







系列文章目录
前言
本文主要记录pandas中缺失值异常值相关的api使用:
通过对真实数据的一系列操作帮助我们熟练掌握相关api的使用。
提示:以下是本篇文章正文内容,下面案例可供参考
1.引入库
代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下:
data = pd.read_csv('LJdata.csv')
如果需要该处使用的数据,请私信我。
3.数据基本信息查询
我们在理解DataFrame时要类比Excel表格,可以帮助我们更清晰的分析
在DataFrame中,我更倾向于叫一行为样本或者记录,叫一列为特征或者属性
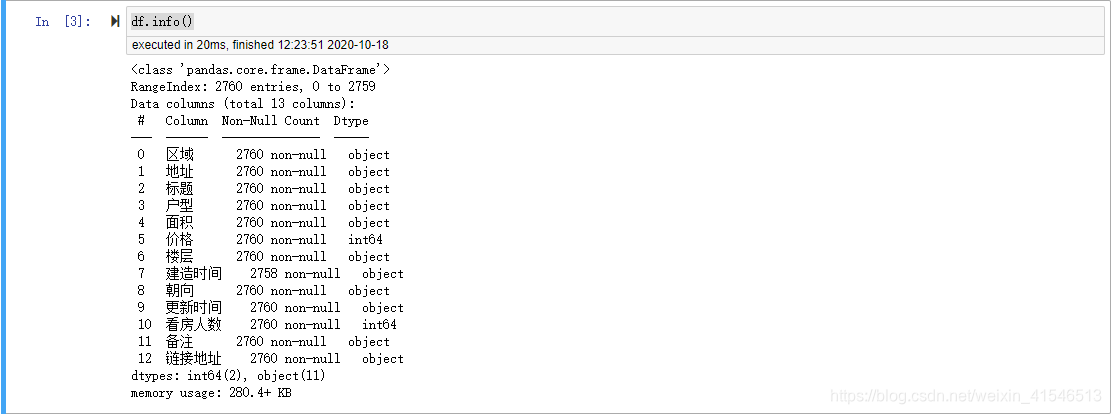
df.info()
结果
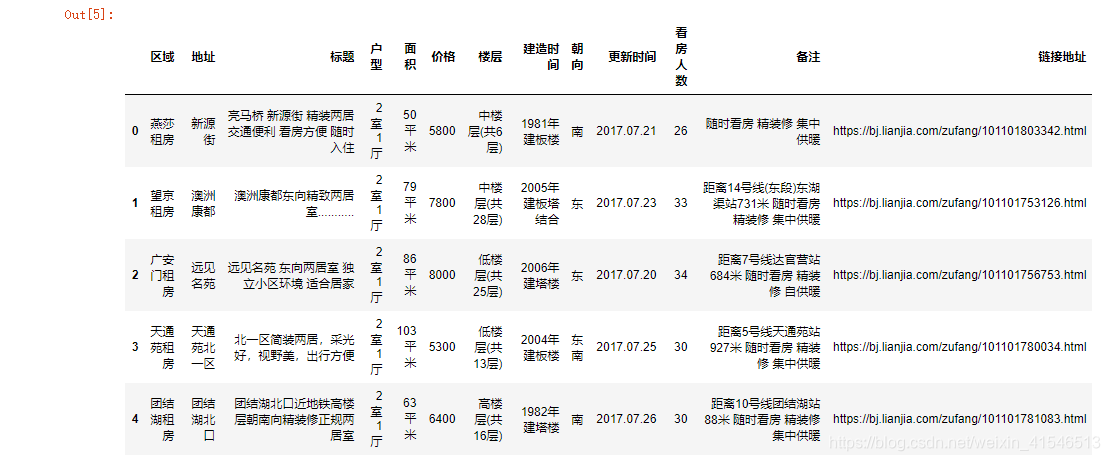
- 数据前5行
df.head()
结果
4.缺失值相关api
- 首先判断是否有缺失值的存在
我们在基础信息中发现,整个数据集一共2760行,其中建造时间一列只有2758个非空值,说明这一列存在缺失值。
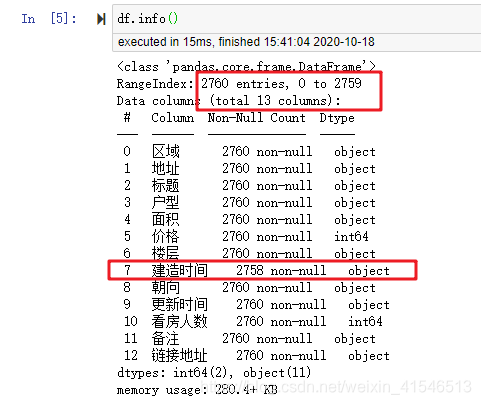
- 缺失值的类型
我们的数据集中缺失值一般显示NaN,它是numpy中的类型,是float类型
import numpy as np
type(np.nan)
# 结果
float
- 缺失值的位置
确定缺失值在哪一行那一列
pandas提供了四种方式判断缺失值,两种是判断是不是缺失(isna,isnull),另外两种是判断是不是非缺失值(notna,notnull)
一种是isna方法
df['建造时间'].isna()
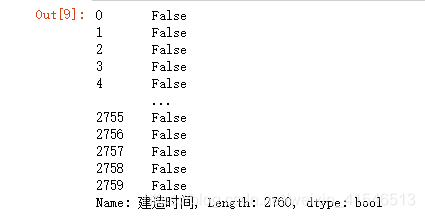
返回值是bool类型的,由于 jupyter notebook中只显示前5行和后五行,我们并不能看到缺失值的位置,但是我们可以根据结果筛选出缺失值所在的行
df[df['建造时间'].isna()]

