









翻译至: Character encodings: Essential concepts
本文将介绍字符与字符编码的一些基本概念。
Unicode字符集
Unicode是一个通用且标准的字符集,包括了大多数生活所需字符。可以理解为一本很厚的字典,记录着世界上所有字符对应的一个数字。
网络或者电脑上的文本均由字符组成,它们可以是字母表,标点符或者其他符号。过去,不同组织集成了不同的字符集并为它们创建了编码方案——可能覆盖西方的拉丁语,也可能覆盖远东的日语或者其他国家语言。
各种各样的编码方式成了系统开发者的噩梦,即便你熟练掌握各种编码方式,系统或单个页面却不支持集成的编码方案。在这样的历史背景下,一个支持多语言的编码方案就这样“顺民心,应天命”地出现了,一切都是那么的刚刚好。
Unicode联盟 提供了大型单一字符集,包括世界上书写系统所需的所有字符,包括古代文字(如楔形文字、哥特文字和埃及象形文字)。它现在是 Web 和 OS 架构的基础,并受到所有主流Web浏览器和应用程序的支持。
接下来看看 Unicode脚本 支持的字符集,如下图。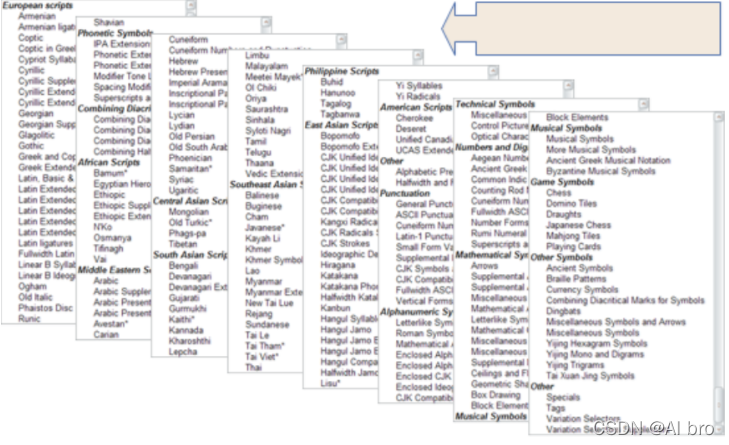
我们把 Unicode 前2个字节代表的65536个字符称为 基本多语言平面(BMP)。BMP(Basic Multilingual Plane) 包含了更常用的字符。
Unicode 字符集大概包含大约一百万的字符(amazing),而BMP 后面的那些字符也被成为 补充字符(supplementary characters)。

想了解关于 Unicode 更多的信息,可传送至 Unicode Home Page 或看这个教程 An Introduction to Writing Systems & Unicode。
字符集,编码字符集与字符编码
清楚地区分字符集和字符编码的概念很重要。
字符集(Character sets)是由特定目的组成的字符集——字面理解,就是一堆字符组成的集合。
编码字符集(coded character sets)是指给每个字符都分配唯一编号。编码字符集中的字符编号被称为代码点(code points)。代码点的值表示字符在编码字符集中的位置,例如,Unicode编码字符集中字母 a 的代码点是十进制的 255 或者十六进制的 0xE1
字符编码(character encodings)代表编码字符集的代码点映射至字节的过程(以便计算机操作)。下图显示了 Tifinagh编码字符集 如何使用 UTF-8 编码,将代码点映射到字节编码。箭头显示它们如何映射到字节序列,其中每个字节由两位十六进制数表示。
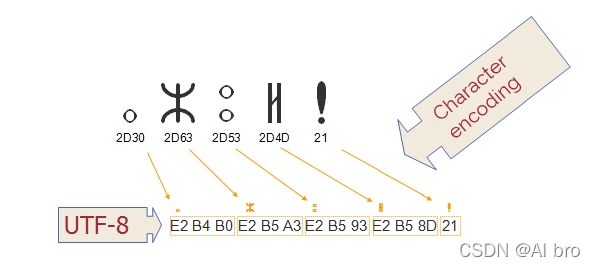
Tips: 不用担心,UTF-8 用一个字节编码如上感叹号是有原因的,后面会提到。
One character set, multiple encodings. 对于同样的字符集,是可以有不同编码方案的。许多字符编码标准,如 ISO-8859 系列编码方案要求,代码点到编码的字节必须是一一映射。例如 ISO8859-1 编码位于数据集 65 位的字符 A,就是用二进制字节表示 65。
然而对于其他编码方案并没有那么简单。例如在 Unicode编码字符集 中,a 的代码点是十进制的255。但在 UTF-8字符编码 中,它用两个字节来表示。换句话说,编码字符集和该字符的编码值之间并不是简单的一一映射。
例如:Unicode编码字符集 中的 a 可以在一种字符编码中用两个字节表示,在另一种字符编码中用四个字节表示,如下图。
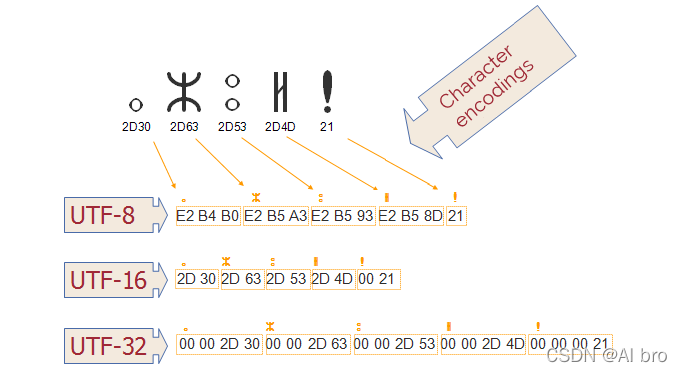
UTF-8 使用 1 个字节来表示 ASCII集 中的字符,2 个字节表示多个字母块中的字符,3 个字节表示 BMP 的其余部分。**补充字符(supplementary characters)**使用 4 个字节。
UTF-16 对 BMP 中的任何字符使用 2 个字节,对 补充字符 使用 4 个字节。
UTF-32 对所有字符使用 4 个字节。
在下图中,第一行表示字符在 Unicode 编码字符集 中代码点的值。其他行表示特定字符编码获得的字节值。
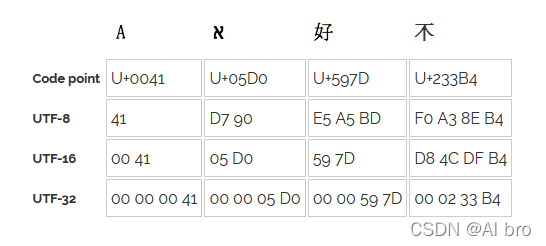
Unicode 编码总结
Unicode 没有规定字符对应的二进制码如何存储。以汉字 汉 为例,它的 Unicode 代码点是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了它至少需要 2 个字节来表示。可以想象,在 Unicode 字典中往后的字符可能就需要 3 个字节或者 4 个字节,甚至更多字节来表示了。
这就导致了一些问题,计算机怎么知道你这个 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如 Unicode 中最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0。这样确实可以解决编码问题,但是却造成了空间的极大浪费,如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
于是,为了较好的解决 Unicode 的编码问题, UTF-8 和 UTF-16 两种当前比较流行的编码方式诞生了。当然还有一个 UTF-32 的编码方式,也就是上述那种定长编码,字符统一使用 4 个字节,虽然看似方便,但是却不如另外两种编码方式使用广泛。
Unicode 编码总结,摘要于 彻底弄懂 Unicode 编码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









