







第一期 关联图:01 散点图 & 02 气泡图
2018年12月,大佬博主Selva Prabhakaran在自己运营的机器学习网站MachineLearning Plus上发布了博文:Python可视化50图
https://www.machinelearningplus.com/plots/top-50-matplotlib-visualizations-the-master-plots-python/
博文非常优秀,但是同时…
1 代码有一定难度,属于可视化进阶内容,但没有任何注解
2 没有任何数据探索
3 没有任何图形解释
4 内容过多,一个人难以从头看到尾,好不容易诞生的一篇干货文章,会逐渐沦为微信收藏夹中又一个被忘记的对象

菊安酱和菜菜不希望看到这篇优秀文章被浪费掉!
在接下来的8周之内,我们将会带领你一起遍历50图,每周直播+完整版更新,不怕没人带没动力~!
我们将会给你:
- 有逻辑的数据探索
- 完整的代码,模块和包的解读(ipy当然是会给你们的啦( ̄▽ ̄))
- 绘图参数的含义和调试
- 读图,根据数据解读出图像中有用的信息
- 完整的Python可视化流程
- 更改原始代码中出现的一些bug,直播也许会随机掉落的小题目
而你需要:
- 熟悉Python基础,包括Pandas和Numpy库
- 熟悉数据相关的基本概念——比如,什么是特征,什么是标签?
*我们可能会使用机器学习中的一些基本技巧来进行数据的探索
00 安装库,配置环境
在Python中进行可视化,我们需要的是这些库:
- matplotlib:python中自带的,也是最常用的可视化工具包,在Jupyter中甚至可以找到matplotlib的网站
- seaborn:python中可视化的新起之秀,致力于统计数据可视化
- brewer2mpl:brewer2mpl是一个专供python使用的,用于访问colorbrewer2色谱的工具,colorbrewer2是一个专业颜色顾问公司
matplotlib
通常来说,如果我们是使用anaconda安装的python,那matplotlib是自带的
如果你发现你的python环境中没有matplotlib,那你可以使用以下命令先安装pip,然后从pip中安装matplotlib:
#python -m pip install -U pip
#python -m pip install -U matplotlib
你可以通过在Jupyter中运行 print(matplotlib.__version__) 来查看你现有的matplotlib版本
import matplotlib as mlp
print(mlp.__version__)
建议都更新成和菜菜一样,最少也需要3.0.1以上
如果你的版本不足,你可以使用下面的代码来更新你的版本,注意conda和pip不要混装
#%%cmd
#conda update matplotlib
#或者
#pip install --upgrade matplotlib
seaborn
seaborn是需要自己安装的。如果不是anaconda自带,建议使用pip安装
#%%cmd
#pip install seaborn
import seaborn as sns
print(sns.__version__)
seaborn要求必须0.9.0以上,否则代码会报错,不足0.9.0的大家可以使用以下代码进行升级
#%%cmd
#pip install --upgrade seaborn
brewer2mpl
同样也需要自己安装,使用以下代码:
#%%cmd
#pip install brewer2mpl
不必过于在意版本,通常来说都是直接安装成最新版
菜菜所使用的版本:
import sys
print(sns.__version__)
print(mlp.__version__)
#Python版本
sys.version
0.9.0
3.0.3
‘3.7.1 (default, Oct 28 2018, 08:39:03) [MSC v.1912 64 bit (AMD64)]’
第一章 关联图 Correlation
关联图是查找两个事物之间关系的图像,它能够为我们展示出一个事物随着另一个事物的变化如何变化
典型的关联图有:折线图,散点图,相关矩阵……

