







Python开发工程师面试题-整理
- 一、 python基础:
- 1、如何构造一个 单元素元组?
- 2、python的字典用的是什么数据结构?
- 3、给python的对象赋值,实际上做的是值copy还是对象引用?谈谈浅拷贝和深拷贝,如何实现深copy?
- 4、模块导入----搜索路径
- 5、包的作用,__init__.py的作用?
- 6、谈谈python类的构造器__init__(),__new__()的作用与区别?谈谈结构器__del__()的作用及原理
- 7、python类的实例属性vs类属性?
- 8、元类__metaclass__是什么?何时被创建?什么时候被使用?
- 9、画出TCP通信的三次握手 和 四次挥手的简易图。
- 10、写出socket网络通信的demo
- 11、Python 中list ,set,dict的大规模查找效率谁更快
- 12. python 数据类型
- 13. @staticmethod和@classmethod有什么异同?
- 14. 类变量和实例变量有什么异同?
- 15. 怎么理解迭代器?
- 16. 怎样理解*args **kwargs?
- 17 理解生成器
- 18. 写一个单例模式的类,并写代码调用它
- 是否对其他模式有了解
- 20. GIL线程全局锁,为何影响python的性能,如何突破它?
- 多线程和多进程的适用场景
- 21. 协程是个什么样的概念,了解它的原理吗?请举例说明协程的应用场景.
- 22. 闭包是个什么样的概念,了解它的原理吗?请举例说明闭包的应用场景.
- 23. copy(),deepcopy()有什么区别?
- 24. 文件操作 read readline readlines 有什么区别,他们返回值是什么?
- 25. Python3.5 中的await async关键字有什么用?
- 26. Python垃圾回收是怎么做的?
- 27 Redis的了解
- 28 Mysql 的事务性
- 29 如何理解restful 以及restful的缺点
- 30 如何用列表实现队列和栈
- 31 链表和列表的区别
- 32 分析顺序链表和顺序列表的插入
- 33 输入一个ip地址,到你看到内容,其间经历的过程
- 35 网络知识
- 36
- 34 杂七杂八
- 二 python 机试
一、 python基础:
1、如何构造一个 单元素元组?
示例:>>>type([‘abc’]) 表示一个单链表 >>>(’abc’) 表示的是啥?
- 元组是不变的,是只读的,可以作为映射中的键值使用。
- 很多内建函数与方法的返回值都是元组,
30, #创建只有一个元素的元组
(12,) #创建只有一个元素的元组
40 #知识一个普通的值,并不是元组
'''将序列转换成元组,可以使用tuple函数'''
value=tuple([1,2,3,4])
2、python的字典用的是什么数据结构?
哈希表(hash table)也叫作散列表,这种数据结构提供了键(key)和值(value)的映射关系。只要给出一个key,就可以高效查找到它所匹配的value,时间复杂度接近于O(1)。
字典又被称为 ’哈希表‘, 它是以key-value的方式进行存储,通过key进行hash存储,查找操作的效率非常高。
字典中的key对象必须实现__hash__ 和 __eq__方法的,
字典在查找时会计算key的hash值,然后通过模运算定位到key的下标,如果下标只有一个元素,直接返回value,如果有多个元素存储在同一个下标里,通过__eq__ 方法进行比较,相同者放回。
数据结构分类
(1)数组:数组是由有限个相同类型的变量所组成的有序集合,它的物理存储方式是顺序存储,访问方式是随机访问。利用下表查找数组元素的时间复杂度是O(1),中间插入、删除数组元素的时间复杂度是O(n)。
(2)链表:链表是一种链式数据结构,由若干节点组成,每个节点包含指向下一节点的指针。链表的物理存储方式是随机存储,访问方式是顺序访问。查找链表节点的时间复杂度是O(n),中间插入、删除节点的时间复杂度是O(1)。
(3)栈:栈是一种线性逻辑结构,可以用数组实现,也可以用链表实现。栈包含入栈和出栈操作,遵循先入后出的原则。
(4)队列:队列也是一种线性逻辑结构,可以用数组实现,也可以用链表实现。队列包含入队和出队操作,遵循先入先出的原则。
(5)哈希表:哈希表也叫作散列表,是存储 key-value映射的集合。对于某一个key,哈希表可以在接近O(1)的时间复杂度内进行读写操作。哈希表通过哈希函数实现key和数组下标的转换,通过开放寻址法和链表法来解决哈希冲突。
3、给python的对象赋值,实际上做的是值copy还是对象引用?谈谈浅拷贝和深拷贝,如何实现深copy?
对象引用
- copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象
- copy.deepcopy 深拷贝 拷贝对象及其子对象
补充:
== 和 is
== 指判断值相等。 is 指内存地址相等,即指引用相等。 a == b
判断 a 对象的值是否和 b 对象的值相等。通过Value 值来判断。
a is b
判断 a 对象是否就是 b 对象。 通过 Id 来判断。
4、模块导入----搜索路径
通常情况下,当使用 import 语句导入模块后,Python 会按照以下顺序查找指定的模块文件:
- 在当前目录,即当前执行的程序文件所在目录下查找;
- 到 PYTHONPATH(环境变量)下的每个目录中查找;
- 到 Python 默认的安装目录下查找。
以上所有涉及到的目录,都保存在标准模块 sys 的 sys.path 变量中,通过此变量我们可以看到指定程序文件支持查找的所有目录。
换句话说,如果要导入的模块没有存储在 sys.path 显示的目录中,那么导入该模块并运行程序时,Python 解释器就会抛出 ModuleNotFoundError(未找到模块)异常。
解决“Python找不到指定模块”的方法有 3 种,分别是:
- 向 sys.path 中临时添加模块文件存储位置的完整路径;
- 将模块放在 sys.path 变量中已包含的模块加载路径中;
- 设置 path 系统环境变量。
import sys
'''需要将调用脚本的目录保存到环境中'''
sys.path.insert(0, r'C:\Users\XXX\Desktop')
import hello
print(sys.path)
hello.hello()
5、包的作用,init.py的作用?
