






python实现BeautifulSoup框架爬取CSDN用户信息
保存形式为txt格式
# coding:utf-8
from bs4 import BeautifulSoup
import requests
import sys
import bs4
def getFrist(account):
print("#加载中...")
baseUrl = 'https://me.csdn.net/' + account
# 伪装成浏览器访问
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
r = requests.get(baseUrl)
demo = r.text # 服务器返回响应
soup = BeautifulSoup(demo, "html.parser")
"""
demo 表示被解析的html格式的内容
html.parser表示解析用的解析器
"""
with open("F:\\spider\\test\\" + account + ".txt", "w") as file:
# 昵称
# print("昵称: "),
persont = soup.find_all(class_='person_t')
if len(persont) != 0:
for child in soup.find_all(class_='person_t'):
# print(child.string.strip())
file.write("昵称: " + child.string.strip().encode('utf8') + '\n')
else:
file.write("昵称: " + account.encode('utf8') + '\n')
# 签名
# print("签名: "),
personintrot = soup.find_all(class_='person_intro_t')
if len(personintrot) != 0:
for qm in soup.find(class_='person_intro_t'):
qming = qm.string.strip()
file.write("签名: " + qming.encode('utf8') + '\n')
difangList = []
jieshao = soup.find_all('dd', class_='person_b')
if len(jieshao) != 0:
for df in jieshao:
dfang = df.findAll('span')
for dif in dfang:
fd = dif.string.strip()
difangList.append(fd)
if len(difangList) == 2:
file.write(difangList[0].encode('utf8'))
file.write(" "+difangList[1].encode('utf8') + '\n')
else:
file.write(difangList[0].encode('utf8') + '\n')
# 等级,访问,原创,转发,排名,评论,获赞
zong = soup.find_all(class_='mod_my_t clearfix')
lianjie = ''
if len(zong)!=0:
for fen in zong:
fen_span = fen.findAll('span')
fen_strong = fen.findAll('strong')
dengji = fen.use
lianjie = fen.a['href']
fen_dengji = fen_strong[0].text
fen_fangwen = fen_strong[1].text
fen_yuanchuang = fen_strong[2].text
fen_zhuanfa = fen_strong[3].text
fen_paiming = fen_strong[4].text
fen_pinglun = fen_strong[5].text
fen_huozan = fen_strong[6].text
# print(fen_dengji + " " + fen_fangwen + " " + fen_yuanchuang + " " + fen_zhuanfa + " "
# + fen_paiming + " " + fen_pinglun + " " + fen_huozan)
str1 = (fen_dengji + " " + fen_fangwen + " " + fen_yuanchuang + " " + fen_zhuanfa + " "
+ fen_paiming + " " + fen_pinglun + " " + fen_huozan)
fen_dengjishu = dengji['xlink:href']
fen_fangwenshu = fen_span[1].text
fen_yuanchuangshu = fen_span[2].text
fen_zhuanfashu = fen_span[3].text
fen_paimingshu = fen_span[4].text
fen_pinglunshu = fen_span[5].text
fen_huozanshu = fen_span[6].text
# print(fen_dengjishu[
# 11:18] + " " + fen_fangwenshu + " " + fen_yuanchuangshu + " " + fen_zhuanfashu + " " + fen_paimingshu
# + " " + fen_pinglunshu + " " + fen_huozanshu)
str2 = (fen_dengjishu[
11:18] + " " + fen_fangwenshu + " " + fen_yuanchuangshu + " " + fen_zhuanfashu + " " + fen_paimingshu
+ " " + fen_pinglunshu + " " + fen_huozanshu)
file.write(str1.encode('utf8') + '\n')
file.write(str2.encode('utf8') + '\n')
file.close()
# 获取原创进入链接
if len(lianjie) != 0:
yuanchuanglianjie = lianjie
getSecond(account, yuanchuanglianjie)
else:
print(account.encode('utf8') + "个人主页404...")