我们什么时候会需要关联图呢?
- 数据报告 & 学术研究:
展示趋势:比如产品销量随着时间如何变化,智力水平随着教育程度如何变化等
展现状态:不同年龄的客户的成交率,不同生产成本对应的生产员工技能要求
- 数据探索 & 数据解读:
探索数据关系,帮助了解事实,推动研究
- 统计学 & 机器学习:
探索数据关系,指导数据预处理和模型选择
01/50 散点图
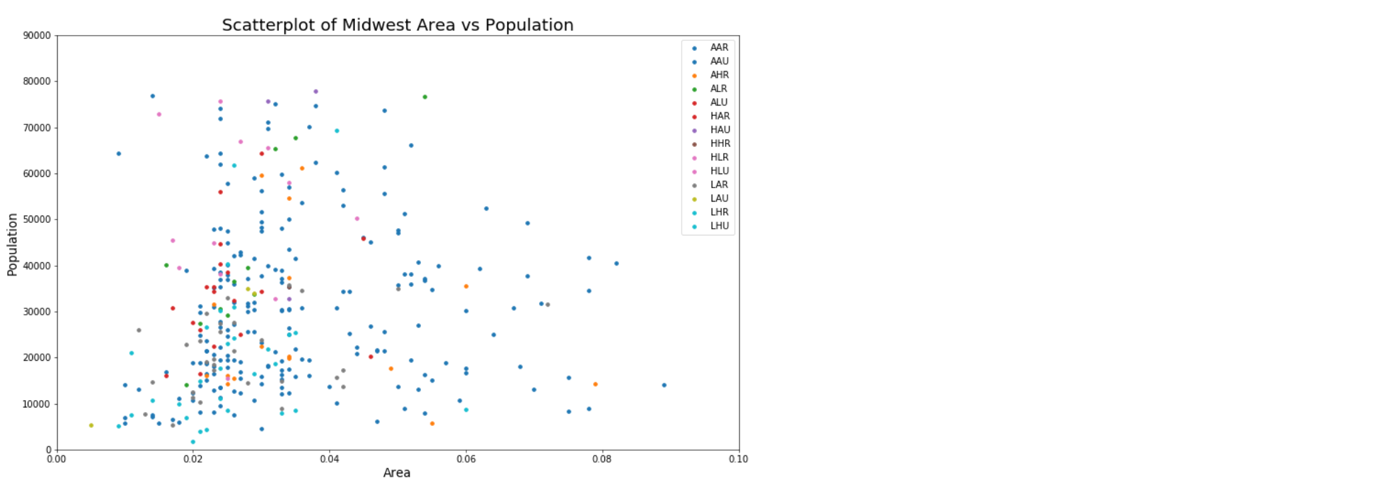 横坐标:面积大小
横坐标:面积大小
总坐标:总人口
图例:暂时看不出是什么总而言之看起来是类型,一种类型一个颜色
我们的目标是:绘制出这张图,并且利用数据解读图内的信息
1. 导入需要的绘图库
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#如果你在使用Jupyter Notebook,你会需要这样一句命令来让你的图像显示
2. 先来认识一下绘制散点图的函数
plt.scatter()
#绘制超简单的散点图:变量x1与x2的关系
#定义数据
x1 = np.random.randn(10) #取随机数
x2 = x1 + x1**2 - 10
#确定画布 - 当只有一个图的时候,不是必须存在
plt.figure(figsize=(8,4))
#绘图
plt.scatter(x1,x2 #横坐标,纵坐标
,s=50 #数据点的尺寸大小
,c="red" #数据点的颜色
,label = "Red Points"
)
#装饰图形
plt.legend() #显示图例
plt.show() #让图形显示



【核心知识点】可视化分类标签时的图例
你是否注意到了?
如果我们希望显示多种颜色的散点图,并且这个颜色是我们的标签y所代表的分类,那我们无法让散点图显示分别代表不同颜色的图例
那我们应该怎么办呢?


现在我们只需要找到三个因素:
- 绘图用数据x1和x2
- 标签的列表
- 颜色
3. 开始认识绘图所需要的数据


4. 准备标签的列表和颜色
标签


颜色
接下来要创造和标签的类别一样多的颜色
如果只有三四个类别,或许我们还可以自己写
然而面对十几个,或者二十个分类,我们需要让matplotlib来帮助我们自动生成颜色
plt.cm.tab10()
用于创建颜色的十号光谱,在matplotlib中,有众多光谱供我们选择:https://matplotlib.org/tutorials/colors/colormaps.html
我们可以在plt.cm.tab10()中输入任意浮点数,来提取出一种颜色
光谱tab10中总共只有十种颜色,如果输入的浮点数比较接近,会返回类似的颜色
这种颜色会以元祖的形式返回,表示为四个浮点数组成的RGBA色彩空间或者三个浮点数组成的RGB色彩空间中的随机色彩


