







本文主要介绍MYSQL的逻辑架构和查询过程(数据库大多数都是读多写少,这里只关注查询过程,不讨论数据插入、更新等其他过程)
MYSQL逻辑架构

mysql逻辑架构分为三层:
1、客户端:连接处理、授权认证、安全等功能(常见的登录、连接数据库之类的操作)。
2、核心服务:查询缓存、解析、优化、执行计划、API调用存储引擎(API屏蔽了不同存储引擎间的差异)都在这一层。
3、存储引擎:存储引擎负责MySQL中的数据存储和读取,核心服务层通过API与存储引擎通信。
MYSQL查询过程
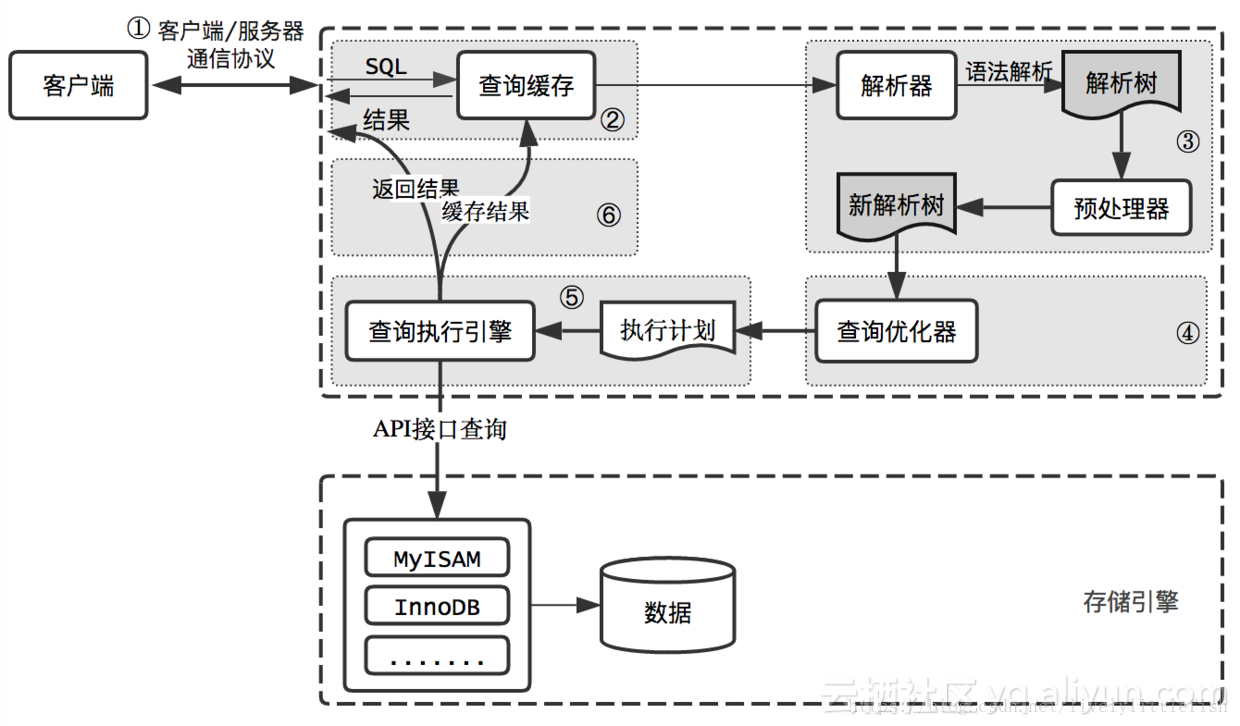
MySQL查询过程如下:
- 客户端将查询发送到MySQL服务器
- 服务器先检查查询缓存,如果命中,立即返回缓存中的结果;否则进入下一阶段
- 服务器对SQL进行解析、预处理,再由优化器生成对象的执行计划
- MySQL根据优化器生成的执行计划,调用存储引擎API来执行查询
- 服务器将结果返回给客户端,同时缓存查询结果
下面细讲每个流程。
客户端/服务端通信协议
客户端用一个单独的数据包将查询请求发送给服务器,而服务器响应给用户的数据通常会很多,由多个数据包组成,而且客户端必须完整的接收整个返回结果,不能简单的只取前面几条结果,然后让服务器停止发送。
因此在实际开发中应该尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量,比如
- 尽量避免使用
SELECT *,只取需要用到的列 - 如果只需要用到少量的数据,应该加上LIMIT限制
查询缓存
如果查询缓存是打开的( mysql默认打开查询缓存),那么MYSQL会首先检查这个查询语句是否命中查询缓存
- 命中查询缓存:检查一次用户权限后直接返回缓存中。这种情况下,查询不会被解析,也不会生成执行计划,更不会执行。
- 不命中查询缓存:解析、优化、生成执行计划、执行。
MySQL将缓存存放在一个引用表中(类似于HashMap的数据结构),通过计算哈希值来进行索引,这个哈希值通过查询语句本身、当前要查询的数据库、客户端协议版本号等信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql库中的系统表,其查询结果都不会被缓存,因为将这样的查询结果缓存起来没有任何的意义。比如
- 函数
NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果 - 包含
CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果
缓存失效
所有缓存都需要有失效机制,以防止无效的缓存一直占用内存空间。
MySQL会跟踪查询中涉及的每个表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。(mysql不会去分析这个改动是否影响到这个缓存,而是一刀切直接删除相关的缓存,以节省服务器性能)如果查询缓存非常多,写操作就可能带来很大的系统消耗。如果写操作很频繁,那么MYSQL将会浪费大量的系统资源在删除旧的查询缓存、保存新的查询缓存上。
因此查询缓存适合有大量相同查询的应用,不适合有大量数据更新的应用。
优化方法
根据上面提到的mysql缓存机制,可以提出一些优化方法(都需要根据实际业务场景选用):
- 对于写操作频繁的业务场景,关闭mysql的查询缓存。
- 如果部分表写操作频繁,部分表写操作很少,可以不关闭mysql的查询缓存,而是通过
SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存(读经常更新的表的查询语句不缓存,读不经常更新的表的查询语句缓存)。 - 如果数据表中只有一小部分字段的值经常被更新,而且大部分查询语句不需要用到这些经常被更新的字段,可以考虑拆分数据表。(注意不要过度设计,要根据实际情况衡量是否值得这么做)
SQL解析和预处理
SQL解析的作用是将一个输入的‘字符串’变换为一个描述这个字符串的‘结构体’,让计算机可以更容易的理解用户输入的字符串是什么意义。这个阶段包含三个过程,分别是词法分析、语法分析、输出抽象语法树。
