







Dajngo学习
Redis
1. 定义
高性能key-value内存数据库,具有持久化特性和数据多样性
2. NoSQL 技术
为了克服上述的问题,Django项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
Redis和MongoDB是当前使用最广泛的NoSQL,而就Redis技术而言,它的性能十分优越,可以支持每秒十几万此的读/写操作,其性能远超数据库,并且还支持集群、分布式、主从同步等配置,原则上可以无限扩展,让更多的数据存储在内存中,更让人欣慰的是它还支持一定的事务能力,这保证了高并发的场景下数据的安全和一致性。
3. Redis
概述
在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
安装
参考文档:https://www.jianshu.com/p/bb7c19c5fc47
4. redis 和 memcached 的区别
对于 redis 和 memcached 的区别有下面四点。
- redis支持更丰富的数据类型(支持更复杂的应用场景):Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。
- 集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
- Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。

5. Redis 在 开发中的应用
Redis 主要应用场景:
- 存储 缓存 用的数据;
- 需要高速读/写的场合使用它快速读/写;
- 消息中间键
1. 缓存
在日常对数据库的访问中,读操作的次数远超写操作,比例大概在 1:9 到 3:7,所以需要读的可能性是比写的可能大得多的。当我们使用SQL语句去数据库进行读写操作时,数据库就会去磁盘把对应的数据索引取回来,这是一个相对较慢的过程。
如果我们把数据放在 Redis 中,也就是直接放在内存之中,让服务端直接去读取内存中的数据,那么这样速度明显就会快上不少,并且会极大减小数据库的压力,但是使用内存进行数据存储开销也是比较大的,限于成本的原因,一般我们只是使用 Redis 存储一些常用和主要的数据,比如用户登录的信息等。
一般而言在使用 Redis 进行存储的时候,我们需要从以下几个方面来考虑:
- 业务数据常用吗?命中率如何?如果命中率很低,就没有必要写入缓存;
- 该业务数据是读操作多,还是写操作多?如果写操作多,频繁需要写入数据库,也没有必要使用缓存;
- 业务数据大小如何?如果要存储几百兆字节的文件,会给缓存带来很大的压力,这样也没有必要;
在考虑了这些问题之后,如果觉得有必要使用缓存,那么就使用它!使用 Redis 作为缓存的读取逻辑如下图所示:

从上图我们可以知道以下两点:
- 当第一次读取数据的时候,读取 Redis 的数据就会失败,此时就会触发程序读取数据库,把数据读取出来,并且写入 Redis 中;
- 当第二次以及以后需要读取数据时,就会直接读取 Redis,读到数据后就结束了流程,这样速度就大大提高了。
从上面的分析可以知道,读操作的可能性是远大于写操作的,所以使用 Redis 来处理日常中需要经常读取的数据,速度提升是显而易见的,同时也降低了对数据库的依赖,使得数据库的压力大大减少。
分析了读操作的逻辑,下面我们来看看写操作的流程
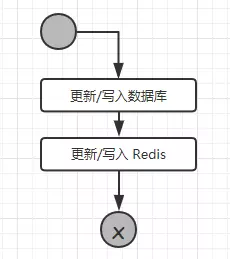
从流程可以看出,更新或者写入的操作,需要多个 Redis 的操作,如果业务数据写次数远大于读次数那么就没有必要使用 Redis。
关于使用内存存储数据,我知道谷歌好像就是把所有互联网的数据都存储在内存条的,所以才会有如此高质量、高效的搜索,但它毕竟是谷歌…
2. 高速读/写的场合
在如今的互联网中,越来越多的存在高并发的情况,比如天猫双11、抢红包、抢演唱会门票等,这些场合都是在某一个瞬间或者是某一个短暂的时刻有成千上万的请求到达服务器,如果单纯的使用数据库来进行处理,就算不崩,也会很慢的,轻则造成用户体验极差用户量流失,重则数据库瘫痪,服务宕机,而这样的场合都是不允许的!
所以我们需要使用 Redis 来应对这样的高并发需求的场合,我们先来看看一次请求操作的流程图:
 我们来进一步阐述这个过程:
我们来进一步阐述这个过程:
- 当一个请求到达服务器时,只是把业务数据在 Redis 上进行读写,而没有对数据库进行任何的操作,这样就能大大提高读写的速度,从而满足高速响应的需求;
- 但是这些缓存的数据仍然需要持久化,也就是存入数据库之中,所以在一个请求操作完 Redis 的读/写之后,会去判断该高速读/写的业务是否结束,这个判断通常会在秒杀商品为0,红包金额为0时成立,如果不成立,则不会操作数据库;如果成立,则触发事件将 Redis 的缓存的数据以批量的形式一次性写入数据库,从而完成持久化的工作。
3. 消息中间键
Django Celery作为分布式系统,可以实时处理大量的消息,需要任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。
Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等
6. Django 缓存
1. 为什么要用 redis /为什么要用缓存
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!