5. 生成基础的图像



#丰富我们的图像
#预设图像的各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, #子图上的标题字体大小
'legend.fontsize': med, #图例的字体大小
'figure.figsize': (16, 10), #图像的画布大小
'axes.labelsize': med, #标签的字体大小
'xtick.labelsize': med, #x轴上的标尺的字体大小
'ytick.labelsize': med, #y轴上的标尺的字体大小
'figure.titlesize': large} #整个画布的标题字体大小
plt.rcParams.update(params) #设定各种各样的默认属性
plt.style.use('seaborn-whitegrid') #设定整体风格
sns.set_style("white") #设定整体背景风格
%matplotlib inline
#准备标签列表和颜色列表
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
#建立画布
plt.figure(figsize=(16, 10) #绘图尺寸
, dpi=100 #图像分辨率
, facecolor='w' #图像的背景颜色,设置为白色,默认也是白色
, edgecolor='k' #图像的边框颜色,设置为黑色,默认也是黑色
)
#循环绘图
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=20, c=np.array(colors[i]).reshape(1,-1), label=str(category))
#注意到这里的数据获取方法和我们刚才写的不同了吗?
#我们不仅可以输入横纵坐标,也可以输入横纵坐标的名字,然后使用data这个参数来传入全数据集
#我们不仅可以循环i,还可以对i和category一同进行循环
#对图像进行装饰
#plt.gca() 获取当前的子图,如果当前没有任何子图的话,就帮我创建一个新的子图
plt.gca().set(xlim=(0, 0.12), ylim=(0, 80000)) #控制横纵坐标的范围
plt.xticks(fontsize=12) #坐标轴上的标尺的字的大小
plt.yticks(fontsize=12)
plt.ylabel('Population',fontsize=22) #坐标轴上的标题和字体大小
plt.xlabel('Area',fontsize=22)
plt.title("Scatterplot of Midwest Area vs Population", fontsize=22) #整个图像的标题和字体的大小
plt.legend(fontsize=12) #图例的字体大小
plt.show()

for i in range(len(categories)): #0~13
plt.scatter(midwest.loc[midwest["category"]==categories[i],"area"]
,midwest.loc[midwest["category"]==categories[i],"poptotal"]
,s=20
,c=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1)
,label=categories[i]
)
#循环绘图
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=20, c=np.array(colors[i]).reshape(1,-1), label=str(category))
#注意到这里的数据获取方法和我们刚才写的不同了吗?
#我们不仅可以输入横纵坐标,也可以输入横纵坐标的名字,然后使用data这个参数来传入全数据集
#我们不仅可以循环i,还可以对i和category一同进行循环

6. 解读图像



data.columns = ["城市ID","郡","州","面积","总人口","人口密度","白人人口","非裔人口","美洲印第安人人口","亚洲人口","其他人种人口"
,"白人所占比例","非裔所占比例","美洲印第安人所占比例","亚洲人所占比例","其他人种比例"
,"成年人口","具有高中文凭的比率","大学文凭比例","有工作的人群比例"
,"已知贫困人口","已知贫困人口的比例","贫困线以下的人的比例","贫困线以下的儿童所占比例","贫困的成年人所占的比例","贫困的老年人所占的比例"
,"是否拥有地铁","标签","点的尺寸","c1","c2","c3"]
#去掉所有类型为"object"的列,都是无用的信息
data = data.loc[:,data.dtypes.values != "O"]






#使用逻辑回归探索数据集
from sklearn.linear_model import LogisticRegression as logiR
import pandas as pd
for i in range(3): #三次建模,每次建模的y不同
logi = logiR(solver="newton-cg",max_iter=100**20,multi_class="multinomial").fit(Xtrain_,Ytrain.iloc[:,i].ravel())
print(y.columns[i])
print("\tTrain:{}".format(logi.score(Xtrain_,Ytrain.iloc[:,i].ravel()))) #模型的学习能力
print("\tTest:{}".format(logi.score(Xtest_,Ytest.iloc[:,i].ravel()))) #模型的泛化能力
coeff = pd.DataFrame(logi.coef_).T
if i != 2:
coeff["mean"] = abs(coeff).mean(axis=1)
coeff["name"] = Xtrain.columns
coeff.columns = ["Average","High","Low","mean","name"]
coeff = coeff.sort_values(by="mean",ascending=False).head()
else:
coeff["name"] = Xtrain.columns
coeff.columns = ["Coef","name"]
coeff = coeff.sort_values(by="Coef",ascending=False).head()
print(coeff)
print("\t")



