






一次Flink on yarn 任务JobManager内存超用问题排查
事件背景
有道实时平台的所有flink任务运行在yarn集群上,前段时间,为提升和改善有道flink任务运行稳定性,对实时yarn集群进行了迁移(将实时yarn nodemanger机器进行独立,并将所有实时任务迁移至新机器上)。迁移后,发现约200个任务频繁发生JobManager重试,几乎每30min出现一次重试,严重影响任务稳定性。
yarn看到flink任务的application_id在不断attempt重试,几乎每30min重试一次。
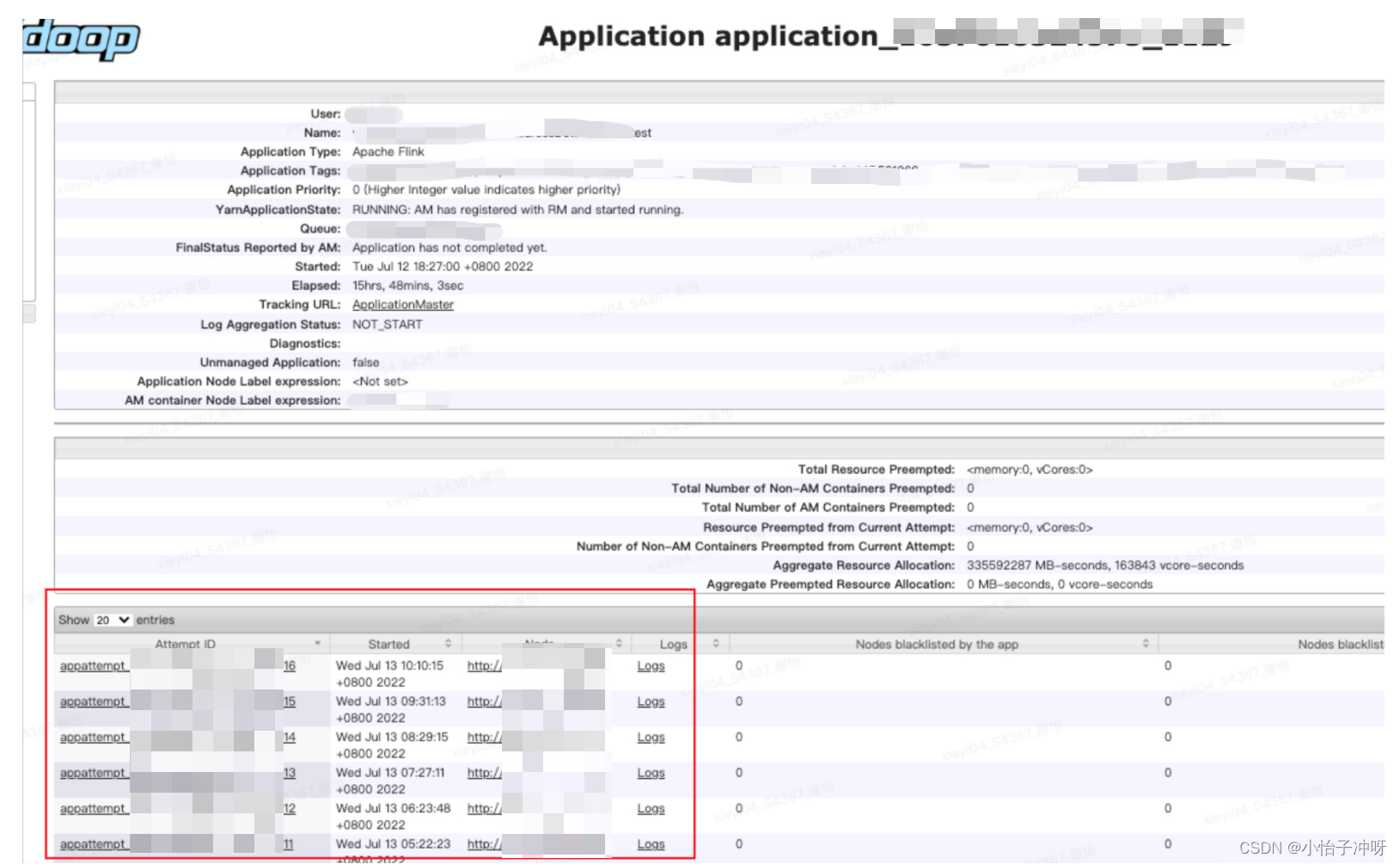
点击失败的一次“Attempt ID”,查看失败原因。