可以很明确的看到,993行 和 1749 行的 建造时间显示为NaN,也就是缺失值。
isnull方法与isna方法用法一致,返回的结果也一致,那么为什么会存在两种方法呢,isna判断的是 缺失值是不是np.nan,isnull判断的是 缺失值是不是python的None,两者的类型不一样,no.nan是float类型,但是None是NoneType类型,但是在pandas中其实并没有太大的区别,所以使用哪一个都可以。
type(None),type(np.nan)
# 结果
(NoneType, float)
df[df['建造时间'].isnull()]

判断非缺失值得方法与前面提到的判断缺失值正好相反,notna中,如果是缺失值返回False。
df.notna()
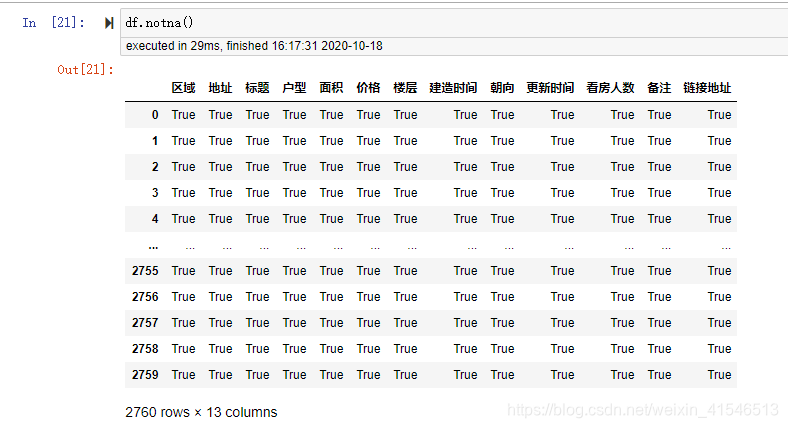
notnull 方法与notna一样,此处不再赘述
df.notnull()
- 缺失值的处理
缺失值的处理无非三种:删除、替换、保留
首先,如果确定缺失值不是我们想要的而且存在缺失值的哪一行失去了意义,那么就可以删除了;
如果存在缺失值的哪一行,缺失值对整条记录影响并不大,而这条记录存在其价值,所以可以用替换或者直接保留,当选择保留时,缺失值也可以作为一种特征。
- 缺失值删除
df.dropna()
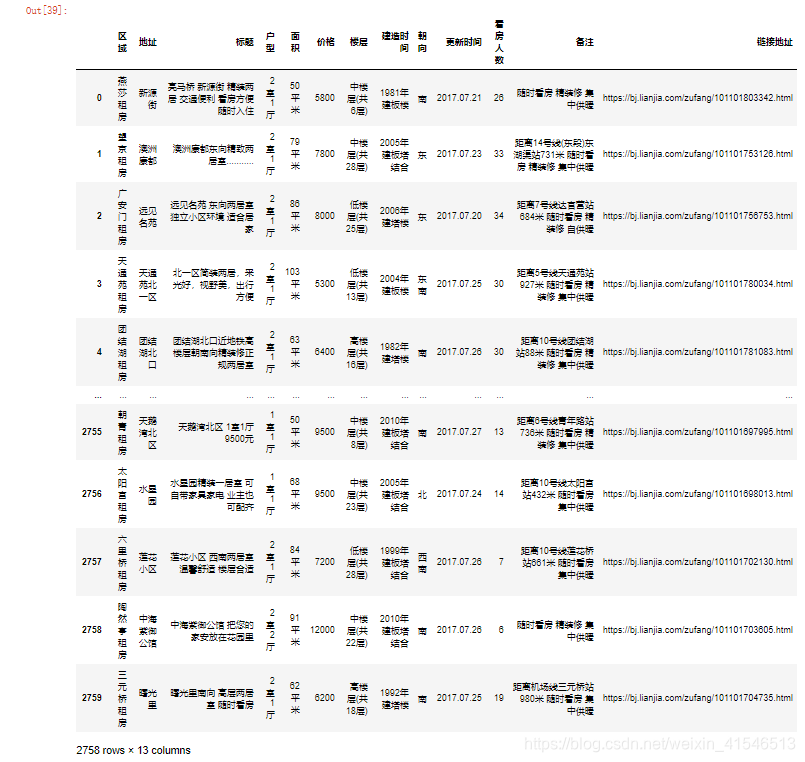
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
dropna有很多参数,axis是按行删除还是按列删除,默认是行;
how是删除的方式,any 只要有一个缺失值就删除, all 整行或整列都是缺失值才删除,默认是any
thresh必须传入int格式,只保留一行中有thresh个缺失值的行;
subset必须是由当前DataFrame的列组成的列表,代表只删除指定列中存在缺失值的记录;
inplace是bool值,Ture代表直接作用于原始DataFrame,不返回对象
- 缺失值替换
缺失值的替换有很多种方法,但是都是replace的衍生或者简化;
在前面已经确认了 993 行 和 1479行存在缺失值,因此可以用来检验
df.replace(
