE_LOCK_BIT);
if (unlikely(val != 0))
__write_lock_failed(rw, val);
}
/*
* If we failed because there were readers, clear the "writer" bit
* so we don't block additional readers. Otherwise, there was another
* writer anyway, so our "fetchor" made no difference. Then wait,
* issuing periodic fetchor instructions, till we get the lock.
*/
void __write_lock_failed(arch_rwlock_t *rw, u32 val)
{
int iterations = 0;
do {
if (!arch_write_val_locked(val))
val = __insn_fetchand4(&rw->lock, ~__WRITE_LOCK_BIT);
delay_backoff(iterations++);
val = __insn_fetchor4(&rw->lock, __WRITE_LOCK_BIT);
} while (val != 0);
}
EXPORT_SYMBOL(__write_lock_failed);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
根本原因
原因已经明确了,由于POD之间通信都会产生2条ARP记录缓存在ARP表中,如果宿主机上POD较多,则ARP表项会很多,而linux对ARP大小是有限制的。
ARP表项相关的内核参数
ARP表垃圾回收机制
表的垃圾回收分为同步和异步:
- 同步:neigh_alloc函数被调用时执行
- 异步:gc_interval指定的周期性gc
回收策略
- arp 表项数量 < gc_thresh1:不做处理
- gc_thresh1 =< arp 表项数量 <= gc_thresh2:按照 gc_interval 定期启动ARP表垃圾回收
- gc_thresh2 < arp 表项数量 <= gc_thresh3,5 * HZ(一般5秒)后ARP表垃圾回收
- arp 表项数量 > gc_thresh3:立即启动ARP表垃圾回收
ARP表项状态转换
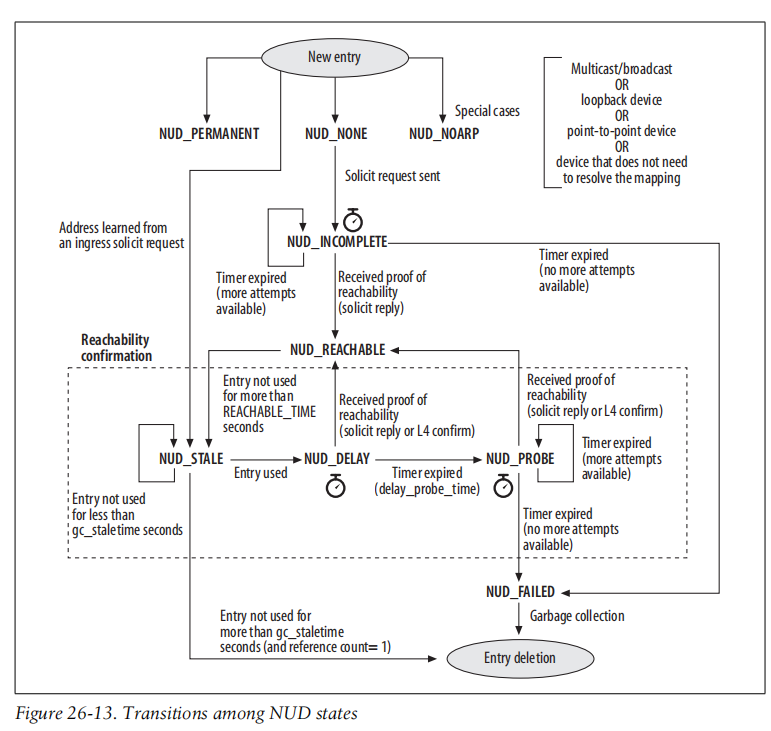
图来源于《Understanding Linux Network Internals》
如图所示,只有两种状态的ARP记录才能被回收:
- stale状态过期后
- failed状态
结论
由于我们kubernetes是基于macvlan网络的,所以会为每个POD分配一个mac地址,这样同一台宿主机的POD之间访问,就会产生2条ARP表项。
所以,当ARP表项超过gc_thresh3,则会触发回收ARP表,当没有可回收的表项时,则会导致neigh_create分配失败,从而导致系统调用失败。
那么上层应用层很可能会进行不断重试,也会有其他流量调用内核发送数据,最终只要数据接收方的ARP记录不在ARP表中,都会导致进行垃圾回收,而垃圾回收需要加写锁后再对ARP表进行遍历,这个遍历虽然耗时不长,但是持写锁时间 * 回收次数 导致持写锁的总体时间很长,这样就导致大量的锁竞争(自旋),导致CPU暴涨,从而引发故障。
验证
- 先将gc_thresh改小
- ping下其他POD,让ARP表大小达到阈值
[root@d /]# ip neigh
10.170.254.32 dev eth0 lladdr 02:00:0a:aa:fe:20 REACHABLE
10.170.254.1 dev eth0 lladdr 2c:21:31:79:96:c0 REACHABLE
10.170.254.27 dev eth0 lladdr 02:00:0a:aa:fe:1b REACHABLE
10.170.254.24 dev eth0 lladdr 02:00:0a:aa:fe:18 REACHABLE
10.170.254.25 dev eth0 lladdr 02:00:0a:aa:fe:19 REACHABLE
10.170.254.30 dev eth0 lladdr 02:00:0a:aa:fe:1e REACHABLE
10.170.254.28 dev eth0 lladdr 02:00:0a:aa:fe:1c REACHABLE
10.170.254.29 dev eth0 lladdr 02:00:0a:aa:fe:1d REACHABLE- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- ping下不在ARP表中的POD,发现ping命令“卡住了”
- 再将
gc_thresh改大
- ping命令立即恢复了
[root@dns-8685bbc547-4dmld tmp]# ping 10.170.254.10
PING 10.170.254.10 (10.170.254.10) 56(84) bytes of data.
64 bytes from 10.170.254.10: icmp_seq=125 ttl=64 time=2004 ms
64 bytes from 10.170.254.10: icmp_seq=126 ttl=64 time=1004 ms
64 bytes from 10.170.254.10: icmp_seq=127 ttl=64 time=4.04 ms
64 bytes from 10.170.254.10: icmp_seq=128 ttl=64 time=0.022 ms
64 bytes from 10.170.254.10: icmp_seq=129 ttl=64 time=0.021 ms
64 bytes from 10.170.254.10: icmp_seq=130 ttl=64 time=0.020 ms- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
总结
当将线上kubernetes宿主机的ARP参数都改大后,再也没有出现过此类问题了。
虽然问题发生在kubernetes上,但是本质还是由于对底层OS不了解导致的。















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