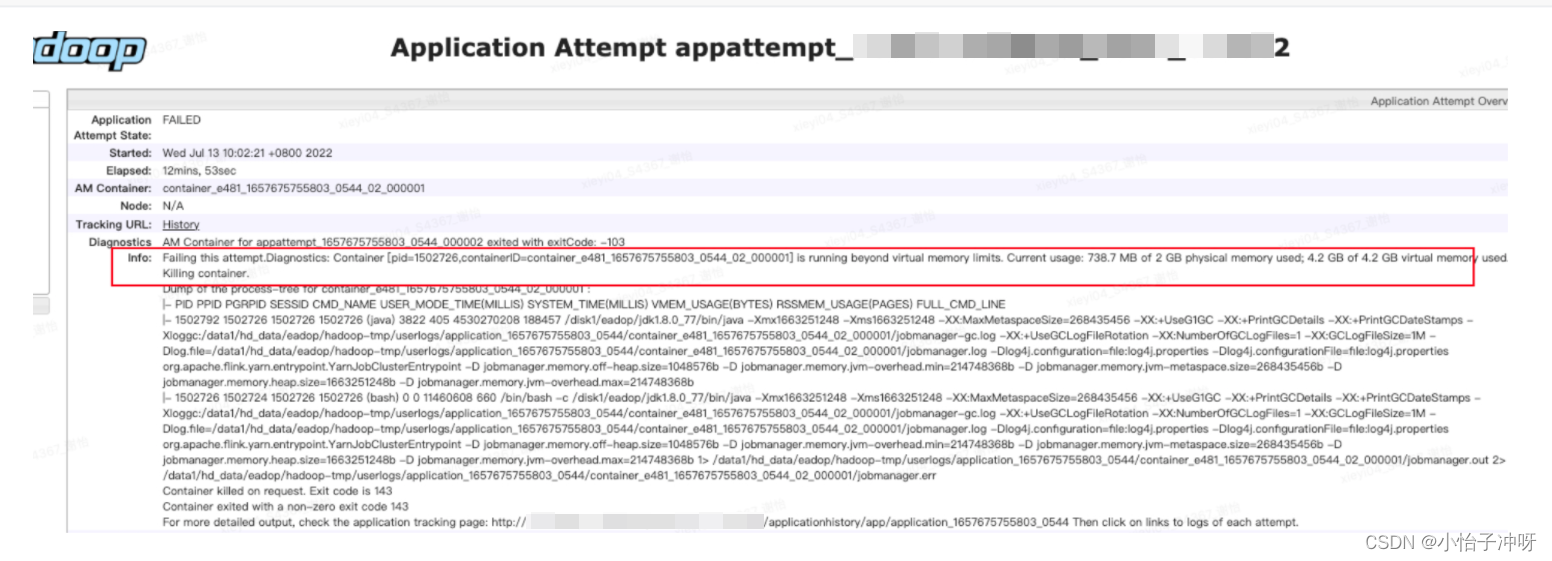
其中约4/5的任务,JobManager(am)container 由于虚拟内存超用被yarn kill了
Failing this attempt.Diagnostics: Container [pid=****,containerID=container_****] is running beyond virtual memory limits. Current usage: 738.7 MB of 2 GB physical memory used; 4.2 GB of 4.2 GB virtual memory used. Killing container.