newUrl = "https://blog.csdn.net/"+account
getSecond(account, newUrl)
def getSecond(account, lianjie):
nextUrl = lianjie
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
r = requests.get(nextUrl)
demo = r.text # 服务器返回响应
soup = BeautifulSoup(demo, "html.parser")
zongfenlei = soup.find_all('div', id='asideCategory')
# print("-----------个人分类-----------")
with open("F:\\spider\\test\\" + account + ".txt", "a") as file:
a = soup.find_all('div', class_="aside-content clearfix")
if len(a) != 0:
file.write("个人简介: ")
for b in a:
file.write(b.text.strip().replace("\n", "").encode('utf8')+'\n')
file.write("-----------个人分类-----------" + '\n')
if len(zongfenlei) != 0:
fenleimingList = []
fenleishuList = []
for bb in zongfenlei:
fenleiming = bb.findAll('span', class_='title oneline')
fenleishu = bb.findAll('span', class_='count float-right')
for cc in fenleiming:
if (isinstance(cc, bs4.element.Tag)):
fenleimingList.append(cc.string)
for dd in fenleishu:
if (isinstance(dd, bs4.element.Tag)):
fenleishuList.append(dd.string)
for n in range(len(fenleimingList)):
# print(fenleimingList[n]),
# print(": "),
# print(fenleishuList[n])
file.write(fenleimingList[n].encode('utf8') + ': ' + fenleishuList[n].encode('utf8') + '\n')
# 归档
# print("------------归档-------------")
file.write("------------归档-------------" + '\n')
riqiList = []
pianList = []
guidangzong = soup.find_all('div', id='asideArchive')
if len(guidangzong) != 0:
for aa in guidangzong:
riqizong = aa.findAll('a')
pianshu = aa.findAll('span', class_='count float-right')
for bb in riqizong:
riqi = bb.contents[0].strip()
riqiList.append(riqi)
for cc in pianshu:
pian = cc.string
pianList.append(pian)
for n in range(len(pianList)):
# print(riqiList[n]),
# print(": "),
# print(pianList[n])
file.write(riqiList[n].encode('utf8') + ': ' + pianList[n].encode('utf8') + '\n')
# 当前的博客列表页号
page_num = 1
# 不是最后列表的一页
notLast = []
file.write('-----------------------------the page---------------------------------' + '\n')
while not notLast:
# 首页
firstUrl = 'http://blog.csdn.net/' + account
myUrl = firstUrl + '/article/list/' + str(page_num)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
r = requests.get(myUrl)
demo = r.text # 服务器返回响应
soup = BeautifulSoup(demo, "html.parser")
# print('-----------------------------the %d page---------------------------------' % (page_num,))
biaoti = soup.find_all('h4')
if len(biaoti) != 0:
timuList = []
shijianList = []
yueduList = []
pinglunList = []
zongshuList = []
for timu in biaoti:
bowentimu = timu.find('a')
if(isinstance(bowentimu, bs4.element.Tag)):
timuList.append(bowentimu.text.strip().replace("\n", ""))
zhengwenshuju = soup.find_all('div', class_='info-box d-flex align-content-center')
for tag in zhengwenshuju:
shijian = tag.find('span', class_='date').string
shijianList.append(shijian)
shuju = tag.findAll('span', class_='read-num')
yuedu = shuju[0].contents[0]
yueduList.append(yuedu)
pinglun = shuju[1].contents[0]
pinglunList.append(pinglun)
zongshu = soup.findAll('span', class_='num')
for zon in zongshu:
zonggong = zon.text
zongshuList.append(zonggong)
for n in range(len(zhengwenshuju)):
if (n < 1):
# print("博文: "),
# print('%s' % timuList[n])
# print("发表时间: "),
# print(shijianList[n] + " " + yueduList[n] + " " + pinglunList[n])
file.write("博文: " + timuList[n].encode('utf8') + " " + "发表时间: " + shijianList[n].encode(
'utf8') + " " + yueduList[n].encode('utf8') + " " + pinglunList[n].encode('utf8') + '\n')
else:
# print("博文: "),
# print('%s' % timuList[n])
# print("发表时间: "),
# print(shijianList[n] + " " + yueduList[n] + ":" + zongshuList[2 * (n - 1)] + " " + pinglunList[
# n] + ":" + zongshuList[2 * n - 1])
file.write(
"博文: " + timuList[n].encode('utf8') + " " + "发表时间: " + shijianList[n].encode('utf8') + " "
+ yueduList[n].encode('utf8') + ":" + zongshuList[2 * (n - 1)].encode('utf8') + " "
+ pinglunList[n].encode('utf8') + ":" + zongshuList[2 * n - 1].encode('utf8') + '\n')
else:
break
page_num = page_num + 1
if (len(biaoti) < 21):
break
file.close()
print("#加载完成...")