init.py 文件的作用是将文件夹变为一个Python模块。
init.py主要是用来初始化Python包的(package)
Python中的包和模块有两种导入方式:精确导入和模糊导入:
模糊导入:from package import *
可以在 init.py 文件中定义 all 来限制模糊导入的内容。
精确导入: from test_init import test2
'''文件目录架构'''
test_init
-- __init.py
-- test1.py
-- test2.py
'''__init__.py'''
import os
__all__ = ['test1']
'''test1.py'''
def get_hello():
return 'test1 is called'
'''test2.py'''
def get_hello():
return 'test2 is called'
import os
from test_init import test2
from test_init import *
'''精确导入'''
print(test2.get_hello())
'''模糊导入, 通过在 __init__.py设置'''
print(test1.get_hello())
'''将package里面的module '''
print(os.getcwd())
6、谈谈python类的构造器__init__(),new()的作用与区别?谈谈结构器__del__()的作用及原理
new、init、__del__三个方法用于实例的创建、初始化、销毁
new
__new__在初始化实例之前被调用,用以创建实例然后返回该实例对象,是个静态方法
__new__必须要有返回值,就是返回创建的实例,也可以返回父类new出的实例或者是object的new出来的实例
__new__返回值会传给__init__方法第一个参数self,然后__init__给该对象设置一些属性
__new__至少要有一个参数cls,表示要实例化的类,此参数在实例化时由python解释器自动提供
自定义类中没有重写该方法,则Python自动调用父类的方法,当所有父类也没有重写定义该方法时,则直接调用object类的__new__方法
init
__init__是实例对象创建完成后被调用,然后设置对象属性的一些初始值通常用在初始化一个实例的时候,是一个实例方法
__init__的参数self就是__new__返回的实例,__init__在__new__的基础上可以完成一些其他初始化的操作,__init__不需要返回值
del
del:在需要销毁实例的时候,python解释器会调用__del__方法。Cpython中垃圾回收的主要算法是引用计数,每个对象会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁
7、python类的实例属性vs类属性?
- 类变量指的是在类中,但在各个类方法外定义的变量。
class CLanguage :
# 下面定义了2个类变量
name = "C语言中文网"
add = "http://c.biancheng.net"
# 下面定义了一个say实例方法
def say(self, content):
print(content)
- 实例变量指的是在任意类方法内部,以“self.变量名”的方式定义的变量,
其特点是只作用于调用方法的对象。
另外,实例变量只能通过构造后的对象名访问,无法通过类名访问。
class CLanguage :
def __init__(self):
self.name = "C语言中文网"
self.add = "http://c.biancheng.net"
# 下面定义了一个say实例方法
def say(self):
self.catalog = 13
- 局部变量直接以“变量名=值”的方式进行定义
class CLanguage :
# 下面定义了一个say实例方法
def count(self,money):
sale = 0.8*money
print("优惠后的价格为:",sale)
clang = CLanguage()
clang.count(100)
8、元类__metaclass__是什么?何时被创建?什么时候被使用?
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
class MyList(list, metaclass=ListMetaclass):
pass
下面是运行结果,测试一下MyList是否可以调用add()方法:
>>> L = MyList()
>>> L.add(1)
>> L
[1]
https://blog.csdn.net/Windgs_YF/article/details/99682499
9、画出TCP通信的三次握手 和 四次挥手的简易图。
三次握手:
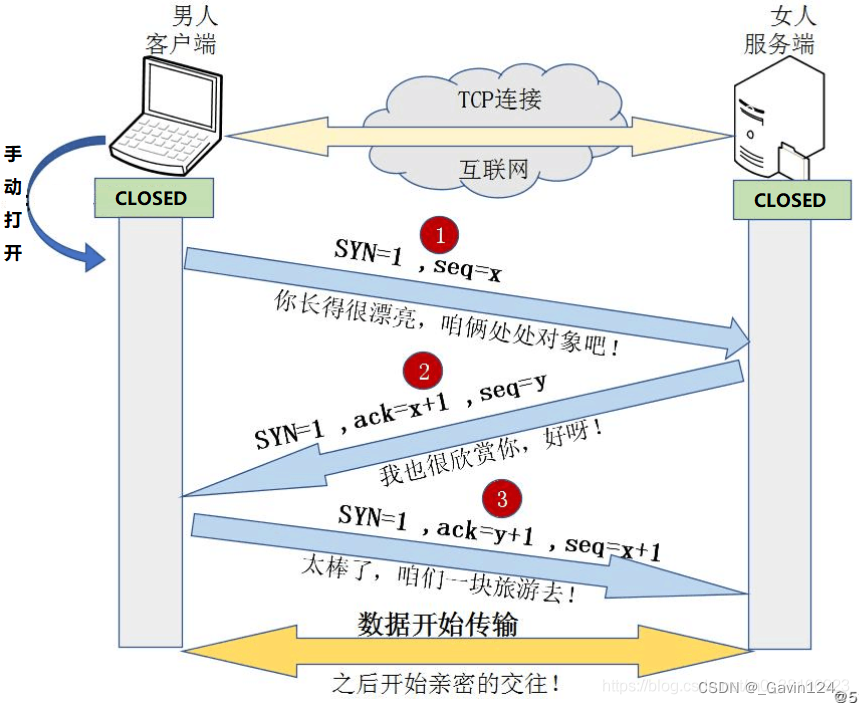
三次握手过程详细说明:
1、客户端发送建立TCP连接的请求报文,其中报文中包含seq序列号,是由发送端随机生成的,并且将报文中的SYN字段置为1,表示需要建立TCP连接。(SYN=1,seq=x,x为随机生成数值);
2、服务端回复客户端发送的TCP连接请求报文,其中包含seq序列号,是由回复端随机生成的,并且将SYN置为1,而且会产生ACK字段,ACK字段数值是在客户端发送过来的序列号seq的基础上加1进行回复,以便客户端收到信息时,知晓自己的TCP建立请求已得到验证。(SYN=1,ACK=x+1,seq=y,y为随机生成数值)这里的ack加1可以理解为是确认和谁建立连接;
3、客户端收到服务端发送的TCP建立验证请求后,会使自己的序列号加1表示,并且再次回复ACK验证请求,在服务端发过来的seq上加1进行回复。(SYN=1,ACK=y+1,seq=x+1)。
四次挥手:
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
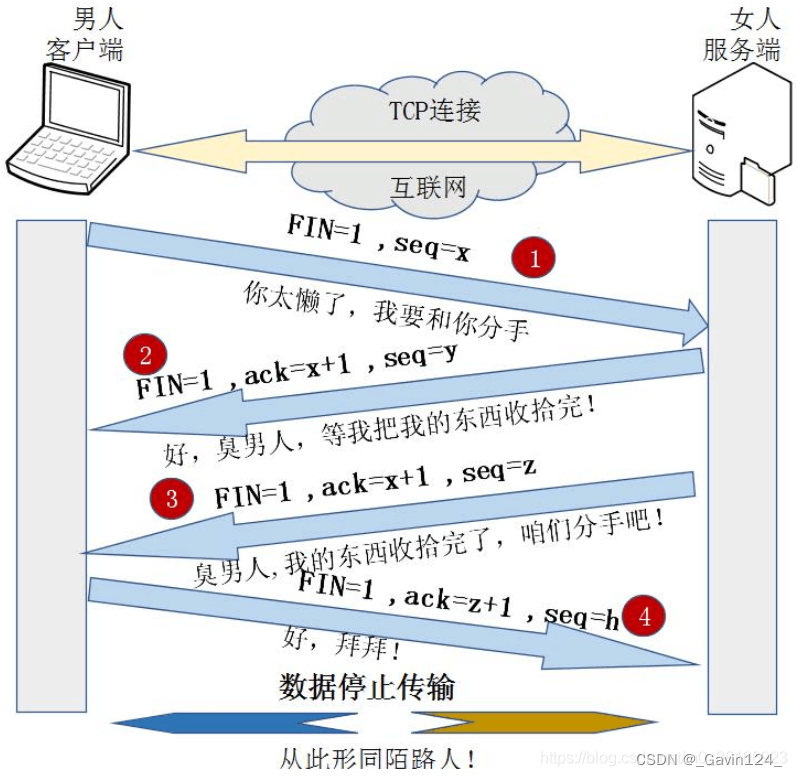
四次挥手过程详细说明:
1、客户端发送断开TCP连接请求的报文,其中报文中包含seq序列号,是由发送端随机生成的,并且还将报文中的FIN字段置为1,表示需要断开TCP连接。(FIN=1,seq=x,x由客户端随机生成);
2、服务端会回复客户端发送的TCP断开请求报文,其包含seq序列号,是由回复端随机生成的,而且会产生ACK字段,ACK字段数值是在客户端发过来的seq序列号基础上加1进行回复,以便客户端收到信息时,知晓自己的TCP断开请求已经得到验证。(FIN=1,ACK=x+1,seq=y,y由服务端随机生成);
3、服务端在回复完客户端的TCP断开请求后,不会马上进行TCP连接的断开,服务端会先确保断开前,所有传输到A的数据是否已经传输完毕,一旦确认传输数据完毕,就会将回复报文的FIN字段置1,并且产生随机seq序列号。(FIN=1,ACK=x+1,seq=z,z由服务端随机生成);
4、客户端收到服务端的TCP断开请求后,会回复服务端的断开请求,包含随机生成的seq字段和ACK字段,ACK字段会在服务端的TCP断开请求的seq基础上加1,从而完成服务端请求的验证回复。(FIN=1,ACK=z+1,seq=h,h为客户端随机生成)
至此TCP断开的4次挥手过程完毕。
10、写出socket网络通信的demo
https://www.bbsmax.com/A/xl56G0r0dr/
server.py
import socket
# 创建服务器套接字
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 这里要注意:绑定IP、端口号的时候 要用 元组的形式!端口号位于:0-65535这个区间
s.bind(('127.0.0.1', 8001))
s.listen()
# 接受客户端链接,接收客户端连接(相当于TCP协议中的建立连接的过程【3次握手】),
# 通过该方法可以返回(双方的连接信息,客户端的IP地址和端口号),注意这是元组的形式!
conn, addr = s.accept()
while True:
# 收消息,这个1024是指接收的字节数,得到的是data返回值是bytes二进制值!
ret = conn.recv(1024)
print(ret.decode('utf-8'))
if ret == b"bye":
conn.send(b"bye")
break
info = input('>>>')
conn.send(info.encode('utf-8'))
conn.close()
s.close()
client.py
import socket
s = socket.socket()
s.connect(('127.0.0.1', 8001))
while True:
info = input('>>>')
# 一定要注意:发送的数据要是Bytes格式的,即二进制形式的数据
s.send(info.encode('utf-8'))
ret = s.recv(1024)
if ret == b'bye':
s.send(b'bye')
break
print(ret.decode('utf-8'))
s.close()
11、Python 中list ,set,dict的大规模查找效率谁更快
'''
查找效率:set>dict>list
单次查询中:看来list 就是O(n)的;而set做了去重,本质应该一颗红黑树(猜测,STL就是红黑树),复杂度O(logn);
dict类似对key进行了hash,然后再对hash生成一个红黑树进行查找,其查找复杂其实是O(logn),并不是所谓的O(1)。
O(1)只是理想的实现,实际上很多hash的实现是进行了离散化的。
dict比set多了一步hash的过程,so 它比set慢,不过差别不大。
原文链接:https://blog.csdn.net/jmh1996/article/details/78481365
set()
因为每存一个值到set里时, 都要先经过hash,然后通过得出的这个hash值算出应该存在set里的哪个位置,
存的时候会先检查那个位置上有没有值,
有的话就对比是否相等,如果相等,则不再存储此值。 如果不相等(即为空),则把新值 存在这。
链接:https://www.jianshu.com/p/70c98a096488
数据结构:
list: 线性链表
dict: hash算法
'''
import numpy
import time
l = []
sl = set()
dl = dict()
r = numpy.random.randint(0, 10000000, 100000)
for i in range(0, 100000):
l.append(r[i])
sl.add(r[i])
dl.setdefault(r[i], 1)
# 生成3种数据结构供查找,常规的list,集合sl,字典dl.里面的元素都是随机生成的,为什么要随机生成元素?这是防止某些结构对有序数据的偏向导致测试效果不客观。
start = time.clock()
for i in range(100000):
t = i in sl
end = time.clock()
print("set:", end - start)
'''计算通过set来查找的效率'''
start = time.clock()
for i in range(100000):
t = i in dl
end = time.clock()
print("dict:", end - start)
'''计算通过dict的效率'''
start = time.clock()
for i in range(100000):
t = i in l
end = time.clock()
print("list:", end - start)
'''计算通过list的效率'''
>
>set: 0.01762632617301519
dict: 0.021149536796960248
12. python 数据类型
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
13. @staticmethod和@classmethod有什么异同?