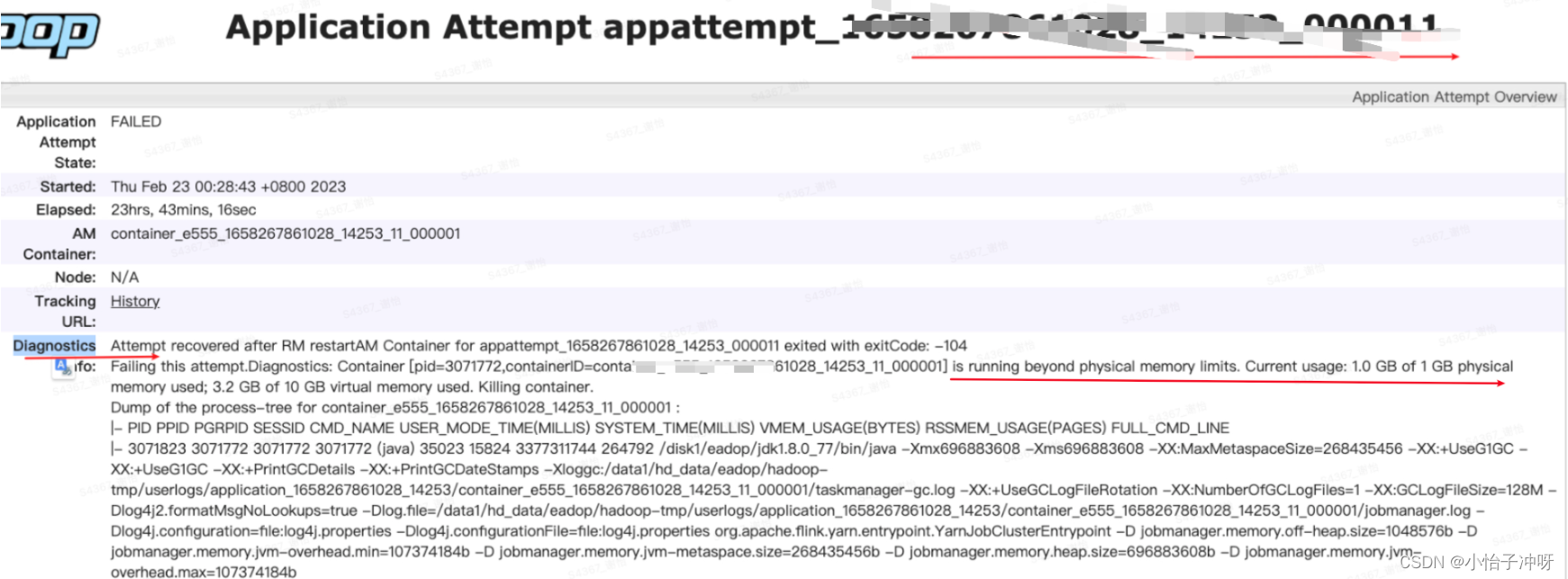
1/5的任务,由于JobManager物理内存超用被yarn kill了
Container [pid=3071772,containerID=container_****] is running beyond physical memory limits. Current usage: 4.0 GB of 4 GB physical memory used; 6.2 GB of 8.4 GB virtual memory used. Killing container.
flink on yarn内存说明
在实时平台(sloth)上,用户可为每个任务进行资源设置,包括:JobManager(如图JM内存)、TaskManager(如图TM内存)内存资源。对应的flink参数为:
JobManager总体内存:jobmanager.memory.process.size
TaskManager总体内存:taskmanager.memory.process.size
先简单介绍一下flink on yarn是如何运行的,以及yarn上如何管理flink任务的内存。
flink的运行组件主要包括JobManager、TaskManager。用户从实时计算平台提交flink任务,会以container的形式运行在yarn nodemanager上
Nodemanager服务会对运行在上面的container进行内存(物理内存和虚拟内存)监控和管理,如果仔细查看Yanr Nodemanager的运行日志,会发现如下日志。当container的物理内存或虚拟内存超过上限后,yarn会kill相应 container,如前文的现象所述。
2022-07-15 11:04:10,631 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Memory usage of ProcessTree 114400 for container-id container_****_10_000001: 1.5 GB of 2 GB physical memory used; 4.7 GB of 8 GB virtual memory used
NodeManager内存管理规则如下:
(1)yarn虚拟内存管理
yarn通过两个参数对运行在nodemanager上的container进行管理,
参数1 :yarn.nodemanager.vmem-check-enabled(默认true)
含义:是否对container实行虚拟内存限制
参数2:yarn.nodemanager.vmem-pmem-ratio(默认2.1)
含义:nodemanger运行container的虚拟内存与物理内存的比例。
以默认参数进行说明,若jobmanager.memory.process.size设置为2G,则yarn限制container虚拟内存为4.2G,当虚拟内存超过4.2G时,yarn会kill该container
(2)物理内存管理
同样,若container使用物理内存超过了2G,yarn也会kill该container
排查问题
调整yarn虚拟内存比例
约4/5的任务出现虚拟内存超用,可以先暂时增大yarn.nodemanager.vmem-pmem-ratio比例,进行观察,若虚拟内存不会持续增大,而是维持在一定范围,那么可以降低由于虚拟内存过大被kill的概率。
修改yarn nodemanger端的yarn-site.xml,将yarn.nodemanager.vmem-pmem-ratio修改为4(默认为2.1),重启nodemanager和flink任务。
调整参数后,发现大部分任务运行良好,没有被kill,观察任务,虚拟内存使用约4.65G,物理内存使用约1.5G
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