def getPeopleLink(account):
baseUrl = 'https://me.csdn.net/' + account
# 伪装成浏览器访问
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
r = requests.get(baseUrl)
demo = r.text # 服务器返回响应
soup = BeautifulSoup(demo, "html.parser")
renList = []
queue = []
ren = soup.find_all('ul', class_='tab_page')
if len(ren) != 0:
for ee in ren:
ff = ee.findAll('a', class_='fans_title')
for r in ff:
renList.append(r.string.strip())
return renList
return ''
# # 得到个人信息
# getFrist(account)
# # 得到关注用户信息
# for n in range(len(renList)):
# getFrist(renList[n])
# for n in range(len(renList)):
# getPeopleLink(renList[n])
if __name__ == '__main__':
account = str(raw_input('print csdn_id:'))
# 得到关注用户信息
queue = []
getFrist(account)
if len(getPeopleLink(account)) != 0:
for i in getPeopleLink(account):
queue.append(i)
for j in queue:
getFrist(j)
for x in getPeopleLink(j):
queue.append(x)
else:
print(account + "没有关注用户!")
将txt内容提取出部分内容,存入mysql实现
#! usr/bin/python
# -*- coding:utf-8 -*-
import os
import csv
import pymysql
def trav(path):
path1 = 'r'+path
fileList = []
filepath = []
filenames = os.listdir(path)
for filename in filenames:
fileList.append(filename)
for n in range(len(fileList)):
filepath.append(path+"//"+fileList[n])
for n in range(len(filepath)):
csvtext(filepath[n])
# print(filepath[n])
# nobasic(filepath[n])
# 找出没有基本数据的用户
# def nobasic(filepath):
# list = []
# with open(filepath, 'r') as f:
# for line in f.readlines():
# list.append(line)
# f.close()
# # 用户名
# username = list[0].split(' ')[1].strip().decode('utf8').encode('gbk')
# count = 0
# for n in range(len(list)):
# line = list[n]
# str = 'level-'
# if(str in line):
# break
# out = open('C://Users//67033//Desktop//nobasic.csv', 'ab+')
# csv_write = csv.writer(out)
# csv_write.writerow(username)
# out.close()
# count = count +1
# print(count)
def csvtext(filepath):
list = []
with open(filepath, 'r') as f:
for line in f.readlines():
list.append(line)
f.close()
# 用户名
username = list[0].split(' ')[1].strip()
uname = []
uname.append(username)
# 需要判断是否为level行,如果找不到则出入到nobasic文件夹
for n in range(len(list)):
count = 0
line = list[n]
str = 'level-'
if(str in line):
trueLine = line
csvexec(username, trueLine)
else:
count = count+1
if(count>=5):