SQL解析属于编译器范畴,和C等其他语言的解析没有本质的区别,不同的是其他编程语言解析编译得到的是二进制可执行文件,SQL解析得到的是一棵语法树。
词法分析
通常情况下,词法分析可以使用Flex来生成,但MySQL没有使用Flex,而是自己实现了词法分析。
词法分析主要是把输入转化成一个个Token,其中Token中包含Keyword(也称symbol)和非Keyword。例如,SQL语句select username from userinfo,在词法分析之后,会得到4个Token:
| 关键字 | 非关键字 | 关键字 | 非关键字 |
|---|---|---|---|
| select | username | from | userinfo |
词法分析的结果会作为语法分析的输入。
语法分析
语法分析就是生成语法树的过程,MySQL使用了Bison来完成语法分析。例子
select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1
生成语法树

生成语法树的过程中会检查SQL语句中是否使用了错误的关键字或者关键字的顺序是否正确等等
预处理
在预处理其中,进一步解析语法树是否合法并生成一棵新的语法树。例如:检查数据表和数据列是否存在,SQL语句的名字和别名是否有歧义,之后预处理器还会校验用户权限(权限校验一般会很快,除非服务器上有非常多的权限设置)
执行计划
经过前面的步骤生成一棵合法的语法树后,查询优化器会将语法树转换成执行计划。一般一条查询语句可以由多种执行计划完成,优化器尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。
使用explain命令可以查看MYSQL所选择的执行计划
mysql> explain select name, nickname, ctime from dt_user where city = 'shanghai' order by name;
+----+-------------+------------+-------+--------------------------+---------------+---------+--------+---------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+--------------------------+---------------+---------+--------+---------+-----------------------+
| 1 | SIMPLE | dt_user | range | PRIMARY,idx_city_name | idx_city_name | 2945 | NULL | 55183 | Using index condition |
+----+-------------+------------+-------+--------------------------+---------------+---------+--------+---------+-----------------------+
1 row in set (0.00 sec)
如上面这个例子,rows = 55183 代表该执行计划需要扫描55183行记录,possible_keys代表可能用到主键和idx_city_name索引等等。
执行
找到最优的执行计划以后,MySQL调用查询执行引擎(InnoDB、MyISAM)在磁盘中读取数据,最后将查询结果返回给客户端,而且如果该查询是符合缓存条件的(比如不包含NOW()之类的东西),也会把查询结果保存到查询缓存中。
性能优化方法
数据类型优化
选择数据类型要遵循小而简单的原则,越小的数据类型通常会更快,占用更少的内存和磁盘,处理时需要的CPU周期也更少。比如很多人喜欢用字符串(varchar)来存储各种数据,但很多数据实际上可以用整型来存储的,而整型就比字符串成本低,MySQL 中的整型类型(没有无符号整型):
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| TINYINT | 很小的整数 | 1个字节 |