115042 sloth 20 0 4886176 1.5g 13008 S 0.7 0.4 6:36.74 java
随机挑选了多个迁移后的flink任务,JobManager物理内存使用在1.2G~1.5G左右,并且这几个任务不是flink cdc任务,理论上JobManager占用内存不会如此高。
而随机挑选了几个运行在旧集群的flink任务,JobManager物理内存在700M左右
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
66751 sloth 20 0 2544092 759640 14320 S 0.7 0.2 266:08.25 java
为何迁移新集群后,物理内存占用会上涨这么多呢?需要探究一下原因,并且需确认,物理内存是否会持续上涨,如果持续上涨,可能任务会发生物理内存超用被kill的情况。同时,针对少量物理内存超用的任务,也需按照同样的思路探究原因。
JobManager内存组成结构
主要包括如下组成部分
Off-Heap Memory(flink默认128M):包括DirectMemory和其他Native 方法使用的内存。DirectMemory主要为进行NIO 使用的native memory
JVM Metaspace(flink默认256 M):元数据区,保存JVM类信息与方法等,通过-XX:MaxMetaspaceSize限制上限
JVM Overhead(flink默认0.1):为其他Native Memory保留的部分内存区域
JVM Heap(flink默认未设置):JobManager的堆内存区域

本次排查的任务中,jobmanager.memory.jvm-overhead.fraction设置为0.2,jobmanager.memory.process.size(总内存) 为2G,未设置Heap 内存,则Heap内存大小=总内存-Off-Heap Memory内存大小-JVM Metaspace内存大小-JVM Overhead内存大小
排查堆内内存使用
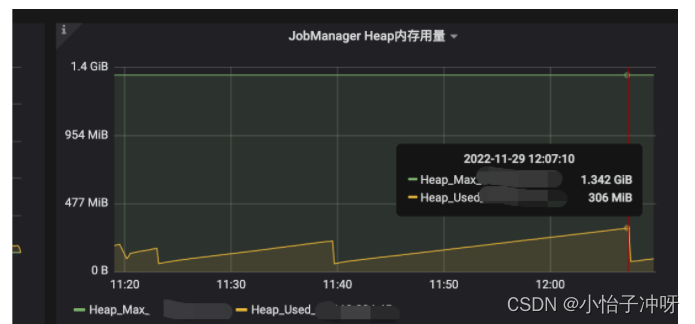
首先,flink metric提供了jobmanger和Taskmanager Heap使用情况的相关指标(https://nightlies.apache.org/flink/flink-docs-release-1.12/ops/metrics.html#memory),排查发现,Heap长期使用维持300M~400M左右,未发现Heap Full GC或OOM,说明是其他区域内存使用较高,需要排查堆外内存使用情况。
排查堆外内存使用
使用NMT(Native Memory Tracking,JVM native memory诊断工具)https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html,用于定位堆外内存使用情况
首先,对flink任务开启NMT,便于后续进行追踪,设置方法:
env.java.opts.jobmanager:-XX:NativeMemoryTracking=summary
env.java.opts.taskmanager:-XX:NativeMemoryTracking=summary
任务运行一段时间后,便可观察和追踪内存使用情况。
首先观察任务jobmanager 使用的物理内存,RES为1.5G
top -p 115042
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
115042 sloth 20 0 4886176 1.5g 13008 S 0.7 0.4 6:36.74 java
观察Heap使用情况,发现堆内存大小分配了1588.0MB,使用了303M左右,而物理内存大小为1.5G,也证实了需要排查堆外使用情况
jmap -heap 115042
using thread-local object allocation.
