









python作为兴趣爱好虽然很少用的工作中,但一些常用的如正则表达式学一学还是很有必要,以下主要为个人整理的学习笔记。
目录
1. re.findall()方法
import re
'''
遍历整个字符串,返回一个包含所有满足要求的数组
'''
s = 'hello python python python! python'
m = re.findall('python', s)
if m is None:
print('匹配失败')
else:
print('匹配结果的对象m:', m)
运行结果:

2. re.match()方法
与search的区别:尝试从字符串的起始位置开始匹配。
import re
'''
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
'''
s = 'hello python!'
m = re.match('.+(python).+', s)
if m is None:
print('匹配失败')
else:
print('匹配结果的对象m:', m)
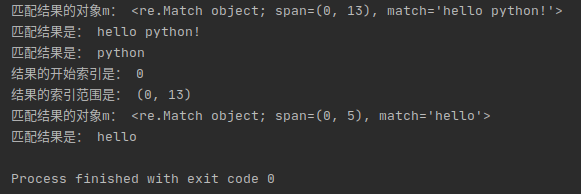
print('匹配结果是:', m.group())
print('匹配结果是:', m.group(1))
print('结果的开始索引是:', m.start())
print('结果的索引范围是:', m.span())
# 不区分大小写的匹配
m2 = re.match('HELLO', s, re.I)
if m2 is None:
print('匹配失败2')
else:
print('匹配结果的对象m:', m2)
print('匹配结果是:', m2.group())
运行结果:
3. re.search()方法
与match的区别:扫描整个字符串,返回第一个成功的匹配。
import re
'''
re.search 扫描整个字符串并返回第一个成功的匹配。
'''
s = 'hello python python!'
m = re.search('python', s)
if m is None:
print('匹配失败')
else:
print('匹配结果的对象m:', m)
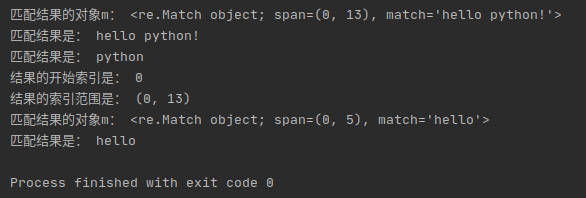
print('匹配结果是:', m.group())
print('结果的开始索引是:', m.start())
print('结果的索引范围是:', m.span())
# 不区分大小写的匹配
# m2 = re.search('HELLO', s, re.I)
# if m2 is None:
# print('匹配失败2')
# else:
# print('匹配结果的对象m:', m2)
# print('匹配结果是:', m2.group())运行结果:
4. re.sub()方法
import re
'''
sub用于替换字符串中的匹配项,语法一般是:
re.sub(r’正则匹配规则’,’替换的字符串’,需要检索的字符串)
'''
QQ = 'QQ:10000 # 卧槽,五位数的QQ号'
Q = re.sub(r'#.*$', 'WTF NO JOKE', QQ)
print(Q)
运行结果: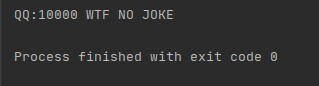
5. 贪婪模式与非贪婪模式
import re
print('-----------------贪婪模式----------------')
v = re.match(r'(.+)(\d+-\d+-\d+)', 'This is my tel:133-1234-1234')
print(v.group(1))
print(v.group(2))
print('-----------------非贪婪模式----------------')
v = re.match(r'(.+?)(\d+-\d+-\d+)', 'This is my tel:133-1234-1234')
print(v.group(1))
print(v.group(2))
print('---------实例2----------')
print('-----------------贪婪模式----------------')
v = re.match(r'abc(\d+)', 'abc123')
print(v.group(1))
print('-----------------非贪婪模式----------------')
v = re.match(r'abc(\d+?)', 'abc123')
print(v.group(1))运行结果:

6. 常用元字符
'''
. :匹配任意字符,换行符 \n 除外
+ :匹配前一个字符1次或多次
* :匹配前一个字符0次或无限次
? :匹配前一个字符0次或1次
{n} :匹配n次
{n,} :至少匹配n次
{n,m} :匹配至少n次,至多m次
.* :贪心算法,尽可能的匹配多的字符
.*? :非贪心算法
() :括号内的数据作为结果返回
\d :匹配一个数字字符。等价于 [0-9]。
\D :匹配一个非数字字符。等价于 [^0-9]。
\w :匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。
\W :匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。
x|y :匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。
[xyz] :字符集合。匹配
包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。
[^xyz] :负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。
[a-z]: :字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。
[^a-z] :负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。
'''















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