| SMALLINT | 小的整数 | 2个宇节 |
| MEDIUMINT | 中等大小的整数 | 3个字节 |
| INT (INTEGHR) | 普通大小的整数 | 4个字节 |
| BIGINT | 大整数 | 8个字节 |
1、使用整型来存储ip地址
IP地址是一个32位的2进制数,IP的格式是A.B.C.D,其中A,B,C,D均为0~255内的整数,例如127.0.0.1。可以字符串类型的IP地址转化为一个BIGINT整数存到数据库里面。
同样存储一个IP地址192.168.53.6,varchar类型需要占用12B(每个字符是一个char,占用1B),BIGINT类型只需要8B。
2、使用DATETIME来存储时间,DATETIME类型占用5个字节,其形式为YYYY-MM-DD HH:MM:SS,如果用字符串来存储同样的形式,占用的空间会大得多。
高性能索引
索引是提高MySQL查询性能的一个重要途径,但过多的索引可能会导致过高的磁盘使用率和内存占用,从而影响应用程序的整体性能,如何创建合适的索引也是一门学问。
简单回顾一下,以存储引擎InnoDB为例,InnoDB无论主键索引还是辅助索引都是用B+树作为索引结构的,如果使用主键索引进行查询,那么查找到叶子结点后就可以直接拿到所需的数据,而如果使用辅助索引来进行查询,查找到叶子结点时只能拿到对应的主键,然后再拿这个主键到主键索引中查找到叶子结点拿到所需数据,这个步骤叫索引回表。
一个多列索引的例子:
CREATE TABLE People(
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum(`m`,`f`) not null,
key(last_name,first_name,dob)
);

可以看到,索引首先根据第一、二个字段来排列顺序,当名字相同时,则根据第三个字段,即出生日期来排序,正是因为这个原因,才有了索引的“最左原则”。
需要注意的是,使用非主键索引会有索引回表的开销,全表扫描不需要回表,所以有时候可能全表扫描更高效。
下面介绍各种索引的高效使用方法。
MySQL不会使用索引的情况:非独立的列
“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数。比如:
select * from where id + 1 = 5
明明等价于 id = 4,但是MySQL无法自动解析这个表达式,所以没有办法使用id索引,只能全表扫描一遍,逐个判断是否满足该表达式。如果直接写成 id = 4就可以使用索引,查询效率大幅提升。
前缀索引
如果一个列的值都很长,又想要以这个列来构建索引,就会导致索引树占用的空间非常大,这种情况下,通常可以只取一部分足够具有区分性的前缀来构建索引,这样可以有效节约索引空间,从而提高索引效率。以邮箱为例子,email列中,用户名部分的前缀已经足够具有区分性,而后面的@xx.com的一般只有那么几个邮箱,重复性大且没有索引意义,所以可以只取用户名前缀构建索引。
mysql支持前缀索引
alter table User add index index1(email);
alter table User add index index2(email(6));
第一句SQL创建的索引就是将email整个字符串作为索引;第二个SQL语句创建的索引,只取email字符串的前6个字节作为索引。显然后者建立的索引更高效(索引占用空间小,每个磁盘页能放更多索引,树的高度更小,磁盘IO次数更少)。
索引合并
MYSQL5.0以后的版本,当查询语句的条件涉及到多个列,会考虑是否使用索引合并策略。
是OR条件且其中有一个列没有建立索引时,索引会直接失效,直接使用全表扫描(因为没有索引的列必须全表扫描,那其他列就失去了使用索引的意义)
例子
explain SELECT * from t WHERE id = 1 or uid = 2;
执行计划
| id | select_type | table | type | possible_keys | key | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t | index_merge | PRIMARY,uid | PRIMARY,uid | 2 | Using union(PRIMARY,uid); Using where |