Garbage-First (G1) GC with 63 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1665138688 (1588.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 998244352 (952.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 268435456 (256.0MB)
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 1588
capacity = 1665138688 (1588.0MB)
used = 317988336 (303.25730895996094MB)
free = 1347150352 (1284.742691040039MB)
19.096807869015173% used
G1 Young Generation:
Eden Space:
regions = 176
capacity = 979369984 (934.0MB)
used = 184549376 (176.0MB)
free = 794820608 (758.0MB)
18.843683083511777% used
Survivor Space:
regions = 66
capacity = 69206016 (66.0MB)
used = 69206016 (66.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 62
capacity = 616562688 (588.0MB)
used = 64232944 (61.25730895996094MB)
free = 552329744 (526.7426910400391MB)
10.417909687068187% used
通过Native Memory Tracking追踪当前进程的内存使用情况
命令
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale=KB | MB | GB]
通过Native Memory Tracking,我们发现,Thread stack占用了914M,含有908个线程,每个线程栈大小为1M,这个值是偏高的(这里有个奇怪的现象,NativeMemoryTracking追踪到进程使用了3189MB,但实际RES只有1.5G,为何NativeMemory的追踪结果会偏高这么多,还有一些不确定的原因)
同时注意:Native Memory Tracking不追踪非JVM代码的Nativer Memory分配,比如TaskManager中用于RocksDB状态管理的堆外内存使用,使用该工具是无法追踪到的。不过对于flink JobManager,重要的堆外内存区域都能通过NMT追踪到
## 总物理内存申请量为3189MB
Total: reserved=4410MB, committed=3189MB
##堆内存使用1588MB
- Java Heap (reserved=1588MB, committed=1588MB)
(mmap: reserved=1588MB, committed=1588MB)
##元数据区,占用了77MB ,加载12035个类
- Class (reserved=1092MB, committed=77MB)
(classes #12035)
(malloc=2MB #20406)
(mmap: reserved=1090MB, committed=76MB)
##线程栈占用了 914MB,908个线程数,每个线程栈占用大小受-Xss限制
- Thread (reserved=914MB, committed=914MB)
(thread #908)
(stack: reserved=910MB, committed=910MB)
(malloc=3MB #4616)
(arena=2MB #1814)
- Code (reserved=251MB, committed=47MB)
(malloc=7MB #12194)
(mmap: reserved=244MB, committed=40MB)
##进行GC占用的内存,116M,如标记数,GC root等
- GC (reserved=225MB, committed=225MB)
(malloc=134MB #23499)
(mmap: reserved=91MB, committed=91MB)
- Compiler (reserved=2MB, committed=2MB)
(malloc=2MB #2458)
##DirectMemory占用的内存,通过-XX:MaxDirectMemorySize限制大小
- Internal (reserved=312MB, committed=312MB)
(malloc=312MB #33051)
- Symbol (reserved=19MB, committed=19MB)
(malloc=17MB #150661)
(arena=2MB #1)
##开启Native Memory Tracking占用的内存
- Native Memory Tracking (reserved=4MB, committed=4MB)
(tracking overhead=4MB)
- Unknown (reserved=3MB, committed=0MB)
(mmap: reserved=3MB, committed=0MB)
为何RES和NMT追踪到的内存大小差别如此大,笔者进行了简单验证,将JobManager 的NativeMemoryTracking开启为detail级别,可以追踪到JVM各部分内存的虚拟地址分配
env.java.opts.jobmanager:-XX:NativeMemoryTracking=detail
任务运行一段时间后,使用NativeMemoryTracking进行诊断
jcmd <pid> VM.native_memory detail
如下所示,Native Memory Tracking追踪到使用了3016403KB,与前面设置summary 级别的内存使用时接近的
Native Memory Tracking:
Total: reserved=4267067KB, committed=3016403KB
- Java Heap (reserved=1406976KB, committed=1406976KB)
(mmap: reserved=1406976KB, committed=1406976KB)
- Class (reserved=1126215KB, committed=86751KB)
(classes #13134)
(malloc=1863KB #23344)