高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。

2. 使用redis作为缓存
1)django中配置
settings.py中加入redis设置:
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379", # 这里设定了本机的redis数据
# "LOCATION": "redis://:passwordpassword@47.193.146.xxx:6379/0", # 如果redis设置密码的话,需要以这种格式host前面是密码
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
2)Redis如何修改密码:
- 修改密码
1.找到redis配置信息文件,如/etc/redis.conf
2.找到 # requirepass foobared. 并去掉注释,后面的foobared改成你的密码。如:requirepass my_redis
3.重启redis, sudo service redid restart.(或者这样重启:sudo service redid restart, sudo redis-server /etc/redis.conf)
- 修改密码后登陆:
1.如果直接 redis-cli. 登陆,没密码,那么你能登陆,但无任何操作权限
2.用密码登陆。redis-cli -h 127.0.0.1 -p 6379 -a my_redis. 才能有权限操作
3.先redis-cli登陆,此时没有操作权限,再输入:AUTH your_password. 同样可以完成认证
3) 配置后在django项目中使用缓存:
- 使用Cache
from django.core.cache import cache
# 给redis中加入了键为key1,值为value1缓存,过期时间20秒
cache.set(“key1”, “value1”, 20).
# 参数:timeout=20, 过期时间20
# nx=True. 默认为False,重复命名时覆盖,True表示重复命名时不能再重新赋值
# 获取cache值:
val = cache.get(“key1”),
# 获取key3的过期时间,返回值:0表示无此键或已过期,None表示未设置过期时间,有过期时间的返回秒数。
cache.ttl(“key3”).
# 注意:在redis中存储的值并不是按照给定的键存储的,是根据键值又拼装的键(在你的key前面加上了个“:1:”)。
# 删除redis中key1的值
cache.delete(‘key1’)
- 使用get_redis_connection(保存热词,自动统计次数)
from django_reids import get_redis_connection
# get_redis_connection(‘default’)用法:
Conn = get_redis_connection(‘default’)
# 表示网redis里面存入了数据,键key1,值val1,但是注意不能再redis中获取,只能用conn获取,
# 返回值是添加量,初始为1.0,如果再加一个一摸一样的,就是2.0,注意:可以往一个键中添加多个值,如
Conn.zincrby(key1, '333').
Conn.zincrby(key1, 'HELLO')
Conn.zincrby(key1, 'ooo')
Conn.zincrby(key1, 'world')
Conn.zincrby(key1, '444')
Conn.zincrby(key1, '444')
Conn.zincrby(key1, '444')。 # 注意:这里val5添加了3次
# 如何获取刚才添加的呢?
li1 = conn.zrevrange(key1, 0, 10, True)
# li1就是:[('444', 3.0), ('world', 1.0), ('ooo', 1.0), ('HELLO', 1.0), ('333', 1.0)]
# 得到的数据是一个列表,取其中0-10(前10),按照刚才添加次数排序,val5添加了3次,所以权重值最大
# True表示,获得的值是个元组,False的话里面没有权重值,默认False
li2 = conn.zrevrange(key1, 0, 10)
# li2就是:['444', 'world', 'ooo', 'HELLO', '333']
# 我统计热搜关键词排序用到了
4. redis中的操作(redis-cli)
- redis基本操作(终端):
| 命令 | 含义 |
|---|---|
| del key | 删除key |
| keys * | 所有键 |
| get name | 获取name这个键的值 |
| del name | 删除name |
| set name “Gavin” | 创建“Gavin”,键为name |
| select 2 | 表示切换到2库,注:Django的cache是存在1库的(上面设置的),进入redis的时候默认是0库的 |
| TTL name | 查看剩余过期时间 |
| EXPIRE name 300 | 设置name的过期时间为300秒 |
| type name | 查看name的属性(总共:string, list, hash, set,zset) |
5. redis 数据结构
string 字符
| 操作 | 含义 |
|---|---|
| set key value | 设置 key 的值是 value |
| get key | 获取key的值 |
| expire key 100 | 设置过期时间100秒 |
| TTL key | 查看剩余过期时间 |
| append key aa | 给一个值后面加aa,类似字符串相加 |
| DERC key | 给key的值-1,仅限数字 |
| DERCBY key 4 | 给key的值-4,仅限数字 |
list 列表(类似于python的列表)
| 操作 | 含义 |
|---|---|
| lpush list_name a b c d e f | f e d c b a (依次从左边插入),如果没有就创建 |
| rpush list_name g | 从右边插入 |
| lrange list_name 0 -1 | 显示所有内容(根据下表来的) |
| lpop list_name | 从左边删除第一个数,返回值是删除的那个数 |