plt.figure(figsize=(16, 10) #绘图尺寸
, dpi=60 #图像分辨率
, facecolor='w' #图像的背景颜色,设置为白色,默认也是白色
, edgecolor='k' #图像的边框颜色,设置为黑色,默认也是黑色
)
#进行循环绘图
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=20, c=np.array(plt.cm.tab10(i/float(len(categories)-1))).reshape(1,-1),label=str(category))
#高学历,低贫困的地方
plt.scatter("area","poptotal",
data = midwest.loc[midwest.category == "HLU",:],
s=300,
facecolors="None",
edgecolors="red",
label = "Selected")
#低学历,很贫困的地方
#plt.scatter("area","poptotal",
# data = midwest.loc[midwest.category == "LHR",:],
# s=150,
# facecolors="None", #点的填充颜色,为None的时候,表示点是透明的
# edgecolors="red", #点的边框现在是红色
# label = "Selected")
#再试试看,高学历,高贫困的地方?
#学历低,但很富有的地方?
#对图像进行装饰
plt.gca().set(xlim=(0.0, 0.12), ylim=(0, 90000)) #控制横纵坐标的范围
plt.xticks(fontsize=12) #坐标轴上的标尺的字的大小
plt.yticks(fontsize=12)
plt.ylabel('Population',fontsize=22) #坐标轴上的标题和字体大小
plt.xlabel('Area',fontsize=22)
plt.title("Scatterplot of Midwest Area vs Population", fontsize=22) #整个图像的标题和字体的大小
plt.legend(fontsize=12) #图例的字体大小
plt.show()

02/50 气泡图
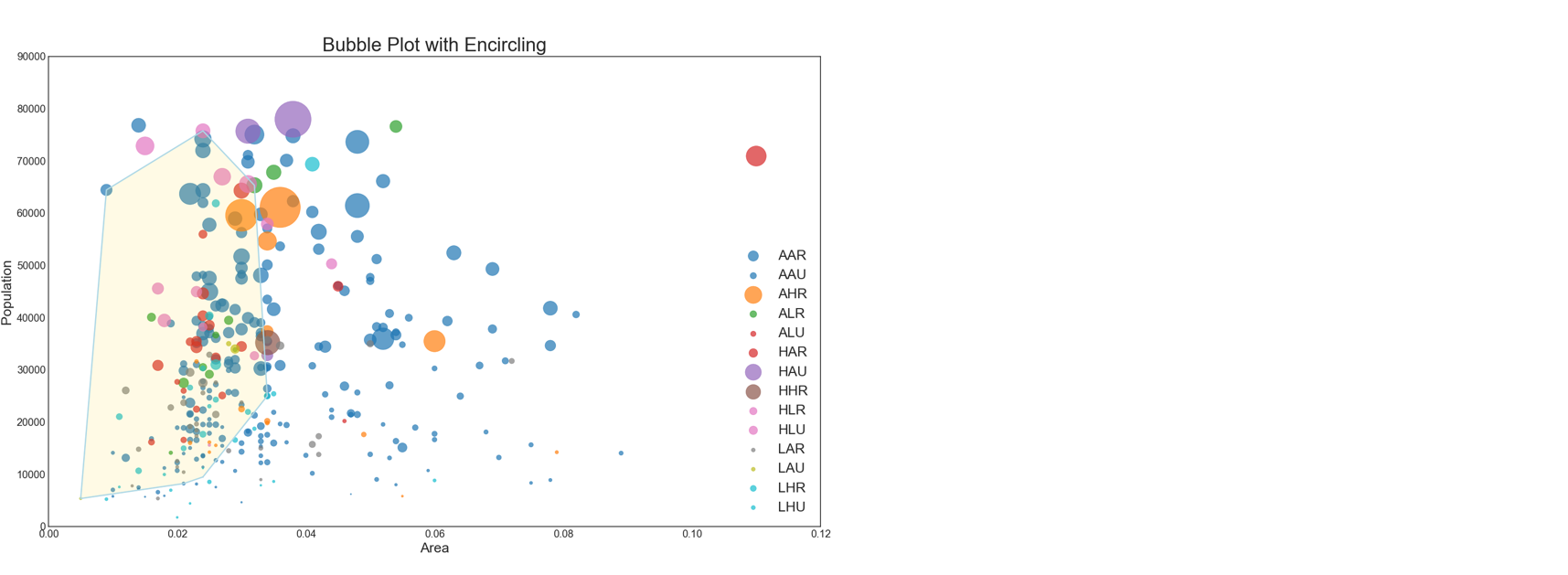 横坐标依然是面积,纵坐标依然是人口
横坐标依然是面积,纵坐标依然是人口
从01号图散点图的数据解读来看,其实为散点添加不同的颜色是增加图像中的信息维度
而气泡图其实也是一样:通过给散点增加面积信息,来增加图像中的信息维度 ### 1. 变散点为气泡  
#plt.style.use('seaborn-whitegrid')
#sns.set_style("white")
#预设图像的各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, #子图上的标题字体大小
'legend.fontsize': med, #图例的字体大小
'figure.figsize': (16, 10), #图像的画布大小
'axes.labelsize': med, #标签的字体大小
'xtick.labelsize': med, #x轴上的标尺的字体大小
'ytick.labelsize': med, #y轴上的标尺的字体大小
'figure.titlesize': large} #整个画布的标题字体大小
plt.rcParams.update(params) #设定各种各样的默认属性
#plt.style.use('seaborn-whitegrid') #设定整体风格
#sns.set_style("white") #设定整体背景风格
%matplotlib inline
#准备标签列表
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
#布置画布
fig = plt.figure(figsize=(14,8), dpi=120, facecolor='w', edgecolor='k')
#循环绘图
#之前在给散点加入颜色的时候,我们提到X轴,Y轴上的值和我们的颜色是一一对应的
#那只要点的尺寸和我们的坐标点(x1,x2)一一对应,那我们就可以相应地给每一个点添加尺寸信息
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :]
#, s = midwest.loc[midwest.category==category, "percasian"]*500 #调整尺寸,让散点图成为气泡图
, s = "popasian" #现在的特征为我们的点的尺寸大小
#, s=20 #size
, c= np.array(colors[i]).reshape(1,-1)
, label=str(category)
, edgecolors = np.array(colors[i]).reshape(1,-1) #点的边缘的颜色
#, edgecolors="k"
, alpha = 0.7 #图像的透明度
, linewidths=0.5 #点的外圈的线条的宽度
)
#装饰图像
plt.gca().set(xlim=(0.0, 0.12), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title("Bubble Plot with Encircling", fontsize=22)
plt.legend(fontsize=12
,markerscale=0.5 #现有的图例气泡的某个比例
)
plt.show()

