






理论部分
给出样本数据
计算相应指标
可视化
理论部分
问题 考察两个变量 与 之间是否存在线性相关关系,其中 是一般 ( 可控) 变量, 是随机变量,其线性相关关系可表示如下 ( 可用散点图显示) :
其中 为截距, 为斜率 为随机误差,常假设 这里 是三个待估参数. 上式表明, 与 之间有线性关系,但受到随机误差的干扰.
数据 对 与 通过试验或观察可得 对数据(注 : 数据是成对的,不允 许错位). 在 与 之间存在线性关系的假设下,有如下统计模型:
各独立同分布其分布为
利用成对数据可获得 与 的估计,设估计分别为 与 则称 为 回归方程,其图形称为回归直线.
参数估计 用最小二乘法可得 与 的无偏估计
其中 此处 表示 下同
回归方程的显著性检验 回占方程的显著性检验就是要对如下一对假 设作出判断:
检验方法如下.
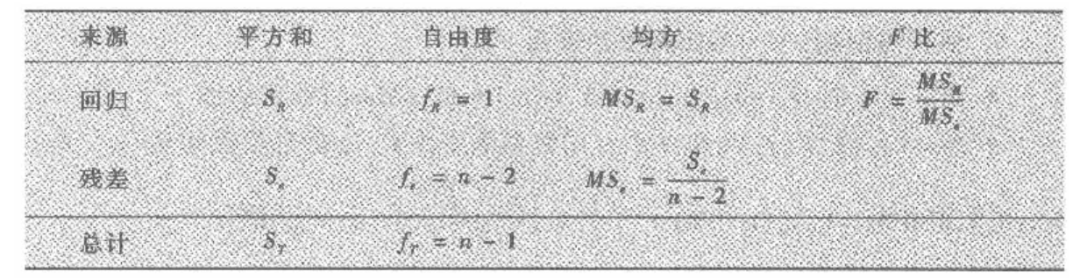
检验 如下的平方和分解式是非常重要的,它在许多统计领域得到应用 :
其中 是总平方和 其自由度 是回归平方和,其自由度 是残差平方和,其自由度 而 是在 的回归值(拟合值),它与实测值 通常是不相等的. 在原假设 成立的条件下,检验统计胃 ,拒绝 域为
上述检验过程一般用如下方差分析表列出 :
估计与预测
当 时 是 的点估计
当 时 的置信水平由 的置信区间是 其中
当 时 的 预测区间是 ,其中
注 是未知参数,而 是随机变量. 对 谈论的是置信区间,对 谈论的是预测区间,两者是不同的,显然,预测区间要比置信区间宽很多. 要提高预测区间(置信区间也一样) 的精度,即要使 或 较小,这要求 : (1) 增大样本量 增大 即要求 较为分散 使 靠近
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
%matplotlib inline给出样本数据
x = np.array([15.3, 10.8, 8.1, 19.5, 7.2, 5.3, 9.3, 11.1, 7.5, 12.2,
6.7, 5.2, 19.0, 15.1, 6.7, 8.6, 4.2, 10.3, 12.5, 16.1,
13.3, 4.9, 8.8, 9.5])
y = np.array([1.76, 1.34, 1.27, 1.47, 1.27, 1.49, 1.31, 1.09, 1.18,
1.22, 1.25, 1.19, 1.95, 1.28, 1.52, 1.5, 1.12, 1.37,
1.19, 1.05, 1.32, 1.03, 1.12, 1.70])计算相应指标
n = len(x)
Lxx = np.sum(x**2) - np.sum(x)**2/n
Lyy = np.sum(y**2) - np.sum(y)**2/n
Lxy = np.sum(x*y) - np.sum(x)*np.sum(y)/n
mean_x = np.mean(x)
mean_y = np.mean(y)# 斜率和截距的最小二乘估计和MLE是一样的
b = Lxy/Lxx
a = mean_y - b*mean_x
fit = lambda xx: a + b*xx
alpha = 0.05
# 残差
residuals = y - fit(x)
# MSE
var_res = np.sum(residuals**2)/(n-2)
sd_res = np.sqrt(var_res)# 残差自由度
df = n-2
# t值
tval = stats.t.isf(alpha/2., df)
# 置信区间
se_fit = lambda x: sd_res * np.sqrt( 1./n + (x-mean_x)**2/Lxx)
# 预测区间
se_predict = lambda x: sd_res * np.sqrt(1+1./n + (x-mean_x)**2/Lxx)可视化
plt.figure()
plt.plot(x, fit(x),'k', label='Regression line')
plt.plot(x,y,'k.')
x.sort()
# 置信度
limit = (1-alpha)*100
# 置信区间范围
plt.plot(x, fit(x)+tval*se_fit(x), 'r--', lw=2, label='Confidence limit ({}%)'.format(limit))
plt.plot(x, fit(x)-tval*se_fit(x), 'r--', lw=2 )
# 预测区间范围
plt.plot(x, fit(x)+tval*se_predict(x), 'b*-', lw=2, label='Prediction limit ({}%)'.format(limit))
plt.plot(x, fit(x)-tval*se_predict(x), 'b*-', lw=2)
plt.xlabel('X values')
plt.ylabel('Y values')
plt.title('Linear regression and confidence limits')
plt.legend(loc=0)
plt.show()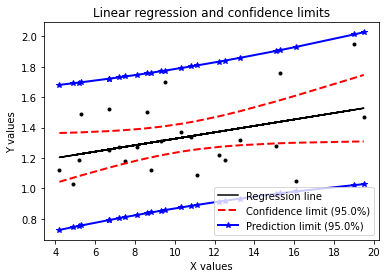















 6513
6513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