| rpop list_name | 从右边删除一个数,返回值是删除的那个数 |
| expire TTL | 方法和string一样 |
hash 哈希(类似于python的字典)
| 操作 | 含义 |
|---|---|
| hset hash_name key1 val1 | hash_name = {key1: val1} |
| hmset hash_name key1 val1 key2 val2 | hash_name = {key1: val1, key2: val2} |
| hget hash_name key1 | 获取key1 |
| hmget hash_name key1 key2 | 获取多个key |
| hgetall hash_name | 获取所有key |
| hkeys hash_name | 获取所有的key |
| hvals hash_name | 获取所有的val |
| hdel hash_name key | 删除hash_name中的key |
set 集合(存储不重复的值,无序)
| 操作 | 含义 |
|---|---|
| sadd set1 val1 val2 | 添加一个set1集合里的值val1,val2 |
| srem set1 val1 | 从set1中移除val1 |
| smembers set1 | set1的成员 |
| sismember set1 val1 | 查看val1是否在set1里,是返回1,否返回0 |
| sinter set1 set2 | 求交集 |
| sunion set1 set2 | 求并集 |
| sdiff set1 set2 | 求差集 |
zset(有序集合)
| 操作 | 含义 |
|---|---|
| zadd zset1 score member | 创建、添加一个zset1,member的分数是score(int) |
| zrangebyscore zset1 0 100 withscores | 得出zset1中分数score在0-100的member,score从小到大,后面的withscores是带score输出 |
| zrevrangebyscore zset1 100 0 | 从大到小输出 |
| zrange zset1 2 4 | 获取zset1中序号为3,4的member |
| zrank zset1 a | zset1中成员a的序号 |
| zrem zset1 a | 移除zset1中的a |
| zcount zset1 1 6 | 获取score为1-6之间的member数量 |
参考文档:
https://blog.csdn.net/qq_42183409/article/details/90167985
7. Java中的list
1. ArrayList
ArrayList是一个可以处理变长数组的类型,这里不局限于“数”组,ArrayList是一个泛型类,可以存放任意类型的对象。
顾名思义,ArrayList是一个数组列表,
因此其内部是使用一个数组来存放对象的,因为Object是一切类型的父类,因而ArrayList内部是有一个Object类型的数组类存放对象。
ArrayList类常用的方法有add()、clear()、get()、indexOf()、remove()、sort()、toArray()、toString()等等,
同时ArrayList内部有一个私有类实现Iterator接口,因此可以使用iterator()方法得到ArrayList的迭代器,
同时,还有一个私有类实现了ListIterator接口,因此ArrayList也可以调用listIterator()方法得到ListIterator迭代器。
由于ArrayList是依靠数组来存放对象的,只不过封装起来了而已,因此其一些查找方法的效率都是O(n),跟普通的数组效率差不多,只不过这个ArrayList是一个可变”数组“,并且可以存放一切指定的对象。
另外,由于ArrayList的所有方法都是默认在单一线程下进行的,因此ArrayList不具有线程安全性。
若想在多线程下使用,应该使用Colletions类中的静态方法synchronizedList()对ArrayList进行调用即可。
2. LinkedList
LinkedList可以看做为一个双向链表,所有的操作都可以认为是一个双向链表的操作,因为它实现了Deque接口和List接口。
同样,LinkedList也是线程不安全的,如果在并发环境下使用它,同样用Colletions类中的静态方法synchronizedList()对LinkedList进行调用即可。
在LinkedList的内部实现中,并不是用普通的数组来存放数据的,而是使用结点来存放数据的,有一个指向链表头的结点first和一个指向链表尾的结点last。
不同于ArrayList只能在数组末尾添加数据,LinkList可以很方便在链表头或者链表尾插入数据,或者在指定结点前后插入数据,还提供了取走链表头或链表尾的结点,
或取走中间某个结点,还可以查询某个结点是否存在。add()方法默认在链表尾部插入数据。总之,LinkedList提供了大量方便的操作方法,
并且它的插入或增加等方法的效率明显高于ArrayList类型,但是查询的效率要低一点,因为它是一个双向链表。
因此,LinkedList与ArrayList最大的区别是LinkedList更加灵活,并且部分方法的效率比ArrayList对应方法的效率要高很多,对于数据频繁出入的情况下,
并且要求操作要足够灵活,建议使用LinkedList;对于数组变动不大,主要是用来查询的情况下,可以使用ArrayList
ArrayList和LinkedList 总结
**共性 **
ArrayList与LinkedList都是List接口的实现类,因此都实现了List的所有未实现的方法,只是实现的方式有所不同。
区别:
List接口的实现方式不同,ArrayList实现了List接口,以数组的方式来实现的,因此对于快速的随机取得对象的需求,使用ArrayList实现执行效率上会比较好。
LinkedList是采用链表的方式来实现List接口的,因此在进行insert和remove动作时效率要比ArrayList高。适合用来实现Stack(堆栈)与Queue(队列)。















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









