






一、循环队列
我们可以把每一则消息带有的信息放到结构体里面。这样,每个结构体就是队列的一个成员。接收消息的线程把消息包装成一个结构体然后在队列(数组)的尾部加上,处理消息的线程取出队列的头部来解析处理,每次解析处理完一则消息,就把消息从队列的头部移除。
所以,我们要定义一个结构体数组,结构体里面还能包含结构体等,只要项目需要,都可以拓展。
程序模板比较简单,关键是知道怎么运用到项目中。
其中需要注意的点是循环队列如何判断空还是满。假设循环队列长度为5,当头指针和尾指针指向同一个地方,我们设为空。当有元素入队,尾指针指向下一个元素,当有元素出队,头指针指向下一个元素。当指向的元素为5时,下一个元素为0。
这样,得出的结论是,当队列为满时,头指针和尾指针是相等的,这和队列为空的时候是一样的。不信,画画图看看。
那怎么处理呢?
为了区别空队列和满队列,数组多加一个元素,这个元素是不确定的,是可以移动的,它将保证当队列为满时,还空留了一个位置。说起来比较抽象,看以下代码:

所以,通过在循环数组中加多了一个元素,就能够区分队列是空的还是满的。
大致的模板如下:
二、字符串的实质就是指针
字符串是C语言中最基础的概念,也是最常被用到的。在嵌入式开发中,我们经常要将一些字符串通过串口显示到串口助手或调试终端上,作为信息提示,以便让我们了解程序的运行情况;或者是将一些常量的值转为字符串,来显示到液晶等显示设备上。
那么C语言中的字符串到底是什么?其实字符串本身就是一个指针,它的值(即指针所指向的地址)就是字符串首字符的地址。
为了解释这个问题,我经常会举这样一个例子:如何将一个数值转化为相应的16进制字符串。比如,把100转为”0X64”。
我们可以写这样一个函数:
没有问题,它的功能是正确的。在实现上,因为数值0~9和A~F在ASCII码值上并不连续(分别为0X30~0X39和0X41~0X46),所以程序中以9为分界,进行了分情况处理。
但聪明一些的编程者,可能用这样的方法来实现:
对,这是使用了查表的思想。虽然0~9和A~F,在ASCII码值上不连续,但是我们可以把它们放到一个数组里,创造一种连续。然后用数值作为下标,直接获取对应的字符。
也许会有人觉得Hex_Char_Table定义起来太麻烦,要一个个去输入字符。其实可以这样作:
我们将字符数组换成了字符串常量。其实它们在内存中的表达是几乎一样的,其实质都是内存中的字节序列。如图2.1所示。
图2.1 字符数组与字符串都是内存中的字节序列
不同点在于,字符数组在定义的时候要明确指定数组的大小,即它可以容纳多少个字符(字节)。而字符串的长度则以第一个等于0的字节为准。所以,字符串的字节序列中,一定有某一个字节的值为0,它就是字符串的结束符。我们平时使用的strlen这个函数,计算字符串长度的原理,其实就是在检测这个0。所以,如果我们拿一个没有0的字符数组(字节序列)传给strlen,那么最终的结果很可能是错误的,甚至因为数组越界访问,而导致程序的崩溃。
上面,振南说“字符串本身就是指针”,那么见证这句话真正意义的时刻来了,我们将上面程序继续简化:
Hex_Char_Table这个指针变量其实是多余的,“字符串本身就是指针”,所以它后面可以直接用[]配合下标来取出其中的字符。凡是实质上为指针类型(即表达的是地址意义)的变量或常量,都可以直接用[]或*来访问它所指向的数据序列中的数据元素。
三、函数指针几个应用场景
回调函数
回调函数是指在某个事件发生时被调用的函数。通常,回调函数是在某个库函数或框架函数中注册的,当某个条件满足时,库函数或框架函数会调用回调函数来执行相应的操作。以下是一个示例:
在上面的代码中,我们定义了一个 handle_event 函数,它接受两个参数:一个事件类型和一个函数指针。如果函数指针不为空,则会调用指定的函数。
在 main 函数中,我们分别调用 handle_event 函数来触发两个事件,其中第一个事件注册了一个回调函数 callback_function,第二个事件没有注册回调函数。
函数参数化
函数参数化是指通过函数指针将函数的某些行为参数化。这样,我们可以在调用函数时动态地指定函数的行为。以下是一个示例:
在上面的代码中,我们定义了一个 process_array 函数,它接受三个参数:一个整型数组、数组大小和一个函数指针。函数指针指向一个函数,该函数接受一个整型参数并返回一个整型结果。
在 process_array 函数中,我们将数组中的每个元素传递给指定的函数,然后将函数的返回值存储回原数组中。
在 main 函数中,我们定义了一个 increment 函数,它将传入的整数加 1。然后,我们调用 process_array 函数来处理整型数组,并打印出结果。
排序算法
排序算法是函数指针的另一个常见应用场景。通过传递不同的比较函数,我们可以在不同的排序算法中重用相同的代码。以下是一个示例:
在上面的代码中,我们定义了一个 sort 函数,它接受三个参数:一个整型数组、数组大小和一个比较函数指针。