- @staticmethod就像普通函数一样使用,不用表示自身对象的self参数,也不用表示自身类的cls参数,用法就像是普通函数,调用类属性和方法时,用类名.属性名和类名.方法名()
- @classmethod也没有自身对象的self参数,但是有一个表示自身类的参数cls,调用类属性和类方法的时候,使用cls.调用
class Base():
num = 1
def func(self):
print('abc')
@classmethod
def ccc(cls):
print('class method')
print(cls.num)
cls().func()
@staticmethod
def sss():
print('static method')
Base().func()
print(Base().num)
Base().ccc()
Base().sss()
a=Base()
a.func()
输出:
class method
1
abc
static method
abc
1
abc
14. 类变量和实例变量有什么异同?
- 类变量:可在类的所有实例之间共享的值(也就是说,它们不是单独分配给每个实例的)。
- 实例变量:实例化之后,每个实例单独拥有的变量。
15. 怎么理解迭代器?
可迭代对象
- 可以直接作用于for循环的对象称为可迭代对象:Iterable
- 分类
- 一类是集合数据类型:list、tuple、dict、set、str等
- 一类是generator
- 可以用isinstance()判断是否是可迭代对象
- isinstance([],Iterable)
迭代器
- 可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
- 可以用isinstance()判断是否是迭代器
- isinstance([],Iterator)
- 所有的迭代器都是可迭代对象
- 用iter()可以把非迭代器的可迭代对象变成迭代器(str、list等)
- iter(‘abc’)
- 迭代器标识一个惰性计算的序列
总结
- 凡是可作用于for循环的对象都是可迭代对象(iterable类型)
- 凡是可作用于next()函数的对象都是迭代器(iterator类型)
- 集合数据类型(list、dict、str等)是iterable但不是iterator,不过可以通过iter()函数变成iterator
- python循环本质上就是通过不断调用next()函数实现的
- 包含关系
- 可迭代对象(:iterable):可作用于for循环
- 生成器(迭代器)(:iterator):可作用于next()函数
- 集合数据类型
16. 怎样理解*args **kwargs?
*args:位置参数,
**kwargs:关键字参数
def receive_args(*args, **kwargs):
print(f'args type is: {type(args)}, value is: {args}')
print(f'kargs type is: {type(kwargs)}, value is: {kwargs}')
if __name__ == '__main__':
receive_args(0,name='jyz')
args type is: <class 'tuple'>, value is: (0,)
kargs type is: <class 'dict'>, value is: {'name': 'jyz'}
17 理解生成器
定义: 一遍虚循环一遍计算的机制,称为生成器
两种方式生成生成器
- 生成器表达式: d = (i for i in range(1, 10))
- 生成器函数:
import time
def inf_N():
num = 1
while num <= 100:
temp = yield num
'''
执行顺序是:
①yield num将num返回出去;
②将"yield num"这个个表达式的值交给变量temp,
但是num已经被yield返回出去了,所以交给temp的只能是None了
yield与return一样会将num返回出去,但不是像return一样结束函数。
而是会卡在这里不执行,直到下一次使用next()方法唤醒
'''
num += 1
print(temp)
print("数据已经生成并拿走完毕!")
return None
if __name__ == '__main__':
inf_N_gennerate = inf_N()
while True:
# time.sleep(0.5)
print(next(inf_N_gennerate))
18. 写一个单例模式的类,并写代码调用它
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
class Singleton(object):
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = object.__new__(cls)
return cls._instance
def __init__(self, name, age):
self.name = name
self.age = age
s1 = Singleton('Gavin', '18')
s2 = Singleton('Venna', '17')
print(id(s1))
print(id(s2))
print(s1.__dict__)
print(s2.__dict__)
要想弄明白为什么每个对象被实例化出来之后, 都会重新被分配出一块新的内存地址, 就要清楚一个python中的内置函数__new__(), 它跟__init__()一样, 都是对象在被创建出来的时候, 就自动执行的一个函数,
init()函数, 是为了给函数初始化属性值的,
而__new__()这个函数, 就是为了给对象在被实例化的时候, 分配一块内存地址,
因此, 我们可以重写__new__()这个方法, 让他在第一次实例化一个对象之后, 分配一块地址, 在此后的所有实例化的其他对象时, 都不再分配新的地址, 而继续使用第一个对象所被分配的地址, 因此, 我们可以在类对象里, 定义一个类属性, 初始值设为None, 如果这个值是None就调用父类的__new__()方法, 为其分配地址, 并返回这个地址(__new__方法一定要返回一个地址)
是否对其他模式有了解
工厂模式定义:
在面向对象编程中,术语“工厂”表示一个负责创建替他类型对象的类。通常情况下,作为一个工厂的类有一个对象以及与它关联的多个方法。
客户端使用某些参数调用此方法,之后,工厂会据此创建所需类型的对象,然后将它们返回给客户端。
它的优点:
- 松耦合,对象的创建独立于类的实现
- 客户端无需了解创建对象的类,只需知道需要传递的接口,方法和参数就能够创建所需要的对象
- 很容易扩展工厂添加其他类型对象的创建,而使用者只需要改变参数就可以了
from abc import ABCMeta, abstractmethod
"""
建立一个可乐的抽象类,百事可乐和可口可乐继承这个抽象类
ABCMeta是python的一个元类,用于在Python程序中创建抽象基类,抽象基类中声明的抽象方法,使用abstractmethod装饰器装饰。
"""
class Coke(metaclass=ABCMeta):
@abstractmethod
def drink(self):
pass
class Kekou(Coke):
def drink(self):
print('喝可口可乐')
class Baishi(Coke):
def drink(self):
print('喝百事可乐')
"""
建立快餐店类,也就是所说的工厂类,让它生产可乐。
当用户需要可乐时,只需要告诉快餐店做一份什么品牌的可乐,告诉快餐店可乐的名字,然后快餐店使用make_coke方法做可乐,返回了你所需要的对象
拿到可口可乐的对象,就可以调用自己实现的方法了。
"""
class Fast_food_restaurant:
def make_coke(self, name):
# eval(类名)返回的是一个class类型的对象
return eval(name)()
kfc = Fast_food_restaurant()
coke = kfc.make_coke('Kekou')
coke.drink()