#如果使用另外一种循环?
plt.figure(figsize=(16,10))
for i in range(len(categories)):
plt.scatter(midwest.loc[midwest["category"]==categories[i],"area"]
,midwest.loc[midwest["category"]==categories[i],"poptotal"]
,s=midwest.loc[:,"popasian"]
,c=np.array(plt.cm.tab10(i/len(categories))).reshape(1,-1)
,label=categories[i]
)
plt.legend()
plt.show()






#plt.style.use('seaborn-whitegrid')
#sns.set_style("white")
#预设图像的各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, #子图上的标题字体大小
'legend.fontsize': med, #图例的字体大小
'figure.figsize': (16, 10), #图像的画布大小
'axes.labelsize': med, #标签的字体大小
'xtick.labelsize': med, #x轴上的标尺的字体大小
'ytick.labelsize': med, #y轴上的标尺的字体大小
'figure.titlesize': large} #整个画布的标题字体大小
plt.rcParams.update(params) #设定各种各样的默认属性
#plt.style.use('seaborn-whitegrid') #设定整体风格
#sns.set_style("white") #设定整体背景风格
%matplotlib inline
#准备标签列表
categories = np.unique(midwest['category'])
colors = ["red","orange","pink"]
#布置画布
fig = plt.figure(figsize=(14,8), dpi=120, facecolor='w', edgecolor='k')
#循环绘图
for i, category in enumerate(["AHR","HAU","LHU"]):
data_ = midwest.loc[midwest.category==category, :]
data_.index = range(data_.shape[0])
plt.scatter('area', 'poptotal', data=data_
, s= midwest.loc[midwest.category==category, "poppovertyknown"]*0.05 #调整尺寸,让散点图成为气泡图
, c= colors[i]
, label=str(category)
, edgecolors= colors[i]
, alpha = 0.7
, linewidths=.5
)
for i in range(midwest.loc[midwest.category==category, :].shape[0]):
plt.text(data_.loc[i,"area"]
,data_.loc[i,"poptotal"]
,s=data_.loc[i,"county"] #虽然参数都写作s,但这里的s指的是字符串string的s,不是size的s
,fontdict={"fontsize":8} #调整我们的字符串的字体大小
,horizontalalignment='right' #相对于我的气泡,把我的字符串显示在哪里
)
#装饰图像
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title("Bubble Plot with Encircling", fontsize=22)
lgnd = plt.legend(fontsize=12
,markerscale=0.2
)
plt.show()