比较函数指针指向一个函数,该函数接受两个指向常量 void 类型的指针,并返回一个整型结果。
在 sort 函数中,我们使用标准库函数 qsort 来对整型数组进行排序,其中比较函数指针由调用者传递。
在 main 函数中,我们定义了两个比较函数 compare_int 和 compare_reverse_int,分别用于升序和降序排序。然后,我们调用 sort 函数来对整型数组进行排序,并打印出结果。
函数指针数组
函数指针数组是指一个数组,其中的每个元素都是一个函数指针。这种数组可以用于实现一个分派表,根据输入参数的不同,动态地调用不同的函数。以下是一个示例:
在上面的代码中,我们定义了四个函数 add、subtract、multiply 和 divide,分别对两个整数进行加、减、乘和除操作。
然后,我们定义了一个函数指针类型 operation_func_t,它指向一个接受两个整型参数并没有返回值的函数。
接着,我们定义了一个函数指针数组 operations,其中的每个元素都是一个 operation_func_t 类型的函数指针,分别指向 add、subtract、multiply 和 divide 函数。
在 main 函数中,我们使用 for 循环遍历 operations 数组,并依次调用每个函数指针所指向的函数。在每次调用函数之前,我们可以根据需要设置 a 和 b 的值。这样,我们就可以动态地选择要执行的操作。
函数指针与回溯法
回溯法是一种求解一些组合优化问题的算法,它通常使用递归来实现。函数指针可以用于实现回溯法算法的一些关键部分。
以下是一个使用回溯法来计算排列的示例:
在上面的代码中,我们定义了一个函数 permute,用于计算给定数组的排列。
在 permute 函数中,我们使用递归来生成所有可能的排列,并使用函数指针 callback 来指定每当我们生成一个排列时应该调用的函数。
在本例中,我们将 print_array 函数作为回调函数传递给了 permute 函数。这意味着每当 permute 函数生成一个排列时,它都会调用 print_array 函数来打印这个排列。
在 main 函数中,我们定义了一个包含三个整数的数组 nums,并使用 permute 函数来计算这个数组的所有排列。在每次生成一个排列时,permute 函数都会调用 print_array 函数来打印这个排列。
函数指针与多态
多态是面向对象编程中的一个重要概念,它允许我们在不知道对象类型的情况下调用相应的函数。虽然 C 语言不是面向对象编程语言,但我们仍然可以使用函数指针来实现多态。
以下是一个使用函数指针实现多态的示例:
在上面的代码中,我们定义了一个 shape 结构体,它有一个函数指针 draw,用于绘制该形状。
我们还定义了两个形状:circle 和 rectangle,它们分别包含它们自己的属性和一个指向 shape 结构体的指针。每个形状都定义了自己的 draw 函数,用于绘制该形状。
在 main 函数中,我们定义了一个 shape_t 类型的数组,其中包含一个 circle 和一个 rectangle。我们使用一个循环来遍历这个数组,并使用每个形状的 draw 函数来绘制该形状。
注意,尽管 shapes 数组中的元素类型为 shape_t *,但我们仍然可以调用每个元素的 draw 函数,因为 circle 和 rectangle 都是从 shape_t 派生出来的,它们都包含一个 draw 函数指针。
这个例子演示了如何使用函数指针来实现多态。尽管 C 语言不支持面向对象编程,但我们可以使用结构体和函数指针来实现类似的概念。
总结
函数指针是一种强大的工具,可以用于实现许多不同的编程模式和算法。
在本文中,我们介绍了函数指针的基本概念和语法,并提供了一些高级应用场景的代码示例,包括回调函数、函数指针数组、函数指针作为参数、函数指针与递归、函数指针与多态等。
使用函数指针可以帮助我们编写更加灵活和通用的代码,并提高代码的可重用性和可扩展性。
二、Makefile通用模板
对于Windows下开发,很多IDE都集成了编译器,如Visual Studio,提供了“一键编译”,编码完成后只需一个操作即可完成编译、链接、生成目标文件。
Linux开发与Windows不同,Linux下一般用的的gcc/g++编译器,如果是开发ARM下的Linux程序,还需用到arm-linux-gcc/arm-linux-g++交叉编译器。
Linux下也可以实现“一键编译”功能,此时需要一个编译脚本“Makefile”,Makefile可以手动编写,也可以借助自动化构建工具(如scons、CMake)生成。手动编写Makefile是Linux和Windows程序员的区别之一,一般地一个通用的Makefile能够适合大部分Linux项目程序。
三个Makefile模板
编译可执行文件Makefile

