






框架图

1870309220-5aceb7d78c4f6_articlex.png
- 安装
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple2.创建
创建项目:scrapy startproject xxx
进入项目:cd xxx #进入spiders文件夹下
创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
生成文件:scrapy crawl xxx -o xxx.json (生成某种类型的文件)
运行爬虫:scrapy crawl XXX
列出所有爬虫:scrapy list
获得配置信息:scrapy settings [options]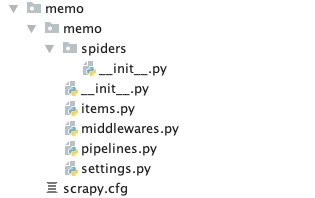
image.png
scrapy.cfg: 项目的配置文件
memo/: 该项目的python模块。在此放入代码(核心)
memo/items.py: 项目中的item文件.(这是创建容器的地方,爬取的信息分别放到不同容器里)
memo/pipelines.py: 项目中的pipelines文件.
memo/settings.py: 项目的设置文件.(我用到的设置一下基础参数,比如加个文件头,设置一个编码)
memo/spiders/: 放置spider代码的目录. (放爬虫的地方)
在setting文件中需要把item开启
ITEM_PIPELINES = {
'earthspider.pipelines.EarthspiderPipeline': 300,
}3.容器
#items.py
import scrapy
class DmozItem(scrapy.Item): #创建一个类,继承scrapy.item类,就是继承人家写好的容器
title = scrapy.Field() # 需要取哪些内容,就创建哪些容器
link = scrapy.Field()
desc = scrapy.Field()4.爬虫规则
import scrapy
from ..items import MemoItem
class Daily2Spider(scrapy.Spider):
name = 'daily2'
allowed_domains = ['iciba.com']
# start_urls = ['http://iciba.com/']
start_urls = [
'http://sentence.iciba.com/index.php?callback=jQuery190008406839854439085_1611202697057&c=dailysentence&m=getdetail&title=2021-01-21&_=1611202697065']
def parse(self, response):
# print(response.text)
text=str(response.text).encode('utf-8').decode('unicode-escape')
print(text)
item = MemoItem()
item["time"] = text.split('"title":"')[1].split('"')[0]
item["English"] = text.split('"content":"')[1].split(' "')[0]
item["Chinese"] = text.split('"note":"')[1].split('"')[0]
yield item5.运行结果
scrapy crawl daily
{'Chinese': '机遇不会自己找上门来,它只会在你开门时出现。',
'English': 'Opportunity does not knock, it presents itself when you beat down '
'the door.',
'time': '2021-01-21'}
2021-01-22 11:21:05 [scrapy.core.engine] INFO: Closing spider (finished)
2021-01-22 11:21:05 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 741,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 1458,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/404': 1,
'elapsed_time_seconds': 0.334966,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 1, 22, 3, 21, 5, 462881),
'item_scraped_count': 1,
'log_count/DEBUG': 3,
'log_count/INFO': 10,
'memusage/max': 55255040,
'memusage/startup': 55255040,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2021, 1, 22, 3, 21, 5, 127915)}
2021-01-22 11:21:05 [scrapy.core.engine] INFO: Spider closed (finished)6.保存结果
pipelines.py
import json
class MemoPipeline(object):
"""
保存item的数据
"""
def __init__(self):
self.filename = open('daily.json', 'w')
def process_item(self, item, spider):
text = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self, spider):
self.filename.close()setting.py
#数据库配置
mysql_host = '127.0.0.1'
mysql_user = 'root'
mysql_passwd = 'xxxx'
mysql_db = 'memo'
mysql_port = 3306
table_name = 'daily'














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