20. GIL线程全局锁,为何影响python的性能,如何突破它?
全局解释器锁(global interpreter lock):
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
有了全局解释器锁(GIL)为什么还需要同步锁?
全局解析器锁(GIL)加在了全局了,没有加到我所想要的位置,加到什么位置不是我们决定的;
包括修改资源的程序和非修改资源的程序,如果出现在修改资源的相关代码上,肯定会出现脏数据。
同步锁:来获取一把互斥锁。互斥锁就是对共享数据进行锁定,保证同一时刻只有一个线程操作数据,是数据级别的锁。
GIL锁是解释器级别的锁,保证同一时刻进程中只有一个线程拿到GIL锁,拥有执行权限。
多线程是否一定能提高效率?
不一定;
原因在于GIL(global interpreter lock),在解释器解释执行Python代码的时候,必须先得到这把锁.意味着,任何时候都只能有一个线程在执行代码.
其它线程要想获得 CPU 执行代码指令,就必须先获得这把锁,如果锁被其它线程占用了,那么该线程就只能等待,直到占有该锁的线程释放锁才有执行代码指令的可能。
这也就是为什么两个线程一起执行反而更加慢的原因,因为同一时刻,只有一个线程在运行,其它线程只能等待,即使是多核CPU,也没办法让多个线程并行执行代码,只能是交替执行,因为多线程涉及到上线文切换、锁机制处理(获取锁,释放锁等),所以,多线程执行不快反慢。
CPU密集型(适合于C)和IO密集型(这个适合Python.)
IO密集型任务(I/O bound)的特点是指磁盘IO、网络IO占主要的任务,CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。
对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如请求网页、读写文件等。当然我们在Python中可以利用sleep达到IO密集型任务的目的。
对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
因为GIL的存在,只有IO Bound场景下得多线程会得到较好的性能
多线程和多进程的适用场景
哪些情况适合用多线程呢:
只要在进行耗时的IO操作的时候,能释放GIL,所以只要在IO密集型的代码里,用多线程就很合适
哪些情况适合用多进程呢:
用于计算密集型,比如计算某一个文件夹的大小。
python下想要充分利用多核CPU,就用多进程”,原因是什么呢?
每个进程有各自独立的GIL,互不干扰,这样就可以真正意义上的并行执行,所以在python中,多进程的执行效率优于多线程(仅仅针对多核CPU而言)。
21. 协程是个什么样的概念,了解它的原理吗?请举例说明协程的应用场景.
协程又称为微线程
拥有自己的寄存器上下文和栈.协程调度切换的时候,将寄存器上下文和栈保存到其他地方,切回来的时候,可以回复先前保存的寄存器上下文和栈
因此:协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态(进入上一次离开时所处逻辑流的位置)
协程与线程类似,每个协程表示一个执行单元,既有自己的本地数据,也与其他协程共享全局数据和其他资源。
协程存在于线程中,需要用户来编写调度逻辑,对CPU而言,不需要考虑协程如何调度,切换上下文。
优点:
- 无需线程上下文切换的开销
- 无需原子操作锁定以及同步的开销
- 高并发+高扩展性+低成本
缺点
- 无法利用多核资源,协程的本质是一个单线程,他不能同时将多核CPU用上,协程需要和进程搭配才能运行在多核CPU上
- 进行阻塞(blocking)操作(如IO的时候)会阻塞掉整个程序
'''
asyncio 模块通过一个线程执行并发任务
- 通过 async 和 await 关键字提供支持
- 通过事件循环来实现
协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
异步IO,相对合并起来,一段时间执行多个任务
'''
import asyncio
import time
from asyncio.exceptions import TimeoutError
async def calculate(n1, n2):
'''定义一个协程'''
print(n1 + n2)
return n1 + n2
# asyncio.run(calculate(1, 2))
'''
异步IO 创建任务
'''
async def call_api(name, delay):
print(f'{name} -- step 1 start')
await asyncio.sleep(delay)
print(f'{name} -- step 1 end')
async def main():
time1 = time.perf_counter()
print('start A coroutine')
# await call_api('A', 3)
task1 = asyncio.create_task(call_api('A', 3))
# print('finished A coroutine')
print('start B coroutine')
task2 = asyncio.create_task(call_api('B', 3))
# await call_api('B', 3)
# print('finished B coroutine')
# 等待这两个协程都结束,main 函数才继续往下走
# 实现 并发的效果
await task1
print("task 1 completed")
await task2
print("task 2 completed")
time2 = time.perf_counter()
print(f'Spent {time2 - time1}')
# asyncio.run(main())
'''
取消任务
- Task.done() 判断一个任务是否已经完成
- Task.cancel() 取消一个任务
超时取消任务
- Task.wait_for()
- asyncio.shield() 加盾牌 ,提示你超时,盾牌保护,等待任务结束
直接并行多任务并等待结束,返回结果
- gather()函数
任务异常
- return_exceptions = True 不会报异常,在结果里面显示有异常
'''
async def play_music(name):
print(f'start playing {name}')
await asyncio.sleep(5)
print(f'finished playing {name}')
return name
async def play_music_cancel():
task = asyncio.create_task(play_music('A'))
await asyncio.sleep(3)
if not task.done():
print('cancel playing A')
task.cancel()
async def play_music_cancel_with_timeout():
task = asyncio.create_task(play_music('A'))
try:
await asyncio.wait_for(task, timeout=2)
except TimeoutError as e:
print(e)
print('timeout')
async def my_gather():
results = await asyncio.gather(play_music('A'), play_music('B'))
print(results)
if __name__ == '__main__':
# asyncio.run(play_music_cancel_with_timeout())
asyncio.run(my_gather())
22. 闭包是个什么样的概念,了解它的原理吗?请举例说明闭包的应用场景.