【要点说明】
【1】程序版本
开发调试过程可能产生多个程序版本,可以在目标文件后(前)增加版本号标识。

【2】编译器选择
Linux下为gcc/g++;arm下为arm-linux-gcc;不同CPU厂商提供的定制交叉编译器名称可能不同,如Hisilicon“arm-hisiv300-linux-gcc”。
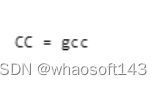
【3】宏定义
开发过程,特殊代码一般增加宏条件来选择是否编译,如调试打印输出代码。-D是标识,后面接着的是“宏”。

【4】编译选项
可以指定编译条件,如显示警告(-Wall),优化等级(-O)。
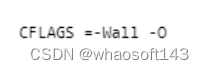
【5】源文件
指定源文件目的路径,利用“wildcard”获取路径下所有依赖源文件。

【6】头文件
包含依赖的头文件,包括源码文件和库文件的头文件。

【7】库文件名称
指定库文件名称,库文件有固定格式,静态库为libxxx.a;动态库为libxxx.so,指定库文件名称只需写“xxx”部分,

【8】库文件路径
指定依赖库文件的存放路径。注意如果引用的是动态库,动态库也许拷贝到“/lib”或者“/usr/lib”目录下,执行应用程序时,系统默认在该文件下索引动态库。
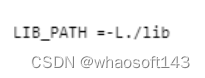
【9】目标文件
调用“patsubst”将源文件(.c)编译为目标文件(.o)。