(mmap: reserved=1124352KB, committed=84888KB)
- Thread (reserved=937354KB, committed=937354KB)
(thread #909)
(stack: reserved=932764KB, committed=932764KB)
(malloc=2950KB #4621)
(arena=1639KB #1816)
- Code (reserved=256758KB, committed=48306KB)
(malloc=7158KB #12721)
(mmap: reserved=249600KB, committed=41148KB)
- GC (reserved=222422KB, committed=222422KB)
(malloc=137442KB #24817)
(mmap: reserved=84980KB, committed=84980KB)
- Compiler (reserved=899KB, committed=899KB)
(malloc=769KB #997)
(arena=131KB #3)
- Internal (reserved=288504KB, committed=288504KB)
(malloc=288472KB #36185)
(mmap: reserved=32KB, committed=32KB)
- Symbol (reserved=20379KB, committed=20379KB)
(malloc=18485KB #165219)
(arena=1894KB #1)
- Native Memory Tracking (reserved=4568KB, committed=4568KB)
(malloc=288KB #4125)
(tracking overhead=4280KB)
- Arena Chunk (reserved=244KB, committed=244KB)
(malloc=244KB)
- Unknown (reserved=2748KB, committed=0KB)
(mmap: reserved=2748KB, committed=0KB)
同时,在detail级别下,我们可以看到JVM各部分内存的虚拟地址分配,如下面为Heap 申请的虚拟地址范围
[0x00000000aa200000 - 0x0000000100000000] reserved 1406976KB for Java Heap from
[0x00007f6f30985ad2] ReservedSpace::initialize(unsigned long, unsigned long, bool, char*, unsigned long, bool)+0xc2
[0x00007f6f309864ae] ReservedHeapSpace::ReservedHeapSpace(unsigned long, unsigned long, bool, char*)+0x6e
[0x00007f6f30953a0b] Universe::reserve_heap(unsigned long, unsigned long)+0x8b
[0x00007f6f3046c720] G1CollectedHeap::initialize()+0x130
[0x00000000aa200000 - 0x0000000100000000] committed 1406976KB from
[0x00007f6f3048f7bf] G1PageBasedVirtualSpace::commit_internal(unsigned long, unsigned long)+0xbf
[0x00007f6f3048fa4c] G1PageBasedVirtualSpace::commit(unsigned long, unsigned long)+0x11c
[0x00007f6f30492690] G1RegionsLargerThanCommitSizeMapper::commit_regions(unsigned int, unsigned long)+0x40
[0x00007f6f304f4b77] HeapRegionManager::commit_regions(unsigned int, unsigned long)+0x77
下面为Thread stack申请的虚拟地址范围
[0x00007f6eb0548000 - 0x00007f6eb0649000] reserved and committed 1028KB for Thread Stack from
[0x00007f6f301eafc9] attach_listener_thread_entry(JavaThread*, Thread*)+0x29
[0x00007f6f30938dcf] JavaThread::thread_main_inner()+0xdf
[0x00007f6f30938efc] JavaThread::run()+0x11c
[0x00007f6f307ec9d8] java_start(Thread*)+0x108
同样,我们使用pmap,观察JobManager进程的内存使用情况
命令
pmap -x -p <PID>
截取如下部分信息,使用上述通过NMT返回的虚拟地址范围,与如下的Address对照,可大致确定各部分区域的内存使用情况
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 4 4 0 r-x-- java
0000000000600000 4 4 4 rw--- java
0000000000961000 39020 39020 39020 rw--- [ anon ]
00000000aa200000 1417624 960100 960100 rw--- [ anon ]
0000000100a66000 1037928 0 0 ----- [ anon ]
00007f6eb0146000 12 0 0 ----- [ anon ]
00007f6eb0149000 1016 12 12 rw--- [ anon ]
00007f6eb0247000 12 0 0 ----- [ anon ]
00007f6eb024a000 1528 392 392 rw--- [ anon ]
00007f6eb03c8000 1536 0 0 ----- [ anon ]
00007f6eb0548000 12 0 0 ----- [ anon ]
00007f6eb054b000 1016 24 24 rw--- [ anon ]
00007f6eb0649000 12 0 0 ----- [ anon ]
00007f6eb064c000 1016 24 24 rw--- [ anon ]
00007f6eb074a000 12 0 0 ----- [ anon ]
......