2. 将散点框起来

我们希望能够绘制一个边界,将同一类的点框起来。
在这里我们将用到SciPy库,这是一个专为Python设计的,专注于数学&工程学的库
今天我们将用到SciPy中专门处理空间算法和数据结构的模块:SciPy库中的spatial
scipy.spatial.ConvexHull()
ConvexHull直译是凸包,表示在一个平面上,我们能找到的最小的将一组数据全部包括在内的凸集
通俗的来说凸包就是包围一组散点的最小凸边形
相对的我们也有凹边形

重要属性
vertices:组成凸包的那些数据点在原数据中的索引
*更多参数和属性走:https://docs.scipy.org/doc/scipy-0.19.0/reference/generated/scipy.spatial.ConvexHull.html
from scipy.spatial import ConvexHull
from matplotlib import patches
#patches,给现有图像打补丁的包,在现有的图像上增加更多的东西
`
```python
#定义绘制凸包的函数
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca() #获取当前子图,如果当前子图不存在,那就创建新的子图(get current ax)
p = np.c_[x,y] #.c_功能类似于zip,不过不是生成组合的元祖,而是生成拼接起来的数组array
hull = ConvexHull(p) #将数据集输入到ConvexHull中,自动生成凸包类型的对象
poly = plt.Polygon(p[hull.vertices,:], **kw)
#使用属性vertices调用形成凸包的点的索引,进行切片后,利用绘制多边形的类plt.Polygon将形成凸包的点连起来
#这里的**kw就是定义函数的时候输入的**kw,里面包含了一系列可以在绘制多边形的类中进行调节的内容
#包括多边形的边框颜色,填充颜色,透明度等等
ax.add_patch(poly) #使用add_patch,将生成的多边形作为一个补丁补充到图像上



from scipy.spatial import ConvexHull
from matplotlib import patches
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
#预设图像的各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, #子图上的标题字体大小
'legend.fontsize': med, #图例的字体大小
'figure.figsize': (16, 10), #图像的画布大小
'axes.labelsize': med, #标签的字体大小
'xtick.labelsize': med, #x轴上的标尺的字体大小
'ytick.labelsize': med, #y轴上的标尺的字体大小
'figure.titlesize': large} #整个画布的标题字体大小
plt.rcParams.update(params) #设定各种各样的默认属性
plt.style.use('seaborn-whitegrid') #设定整体风格
sns.set_style("white") #设定整体背景风格
%matplotlib inline
#准备标签列表
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
#布置画布
fig = plt.figure(figsize=(16, 10), dpi=120, facecolor='w', edgecolor='k')
#循环绘图
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :]
, s="popasian" #调整尺寸,让散点图成为气泡图
, c= np.array(colors[i]).reshape(1,-1)
, label=str(category)
, edgecolors= np.array(colors[i]).reshape(1,-1)
, alpha = 0.7
, linewidths=.5)
#绘制凸包
#定义函数
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices,:], **kw)
ax.add_patch(poly)
#定义需要被框起来的数据:所有在IN州中的城市
midwest_encircle_data = midwest.loc[midwest.state=='IN', :]
#使用函数绘制
#这里绘制的是金色的面
encircle(midwest_encircle_data.area
, midwest_encircle_data.poptotal
, ec="k"
, fc="gold"
, alpha=0.1
)
#这里绘制的是浅蓝色的线,而面是透明的
encircle(midwest_encircle_data.area
, midwest_encircle_data.poptotal
, ec="lightblue" #线条颜色
, fc="none" #填充颜色
, linewidth=1.5 #线宽
)
#装饰图像
plt.gca().set(xlim=(0.0, 0.12), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Bubble Plot with Encircling", fontsize=22)
plt.legend(markerscale=0.6)
plt.show()
















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