to_replace=None, # 被替换的值
value=None, # 用来替换的值
inplace=False, # 是否直接作用于原数据集
limit=None, # 限制
regex=False, # 是否正则,bool值
method='pad', # 替换方法
)
value、method 值能选一个;
value 是单一值 或者 dict/Series/DataFrame,如果是单一值,所有的缺失值都会被替换成这个值;
如果是Series,则根据缺失值所在的索引替换,如果是DataFrame则会根据列索引替换
method 是替换的方法,可选值有backfill、bfill、pad、ffill、None,默认值是None;
backfill 和 bfill 作用一样,pad 和 ffill作用一致。
backfill / bfill – 用前一个合法值填充
pad / ffill 用后面一个合法值填充
df.replace(np.nan,'111').loc[[993,1749]]

fillna也是replace的简化,将replace方法的to_replace参数设置为np.nan,regex设置为False。其他参数与replace一致。
df.fillna(
value=None, # 用来填充的值
method=None, # 填充方法
axis=None, # 按行 or 按列 0 or index,1 or columns
inplace=False, # 是否直接作用于原原数据集
limit=None, # 限制替换的个数
downcast=None, # 字典,转换类型
)

fill、pad、backfill、bfill 就是fillna方法的进一步简化
df.ffill().loc[[993,1749]]

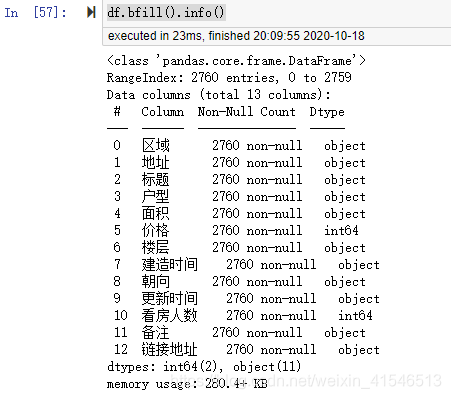
填充后的数据集基础信息
df.bfill().info()
异常值的处理思路一般是转换成缺失值再替换,或者直接替换,用到的方法主要是replace。
总结
代码的功底都是通过不断的练习一步步积累起来的,和我一起学pandas吧!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