00007f6f31ad4000 4 4 4 r---- ld-2.17.so
00007f6f31ad5000 4 4 4 rw--- ld-2.17.so
00007f6f31ad6000 4 4 4 rw--- [ anon ]
00007ffe188bc000 144 48 48 rw--- [ stack ]
00007ffe189d0000 16 0 0 r---- [ anon ]
00007ffe189d4000 8 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 r-x-- [ anon ]
---------------- ------- ------- -------
total kB 4617056 1442172 1403660
我们发现,占用较多物理内存的部分是java Heap,RSS为960100。
而对于Thread stack,如00007f6eb0548000~00007f6eb0649000,虽然虚拟内存申请了1028KB,而RSS占用24KB,可能JVM Heap和Thread stack的内存申请和释放机制不同,虽然预申请了1028KB,但不会长期驻留,具体原因目前不知,希望有机会再深入探究。
回到JobManager的内存分配,总体内存为2G,Heap xms和 xmx为1374M,并且Heap 申请的内存会长期驻留,JobManager的总体内存为2G,那么其余区域(如:Thread stack、Metaspace、DirectMemory)使用余下的内存空间,如果这些区域出现较多的增长,可能会导致总体内存超用。如本文线程数较高,若出现线程数逐渐上涨,或单个线程占用较多内存,可能出现总体内存超用。因此建议增大jobmanager.memory.jvm-overhead.fraction,给堆外预留更多的内存空间。
另一方面,担心如果线程数和总体物理内存不断上涨,那么这些线上任务在运行一段时间后,可能仍然会出现物理内存超用的情况。于是对JobManager的线程数和物理内存大小进行监控。监控发现,在任务启动初期,线程数在快速增加,幸运的是,线程数达到一定值后,就没有在上升了,也就是说Thread stack的内存占用会稳定在某个范围,任务内存继续上涨的可能性较低。
time:2022-07-15 17:15:34 PID:1596263 thread count: 389
time:2022-07-15 17:45:34 PID:1596263 thread count: 573
time:2022-07-15 18:15:34 PID:1596263 thread count: 618
time:2022-07-15 18:45:34 PID:1596263 thread count: 701
time:2022-07-15 19:15:34 PID:1596263 thread count: 746
time:2022-07-15 19:45:34 PID:1596263 thread count: 791
time:2022-07-15 20:15:34 PID:1596263 thread count: 836
time:2022-07-15 20:45:34 PID:1596263 thread count: 883
time:2022-07-15 21:15:34 PID:1596263 thread count: 897
time:2022-07-15 21:45:34 PID:1596263 thread count: 897
time:2022-07-15 22:15:34 PID:1596263 thread count: 897
time:2022-07-15 22:45:34 PID:1596263 thread count: 897
time:2022-07-15 23:15:34 PID:1596263 thread count: 897
time:2022-07-16 00:15:34 PID:1596263 thread count: 897
time:2022-07-16 00:45:34 PID:1596263 thread count: 897
time:2022-07-16 01:15:34 PID:1596263 thread count: 897
time:2022-07-16 01:45:34 PID:1596263 thread count: 897
time:2022-07-16 02:15:34 PID:1596263 thread count: 897
time:2022-07-16 02:45:34 PID:1596263 thread count: 897
time:2022-07-16 03:15:34 PID:1596263 thread count: 897
time:2022-07-16 03:45:34 PID:1596263 thread count: 897
同时,任务运行一段时间后,观察到大部分任务 JobManager 物理内存使用维持在1.2G~1.5G,没有持续升高。那么可以暂时认为在JobManager总体内存设置为2G的情况下,大部分任务是能够正常运行的。
不过我们可以探索一下,为何迁移到新集群后,JobManager线程数如此高,我们用Jstack查看一下线程有何异样
命令:
jstack <pid>
其中有两类线程较高
cluster-io-thread**这个线程池有384个
"cluster-io-thread-384" #2761 daemon prio=5 os_prio=0 tid=0x00007f011ce28800 nid=0x387f1e waiting on condition [0x00007f00c28ea000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000d8cb6b00> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
flink-rest-server-netty-worker-thread有192个线程
"flink-rest-server-netty-worker-thread-192" #771 daemon prio=5 os_prio=0 tid=0x00007f011455a800 nid=0x33c8a4 runnable [0x00007f00db667000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000d953c2b0> (a org.apache.flink.shaded.netty4.io.netty.channel.nio.SelectedSelectionKeySet)
- locked <0x00000000d953d3b0> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000d953d2d8> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.apache.flink.shaded.netty4.io.netty.channel.nio.SelectedSelectionKeySetSelector.select(SelectedSelectionKeySetSelector.java:68)
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:810)
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:457)
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989)
at org.apache.flink.shaded.netty4.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at java.lang.Thread.run(Thread.java:745)
观察一下旧集群上的JobManager线程情况呢,总线程数366个,是新集群的1/3左右,