定义: 闭包就是外部函数中定义一个内部函数,内部函数引用外部函数中的变量,外部函数的返回值是内部函数
# 闭包
def out(i): # 一个外层函数
def inner(j): # 内层函数
return i*j
return inner
23. copy(),deepcopy()有什么区别?
一、浅拷贝-copy
1、复制不可变数据类型(int、string、tuple)的时候,无论是copy(浅拷贝)、deepcopy(深拷贝)或者“=” 的地址都与原对象id地址一样
import copy
# 不可变类型(int、string、tuple)
a = "你好"
b = a
c = copy.copy(a) # 浅拷贝
d = copy.deepcopy(a) # 深拷贝
print("a的原地址", id(a))
print("a的赋值地址b", id(b))
print("a的浅拷贝的地址c", id(c))
print("a的深拷贝的地址d", id(d))
'''
输出结果:
a的原地址 2500335886384
a的赋值地址b 2500335886384
a的浅拷贝的地址c 2500335886384
a的深拷贝的地址d 2500335886384
'''
2、复制可变数据类型(list、dict)
- 第一种情况:复制的对象没有复杂的子对象,原对象的值的改变不会影响浅拷贝的对象的值,原对象的地址与浅拷贝对象的地址也不同;反之,浅拷贝的值改变也不会影响原对象的值。
import copy
list1 = [1, 2, 3, 4]
a = copy.copy(list1)
print("修改前的list1:", list1)
print("list1原地址:", id(list1))
print("list1的浅拷贝地址a:", id(a))
print("============修改原对象的值===================")
list1[0] = 5
print("修改后的list1:", list1)
print("list1修改后的地址:", id(list1))
print("修改后的list1,浅拷贝的a:", a)
print("list1修改后的浅拷贝地址a:", id(a))
'''
输出结果:
修改前的list1: [1, 2, 3, 4]
list1原地址: 2211829200704
list1的浅拷贝地址a: 2211829200960
============修改原对象的值===================
修改后的list1: [5, 2, 3, 4]
list1修改后的地址: 2211829200704
修改后的list1,浅拷贝的a: [1, 2, 3, 4]
list1修改后的浅拷贝地址a: 2211829200960
'''
- 第二种情况:复制的对象中有复杂的子对象,修改子对象中的值(例如列表中的一个子元素是一个列表),原对象的值的改变,浅拷贝对象中的值也跟着改变,会影响浅拷贝的值;原对象的地址与浅拷贝对象的地址不同。
import copy
list1 = [1, 2, [3, 4]]
a = copy.copy(list1)
print("修改前的list1:", list1)
print("list1原地址:", id(list1))
print("list1的浅拷贝地址a:", id(a))
print("============修改原对象的值===================")
list1[2][0] = 5
print("修改后的list1:", list1)
print("list1修改后的地址:", id(list1))
print("修改后的list1,浅拷贝的a:", a)
print("list1修改后的浅拷贝地址a:", id(a))
'''
输出结果:
修改前的list1: [1, 2, [3, 4]]
list1原地址: 2095976298624
list1的浅拷贝地址a: 2095976214720
============修改原对象的值===================
修改后的list1: [1, 2, [5, 4]]
list1修改后的地址: 2095976298624
修改后的list1,浅拷贝的a: [1, 2, [5, 4]]
list1修改后的浅拷贝地址a: 2095976214720
'''
二、deepcopy - 深拷贝
深拷贝是拷贝了原始对象的值并开辟了新的内存地址,新对象与原始对象是完全独立,包括内层和外层列表,原对象的值的改变不会引起新对象的值的改变。
import copy
list1 = [1, 2, [3, 4]]
b = copy.deepcopy(list1)
print("修改前的list1:", list1)
print("list1原地址:", id(list1))
print("list1的深拷贝地址b:", id(b))
print("============修改原对象的值===================")
list1[2][0] = 5
print("修改后的list1:", list1)
print("list1修改后的地址:", id(list1))
print("修改后的list1,深拷贝的a:", b)
print("list1修改后的深拷贝地址a:", id(b))
'''
输出结果:
修改前的list1: [1, 2, [3, 4]]
list1原地址: 2081314191424
list1的深拷贝地址b: 2081314191744
============修改原对象的值===================
修改后的list1: [1, 2, [5, 4]]
list1修改后的地址: 2081314191424
修改后的list1,深拷贝的a: [1, 2, [3, 4]]
list1修改后的深拷贝地址a: 2081314191744
'''
24. 文件操作 read readline readlines 有什么区别,他们返回值是什么?
- read:
使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中的所有数据。
- readline
readline一次读取一行
- readlines
就像read没有参数时一样,readlines可以按照行的方式把整个文件中的内容进行一次性的读取,并且返回的是一个列表,其中每一行的数据为一个元素
25. Python3.5 中的await async关键字有什么用?
26. Python垃圾回收是怎么做的?
Python解释器对正在使用的对象保持计数,当对象不再被引用指向的时候,回收器可以释放该对象,获取分配的内存
从基本原理上,当Python的某个对象的引用计数降为0的时候,说明没有任何引用指向该对象.该对象可以被回收了.