【10】执行文件
执行文件名称

【11】编译

【12】链接
可创建一个“output”文件夹存放目标执行文件。链接完输出目标执行文件,可以删除编译产生的临时文件(.o)。

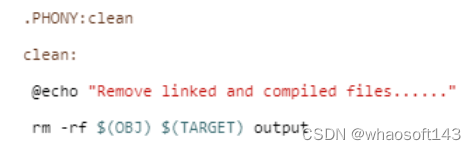
【13】清除编译信息
执行“make clean”清除编译产生的临时文件。
编译静态库Makefile
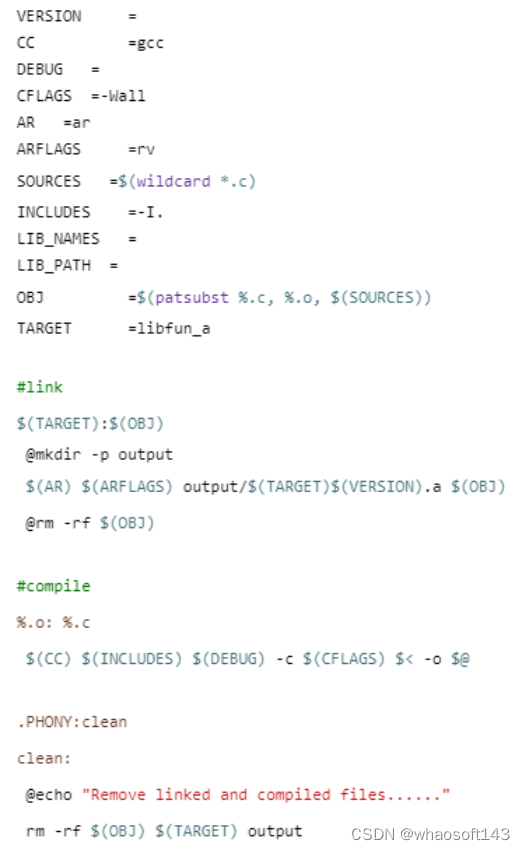
【要点说明】
基本格式与“编译可执行Makefile”一致,不同点包括以下。
【1】使用到“ar”命令将目标文件(.o)链接成静态库文件(.a)。静态库文件固定命名格式为:libxxx.a。
编译动态库Makefile
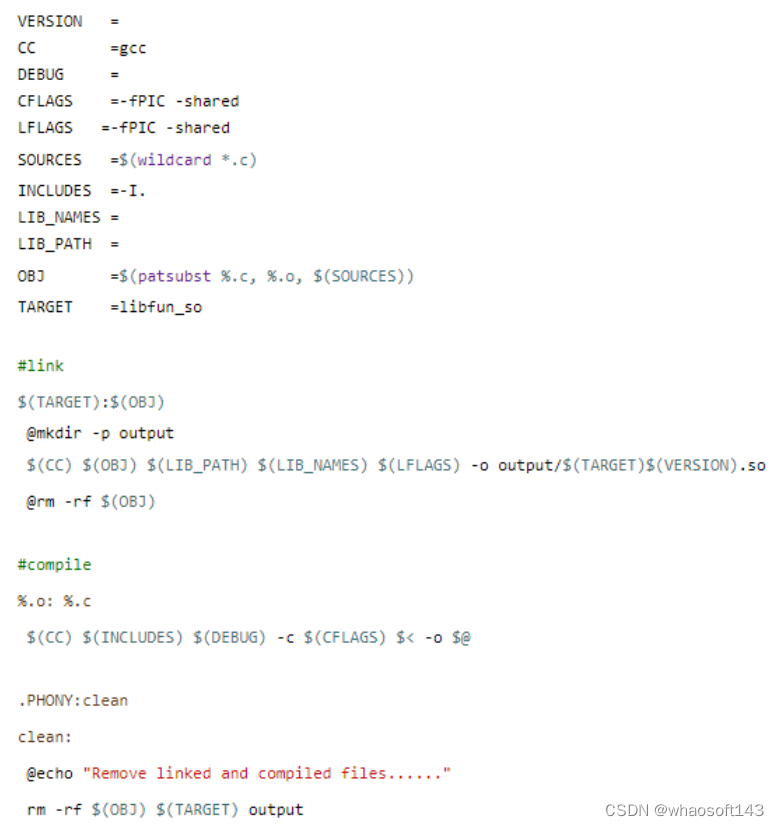
【要点说明】
基本格式与“编译可执行Makefile”一致,不同点包括以下。
【1】编译选项和链接选项增加“-fPIC -shared ”选项。动态库文件固定命名格式为libxxx.so。
Demo
编译应用程序
编写测试例程,文件存放目录结构如下,头文件存放在“include”目录,库文件存放在“lib”目录,源文件存放在“source”目录,Makefile在当前目录下。
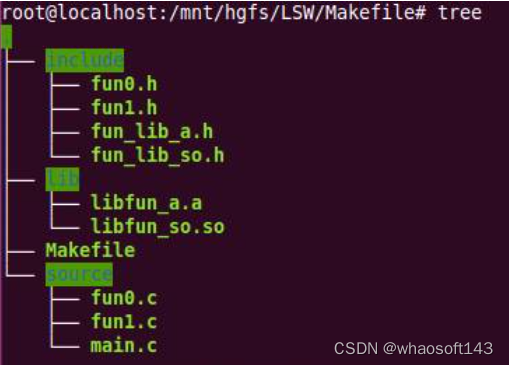
源码1:

源码2:

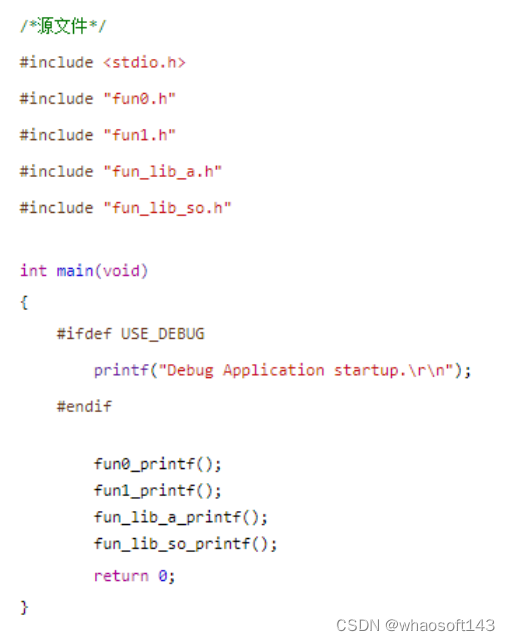
主函数源码:
库文件,“./lib”目录下存放两个库文件,一个静态库libfun_a.a,一个动态库libfun_so.so。
Makefile文件即为“2.1节”的Makefile模板。
测试运行:
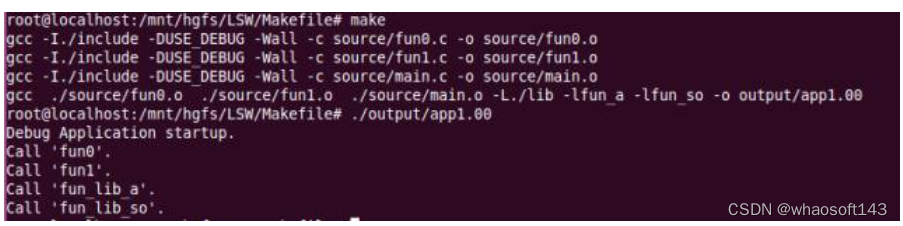
【如果执行文件提示无“libfun_so.so”,则需拷贝“libfun_so.so”到根目录下的“/lib”或者“/usr/lib”目录下,因为系统执行程序,默认从该路径引脚动态库】
生成静态库
编写测试例程,生产的库文件即为“3.1节”调用的库文件(libfun_a.a)。文件存放目录结构如下:
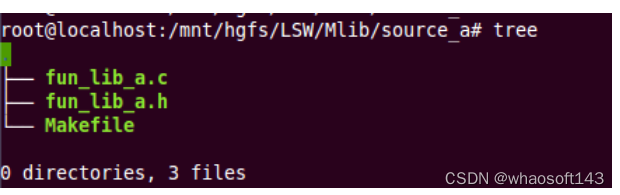
源文件:

Makefile文件即为“2.2节”的Makefile模板。
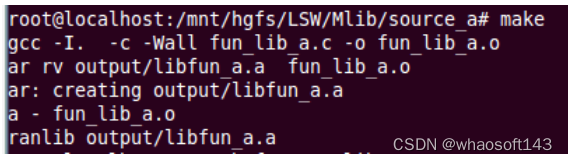
编译生成静态库:
生成动态库
编写测试例程,生产的库文件即为“3.1节”调用的库文件(libfun_so.so)。文件存放目录结构如下:
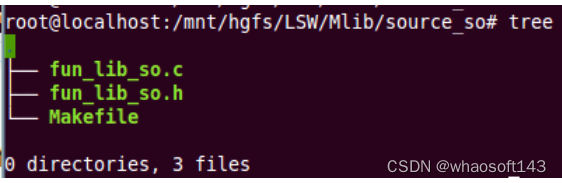
源文件:

编译生成动态库:
















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