# out = open('C://Users//67033//Desktop//nobasic.csv', 'ab+')
# csv_write = csv.writer(out)
# csv_write.writerow(username)
# out.close()
# print('No Basic!')
break
def csvexec(username, trueLine):
# 基本数据
jbshuju = []
for i in range(7):
jbshuju.append(trueLine.split(' ')[i].strip())
a = jbshuju[0]
level = a[6:]
jbshuju.insert(1, level)
jbshuju.remove(jbshuju[0])
userList = []
userList.append(username)
for i in range(7):
userList.append(jbshuju[i])
# out = open('C://Users//67033//Desktop//user.csv', 'ab+')
# csv_write = csv.writer(out)
# csv_write.writerow(userList)
# out.close()
con = pymysql.connect(host='localhost', port=3306, user='root', password='zhengxin', db='csdn', charset='utf8')
cur = con.cursor()
sql = "insert into csdn_spider_use(user_name, user_level, user_visitor, user_creation, user_trans, user_rank," \
"user_commit, user_like) values (\"%s\", \"%s\", \"%s\", \"%s\", \"%s\", \"%s\", \"%s\", \"%s\")"
sql1 = sql % (
userList[0], userList[1], userList[2], userList[3], userList[4], userList[5], userList[6], userList[7])
cur.execute(sql1)
con.commit()
cur.close()
con.close()
print('Completion!')
if __name__ == '__main__':
path = 'F://spider//test'
trav(path)
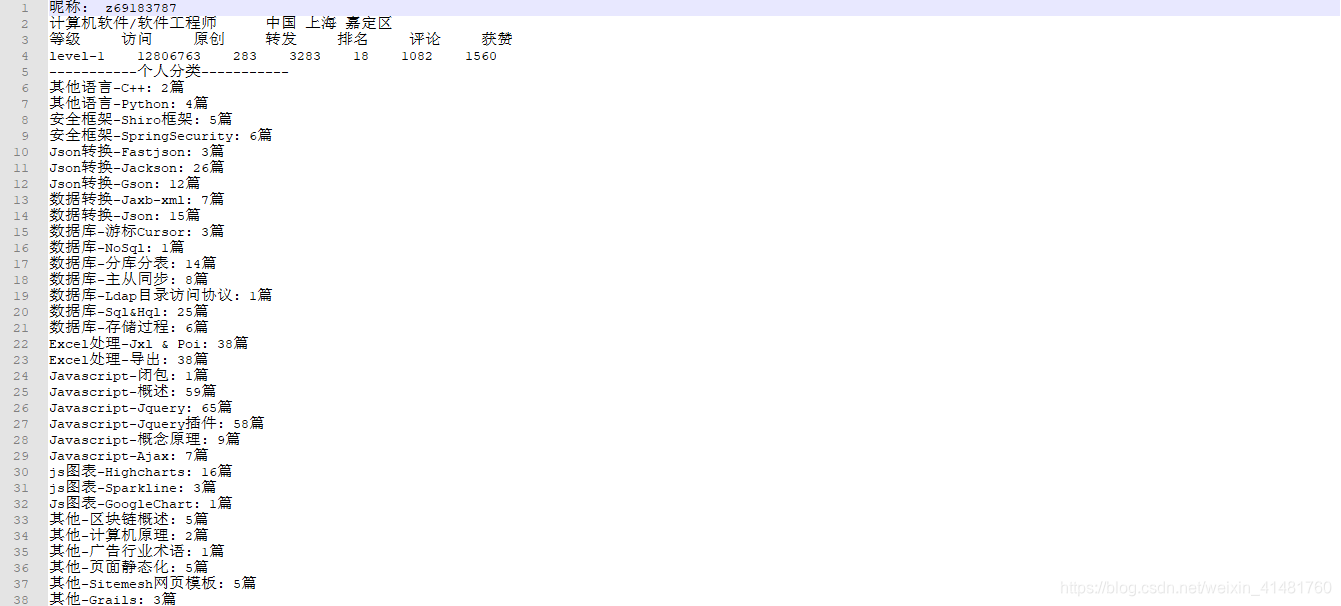
结果

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