这里的type项是index_merge,是MySQL5.0后的新技术,索引合并。索引合并简单说就是在用OR,AND连接的多个查询条件时,可以分别使用这些索引进行查询,
- OR:对各自的结果集取并集
- AND:对各自的结果集取交集
注意使用索引合并有一个必要条件:其主键值需要有序,这样才能对多个结果集(结果集就是主键,要合并主键结果集)进行快速合并,然后再去聚簇索引查找,从而减少从数据表中取数据的次数,提高查询效率。
当然具体是否使用索引合并,优化器会自己评估,对于那些区分度不高的索引,会导致各自使用索引时得到的查询结果集非常大,再取交集或并集时开销非常大,而且再加上索引回表的开销,可能会比全表扫描慢得多,那么mysql就会选择全表扫描的执行计划。
例子
SELECT * FROM TB1 WHERE c1="xxx" AND c2=""xxx"
- 当c1列和c2列选择性较高时,按照c1和c2条件进行查询性能较高且返回数据集较小,再对两个数据量较小的数据集求交集的操作成本也较低,最终整个语句查询高效;
- 当c1列或c2列选择性较差且统计信息不准(导致优化器评估失准)时,比如整表数据量2000万,按照c2列条件返回1500万数据,按照c1列返回1000条数据,此时按照c2列条件进行索引扫描+聚集索引查找的操作成本极高(可能是整表扫描的百倍消耗),对1000条数据和1500万数据求交集的成本也极高,最终导致整条SQL需要消耗大量CPU和IO资源且相应时间超长,而如果值使用c1列的索引,查询消耗资源较少且性能较高。
优化建议:如果索引合并的效果并不好(某些列区分度不大),可以考虑建立多列索引,而不是为各个列建立单独的索引。或者说,当发现执行计划使用了索引合并的时候,说明此时都已经需要mysql去考虑用索引合并来进行优化,可以认为这说明了索引建的很糟糕,需要进行优化了。
多列索引的索引顺序
当我们选择建立多列索引的时候,也需要考虑建立索引时列顺序的问题。索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列等等。参考上面的多列索引的图
《高性能MySQL》一书中提到的一个经验法则:将选择性最高的列放到索引最前列,这样建立起来的索引树,查询时速度更快。
这句话有点人云亦云的感觉了,也没有人能解释明白为什么应该将选择性最高的列放到索引最前列,我感觉这个原则只适用于寻找确定的数据的情况(where条件子句里同时对这几个列都有确定的值的要求),这种情况下将选择性最高的列放到索引最前列,那么在B+树里进行比较时比较次数少一点(如果选择性低的列放在索引最前列,每次都会先对比这个列,浪费对比速度)。但是实话说这种优化其实作用非常小,聊胜于无的感觉。
考虑索引顺序的最关键的原因应该是索引的最左匹配原则。
参考Does Order of Fields of Multi-Column Index in MySQL Matter
比如这两个索引:
create index idx_lf on name(last_name, first_name);
create index idx_fl on name(first_name, last_name);
对于这个条件子句的作用是一模一样的
where last_name = XXX and first_name = YYY
对于以下这些情况,idx_lf效果更好
where last_name = XXX
where last_name like 'X%'
where last_name = XXX and first_name like 'Y%'
where last_name = XXX order by first_name
对于以下这些情况,idx_fl效果更好
where first_name = YYY
where first_name like 'Y%'
where first_name = YYY and last_name like 'X%'
where first_name = XXX order by last_name