比如新建一个对象,他被分配给某个引用,对象的引用计数为1.如果引用被删除,对象的引用计数为0.那么可以被垃圾回收
何时垃圾回收
垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。如果内存中的对象不多,就没有必要总启动垃圾回收。所以,Python只会在特定条件下,自动启动垃圾回收。当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
可以使用gc模块的get_threshold()方法查看该阈值
27 Redis的了解
类型
- string:字符串
- hash:散列
- list:列表
- set:集合
- sorted set:有序集合
常用方法:
- set key value (设置键 值)
- get key (获取key的值)
- expire key 时间(秒数)
- PERSIST 命令可以移除一个键的过期时间: expire的反命令 persist key
redis为啥这么快
- redis是基于内存的,内存的读写速度非常快
- redis是单线程的.省去了很多上下文切换线程的时间(上下文切换是指CPU在多线程之间轮流执行,抢占CPU资源,而redis是单线程的,因此避免了繁琐的多线程上下文切换)
- redis使用多路复用技术,可以处理并发的连接
28 Mysql 的事务性
- 原子性:原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚.因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有如何影响
- 一致性 :一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。举例来说,假设用户A和用户B两者的钱加起来一共是1000,那么不管A和B之间如何转账、转几次账,事务结束后两个用户的钱相加起来应该还得是1000,这就是事务的一致性。
- 隔离性:隔离性是当多个用户并发访问数据库时,比如同时操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
- 持久性 持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
29 如何理解restful 以及restful的缺点
restful是一种标准,规范.准守rest开发的接口通用,便于调用者理解接口的作用
- 面向资源,每个url地址都是一个资源
- 每个URL,可以有多种请求方式,GET/POST/DELETE/PUT(CRUD post–create,get–read,put–update,delete–delete)
- URL里不要含有动词
- 轻量,一般使用xml,json进行处理
- 最常见的一种设计错误,就是URI包含动词。因为"资源"表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中
restful和no restful对比
restful: 给用户一个url,根据method不同在后端做不同的处理,比如:post 创建数据、get获取数据、put和patch修改数据、delete删除数据。
no rest: 给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/
优点:
面向资源.对URL进行了限制,这样看起来比较好理解.尤其是对简单的对象的增删改查.很好理解
缺点:
因为上面的种种限制,导致URL有时候会变得很复杂.
是因为这种限制,导致设计uri变得复杂了。尤其是复杂的关系,操作,资源集合,
特别是复杂关系,操作,资源的时候
30 如何用列表实现队列和栈
- 列表实现队列
队列是一种先进先出的数据结构,也就是从里面取数据时会按照存数据的数据来取数据。而python要实现它的话就只能够通过语法来操作了,示例如下:
queue = []
queue.insert(0,1)
queue.insert(0,2)
print("取一个元素:",queue.pop())
- 列表实现栈
而栈而是和队列相反的一个数据结构,它所遵循的原则是后进先出。也就是每次添加元素的时候都需要将元素放在列表的最后面,这样在取列表元素时就能够将最后添加的元素给最先取出来了。而想要每次将列表元素放在最后面的话用append()方法添加元素即可,示例如下:
stack = []
stack.append(1)
stack.append(2)
print("取一个元素:",stack.pop())
31 链表和列表的区别
在Python中,列表和链表都是常用的数据结构。它们的主要区别在于内存分配和访问元素的方式。
- 列表是一种基于数组实现的数据结构,它在内存中是连续存储的,因此可以通过索引快速访问元素。
- 链表则是一种基于指针实现的数据结构,它在内存中是离散存储的,每个元素都包含一个指向下一个元素的指针,因此访问元素的时间复杂度为O(n)
链表和数组是常见的两种数据结构,它们之间的主要区别如下:
-
存储方式:数组是一种连续的内存块,其中的每个元素在内存中都是相邻的,可以通过下标来快速访问每个元素。而链表则是由一系列的节点组成,每个节点都包含一个元素和指向下一个节点的指针,它们在内存中是不连续的。
-
插入和删除操作的效率:对于数组,插入或删除一个元素可能会导致其他元素的位置发生改变,需要移动其他元素,这会造成时间的浪费。而链表在插入或删除一个元素时,只需要修改相应节点的指针即可,不需要移动其他节点,因此效率更高。
= 访问元素的效率:对于数组,由于元素是连续存储的,可以通过下标快速访问任何一个元素,时间复杂度为 O(1)。而链表需要从头节点开始遍历到目标节点才能访问它,时间复杂度为 O(n),其中 n 是链表的长度。
- 空间复杂度:对于同样大小的数据集合,数组通常需要更少的内存空间,因为它们不需要为每个元素额外存储指针。而链表需要为每个节点额外存储指针,因此需要更多的内存空间。
综上所述,数组适合于需要随机访问元素的情况,而链表适合于需要频繁插入和删除元素的情况。在实际应用中,通常根据具体的需求来选择合适的数据结构
32 分析顺序链表和顺序列表的插入
顺序链表和顺序列表的插入操作有一些不同。
-
顺序列表是通过数组实现的,它的元素在内存中是连续存放的。当我们想要在顺序列表中插入一个元素时,需要先将插入位置后面的所有元素往后移动一位,然后将要插入的元素放到插入位置上。这个操作的时间复杂度为O(n),因为后面的元素都需要往后移动一位。
-
顺序链表是通过链表实现的,它的元素在内存中不一定是连续存放的。当我们想要在顺序链表中插入一个元素时,只需要找到插入位置的前一个节点,然后将新元素插入到该节点之后即可。这个操作的时间复杂度为O(1),因为我们只需要修改节点的指针即可,不需要像顺序列表那样移动其他元素。
综上所述,顺序链表的插入操作比顺序列表更加高效,特别是在插入大量元素时。但是顺序链表的缺点是不能随机访问,只能从头节点开始遍历整个链表,因此在查找元素时效率较低。
33 输入一个ip地址,到你看到内容,其间经历的过程
当你输入一个IP地址后,以下是一般情况下数据传输的大致过程:
-
DNS解析:输入的域名需要先经过DNS服务器解析,找到对应的IP地址。
-
建立TCP连接:客户端通过三次握手和服务器建立TCP连接。三次握手包括客户端发送SYN(同步)信号,服务器接收并返回SYN-ACK(同步确认)信号,客户端再发送ACK(确认)信号。
-
发送HTTP请求:客户端向服务器发送HTTP请求,请求的内容包括请求方法、请求URL、请求头等信息。
-
服务器处理请求并返回HTTP响应:服务器接收到HTTP请求后,会处理请求,然后向客户端返回HTTP响应,响应的内容包括响应状态码、响应头、响应体等信息。
-
关闭TCP连接:当客户端接收完响应后,会关闭TCP连接。关闭连接时,客户端发送FIN(结束)信号,服务器返回ACK信号,然后服务器发送FIN信号,客户端返回ACK信号,连接关闭。
-
显示网页内容:客户端收到HTTP响应后,会根据响应的内容解析和显示网页内容。
总的来说,以上过程可以用下面的步骤总结:
DNS解析 → 建立TCP连接 → 发送HTTP请求 → 服务器处理请求并返回HTTP响应 → 关闭TCP连接 → 显示网页内容
35 网络知识
1 HTTP 和 HTTPS 的区别