ps huH p 31204 |wc -l
373
其中,cluster-io-thread线程数128个,是新集群的1/3。flink-rest-server-netty-worker-thread线程数64个,是新集群的1/3。
"cluster-io-thread-128" #956 daemon prio=5 os_prio=0 tid=0x00007f5d5cd8f000 nid=0x160c8 waiting on condition [0x00007f5d0fe16000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000df5a5ca8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"flink-rest-server-netty-worker-thread-64" #626 daemon prio=5 os_prio=0 tid=0x00007f5d48adf000 nid=0x420a runnable [0x00007f5d1384e000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:79)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000df9d7628> (a org.apache.flink.shaded.netty4.io.netty.channel.nio.SelectedSelectionKeySet)
- locked <0x00000000df9d8728> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000df9d8650> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.apache.flink.shaded.netty4.io.netty.channel.nio.SelectedSelectionKeySetSelector.select(SelectedSelectionKeySetSelector.java:68)
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:803)
at org.apache.flink.shaded.netty4.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:457)
at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989)
at org.apache.flink.shaded.netty4.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at java.lang.Thread.run(Thread.java:745)
cluster-io这个线程池是怎么创建的呢
查看flink代码org.apache.flink.runtime.entrypoint.ClusterEntrypoint
ioExecutor =
Executors.newFixedThreadPool(
ClusterEntrypointUtils.getPoolSize(configuration),
new ExecutorThreadFactory("cluster-io"));
public static int getPoolSize(Configuration config) {
final int poolSize =
config.getInteger(
ClusterOptions.CLUSTER_IO_EXECUTOR_POOL_SIZE,
4 * Hardware.getNumberCPUCores());
发现这是一个newFixedThreadPool线程池,线程池默认大小为4*cpu cores,可通过cluster.io-pool.size(https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/config/#cluster-io-pool-size)这项参数进行设置,看上去是为了更好地利用多核cpu的优势,提高并发能力,因此默认设置与cpu cores成正比。同时也确定该线程数不会持续上升。
我们分别看一下迁移前后的机器cpu cores
旧集群,32个逻辑cpu cores
$ cat /proc/cpuinfo |grep "processor"|wc -l
32
cluster-io线程池大小为128 = 32*4
新集群,96个逻辑cpu cores,是旧集群的3倍。
sh-4.2# cat /proc/cpuinfo |grep "processor"|wc -l
96
cluster-io线程池大小为384 = 96*4
同样,对于“flink-rest-server-netty-worker”,迁移后的线程数是迁移前的3倍,其线程数大小可能也是与cpu cores有关,这里就不探究了。
通过线程数和cpu核数,一定程度上证实了,为何任务迁移到新机器后,物理内存和虚拟内存使用会上涨。同时,结合监控,新集群大部分任务JobManager的线程数量和物理内存使用不会持续上涨,而是维持在1.5G左右。因此,对于新集群的实时任务JobManager,设置2G的整体内存是可以正常运行的,不过仍然建议增大jobmanager.memory.jvm-overhead.fraction,降低物理内存超用的概率。对于少部分物理内存超用的任务,需要增大jobmanager.memory.jvm-overhead.fraction,给堆外内存区域预留更多的内存空间。
排查结论
问题描述:将flink任务迁移到新yarn nodemanager 集群后,约200个任务频繁发生JobManager重试,原因为虚拟内存或物理内存超过上限,导致被yarn kill。
排查和解决问题方面:
(1)首先调整了yarn nodemanager端对虚拟内存的设置比例,降低JobManager所在的container由于虚拟内存超用被kill的概率
(2)同时发现迁移新集群后,JobManager的物理内存大小相对旧集群有较大上涨,需探究物理内存占用上涨的原因,并确定物理内存是否会不断升高
(3)通过监控指标发现JobManager Heap内存占用维持在300M~400M左右,说明问题不在于堆内存,需排查堆外内存情况。通过NativeMemoryTracking发现,新集群JobManager的线程数相对旧集群有较大上涨,Thread stack内存占用较高
(4)通过Jstack发现,数量最高的一组线程池,线程数量与机器硬件cpu 核数成正比,而新集群的cpu 核数是旧集群的3倍,线程数是旧集群的3倍,基本确定了迁移后物理内存和虚拟内存上涨的原因。同时结合监控,新集群JobManager的线程数量和物理内存使用不会持续上涨,而是维持在1.5G左右。因此,对于新集群的实时任务JobManager,设置2G的整体内存是可以正常运行的,不过仍然建议增大jobmanager.memory.jvm-overhead.fraction,降低物理内存超用的概率。对于少部分物理内存超用的任务,需要增大jobmanager.memory.jvm-overhead.fraction,给堆外内存区域预留更多的内存空间。
最终调整
1、修改yarn nodemanger端的yarn-site.xml,将yarn.nodemanager.vmem-pmem-ratio修改为4(默认为2.1)
2、平台实时任务参数进行全局调整,jobmanager.memory.jvm-overhead.fraction由0.2调整为0.3
经过调整后,迁移至新集群后的任务,没有再频繁出现JobManager内存超用导致重试,提升了平台实时任务稳定性。















 2670
2670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