使用索引扫描来排序
MySQL有两种方式可以生产有序的结果集
- 对结果集进行排序的操作
- 按照索引顺序扫描得出的结果自然是有序的。
如果explain的结果中type列的值为index表示使用了索引扫描来做排序。使用索引扫描来排序需要考虑很多前提条件,在满足这些条件的情况下,使用索引扫描来排序的效率才会比全表扫描高,这种情况下执行计划才会使用索引扫描来排序,具体参考8.2.1.16 ORDER BY Optimization
覆盖索引
如果一个索引包含或者说覆盖所有需要查询的字段的值,那么索引的叶子节点中已经包含要查询的数据,也就没有必要再回表查询,这就称为覆盖索引。覆盖索引可以极大的提高性能:
- 索引条目远小于数据行大小,如果只读取索引,极大减少数据访问量
- 索引是有按照列值顺序存储的,对于I/O密集型的范围查询要比随机从磁盘读取每一行数据的IO要少的多
管理索引
冗余索引是指在相同的列上按照相同的顺序创建的相同类型的索引,应当尽量避免这种索引,发现后立即删除。比如有一个索引(A,B),再创建索引(A)就是冗余索引。
此外,定期删除一些长时间未使用过的索引是一个非常好的习惯,不仅可以节省磁盘空间,而且也可以节省执行写语句时维护索引所导致的开销。
其他优化
优化关联查询
首先看MySQL是如何执行关联查询的。当前MySQL关联执行的策略非常简单,它对任何的关联都执行嵌套循环关联操作,即先在一个表中循环取出单条数据,然后在嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为为止。然后根据各个表匹配的行,返回查询中需要的各个列。
例子
SELECT A.xx,B.yy
FROM A INNER JOIN B USING(c)
WHERE A.xx IN (5,6)
假设MySQL按照查询中的关联顺序A、B来进行关联操作,那么可以用下面的伪代码表示MySQL如何完成这个查询:
outer_iterator = SELECT A.xx,A.c FROM A WHERE A.xx IN (5,6);
outer_row = outer_iterator.next;
while(outer_row) {
inner_iterator = SELECT B.yy FROM B WHERE B.c = outer_row.c;
inner_row = inner_iterator.next;
while(inner_row) {
output[inner_row.yy,outer_row.xx];
inner_row = inner_iterator.next;
}
outer_row = outer_iterator.next;
}
可以看到,外层首先查询出A表中所有满足A.xx IN (5,6)的数据行,因此A表应该创建xx列的索引,而不需要创建c列的索引(反正用不上)。内层会根据A表查询出的数据行,取出c列的值去B表中查询出c列值相同的数据行,因此B表中应该创建c列的索引,这样可以加快内层查询速度。
优化LIMIT分页
当需要分页操作时,通常会使用LIMIT加上偏移量的办法实现。一个常见的问题是当偏移量非常大的时候,比如:LIMIT 10000 20这样的查询,MySQL需要查询10020条记录然后只返回20条记录,前面的10000条都将被抛弃,这样的代价非常高。
是否可以跳过10000条数据然后读取20条,而不是读取10020条数据然后返回20条数据呢?
原SQL语句:
select * from t order by id limit 10000,20
改进后的SQL语句如下(假设id是主键索引):
select * from t where id >= (select id from t order by id limit 10000,1) limit 20
可见,首先是内层是在主键索引树上查出排第10000的id,然后在外层从大于这个id的数据行中取20个出来直接返回,那么内层走的是索引,外层也是走的索引,所以性能大大提高。















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