- HTTP协议以明文方式发送内容,不提供任何方式的数据加密。HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
- https则是具有安全性的ssl加密传输协议。http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。并且https协议需要到ca申请证书。HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
2 TCP 和 UDP的区别
都是负责提供 端到端通信的传输层协议
- TCP 是面向连接的
- UDP 是无连接协议
TCP 定义:
是TCP/IP模型中传输层协议,面向连接、可靠的字节流服务
三次握手连接和四次挥手断开连接
UDP定义:
是TCP/IP模型中传输层的无连接协议。通常用于音频和文件
arp 协议
定义:
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址(Mac地址)的一个TCP/IP协议
36
34 杂七杂八
- name
class Person:
def __init__(self):
pass
def getAge(self):
return __name__
p = Person()
print(p.getAge()) # __main__
print(Person.__name__) # Person
- 一行代码实现9*9乘法表
print('\n'.join([' '.join([f'{j}*{i}={i*j}' for j in range(1, i+1)]) for i in range(1, 10)]))
二 python 机试
1 有效的括号
https://leetcode.cn/problems/valid-parentheses/description/
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = “()”
输出:true
示例 2:
输入:s = “()[]{}”
输出:true
示例 3:
输入:s = “(]”
输出:false
class Solution:
def isValid(self, s: str) -> bool:
dic = {
')':'(',
']':'[',
'}':'{'
}
stack = []
for i in s:
if stack and i in dic:
if stack[-1] == dic[i]:
stack.pop()
else:
return False
else:
stack.append(i)
if not stack:
return True
else:
return False
2 计算输入的日期是当年的第几天
from functools import reduce
year, month, day = 2023, 3, 7
# 平年每月天数
month_day = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
sumDay = 0
# 如果是闰年就更新2月天数
if (int(year) % 4 == 0 and int(year) % 100 != 0) or int(year) % 400 == 0:
month_day[1] = 29
day_count = reduce(lambda x, y: x + y, month_day[:month-1])
print(day_count+day)
3 列出所有的质数
任意输入两个数,求出这个范围内所有的质数(素数)
素数是指只有1和它本身两个因数,,比如 19 只有 1 和19 两个因数,所以19 是素数
例如:
输入 10 20
输出: 11 13 17 19
def get_prime_number(a, b):
for i in range(a, b):
flag = True
for j in range(2, i):
if i % j == 0:
flag = False
break
if flag:
print(i)
get_prime_number(10, 20) # 11 13 17 19
4 斐波那契数列
—有一对兔子,从出生后的第3个月起每个月都生一对兔子。
小兔子长到第3个月后每个月又生一对兔子,假设所有的兔子都不死,求解每个月的兔子总对数数量?
f(n) = a(n-1) + a(n-2)
# 使用递归的方法实现
month = eval(input('请输入月份'))
def f(month):
if month == 1 or month == 2:
return 1
else:
return f(month - 2) + f(month - 1)
print(f(month))
5 连续数组的求和
Leetcode 209 题
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, …, numsr-1, numsr] ,
并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
'''
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,
并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
'''
'''自己写的,但是超时了'''
class Solution:
def minSubArrayLen(self, target, nums):
if target in nums:
return 1
elif sum(nums) < target:
return 0
else:
res_list = nums
for i in range(len(nums)):
j = i
res = 0
temp_list = []
while res < target and j < len(nums):
res += nums[j]
temp_list.append(nums[j])
j += 1
if res >= target:
if len(temp_list) < len(res_list):
res_list = []
res_list.extend(temp_list)
return len(res_list)
target = 7
nums = [2, 3, 1, 2, 4, 3]
print(Solution().minSubArrayLen(target, nums))
# class Solution:
# def minSubArrayLen(self, s, nums):
# # 定义一个无限大的数
# res = float("inf")
# Sum = 0
# index = 0
# for i in range(len(nums)):
# Sum += nums[i]
# while Sum >= s:
# res = min(res, i - index + 1)
# Sum -= nums[index]
# index += 1
# return 0 if res == float("inf") else res
#
#
# target = 11
# nums = [1, 2, 3, 4, 5]
#
# print(Solution().minSubArrayLen(target, nums))
# class Solution:
# def minSubArrayLen(self, target: int, nums: List[int]) -> int:
# left, right = 0, 0
# total = 0
# res = float('inf')
# while right < len(nums):
# total += nums[right]
# right += 1
# while total >= target:
# res = min(res, right - left)
# total -= nums[left]
# left += 1
#
# if res == float('inf'):
# return 0
# return res
















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









