









Spa+LR:Hyperspectral Image Denoising via Sparse Representation and Low-Rank Constraint
引言
HSI去噪方法:SSAHTV,HSSNR,PCA,后两种方法都分别在空间和光谱维度上考虑RAC。作为高维数据,HSI的不同维度之间存在相关性。
在稀疏表示框架中,可以通过利用图像中的RAC来学习字典。无噪声图像可以用字典的原子稀疏地近似,而有噪声的图像由于噪声的随机性质不能稀疏地近似。使用原子或基的线性组合来估计去噪图像。高度相关的图像集具有低秩的性质;通过使用低秩的限制,可以从具有噪声或异常值的测量中有效地恢复它们。
基础理论
噪声模型: Y = X + w Y=X+w Y=X+w,其中 X , Y , w ∈ R M × N X,Y,w\in R^{M\times N} X,Y,w∈RM×N,由于不适定(ill-posed)性,使用 L 2 L_2 L2保真度约束的解( X ^ = arg min X ∥ Y − X ∥ 2 2 \hat{X}=\arg \min _{X}\|Y-X\|_{2}^{2} X^=argminX∥Y−X∥22)一般不唯一。为了找到更好的解决方案,需要利用理想图像的先验知识来正则化去噪问题。
图像可以稀疏地表示为固定的形式,如离散余弦变换、小波基或使用从图像本身学习的字典原子。用 D D D表示字典,我们有 X ≈ D α X\approx D\alpha X≈Dα, α \alpha α中的大部分系数都接近于零。利用稀疏先验,可以通过求解以下 L 0 L_0 L0最小化问题,从Y中估计出D上的X的表示: { D , α ^ } = arg min D , α ∥ Y − D α ∥ 2 2 + η ∥ α ∥ 0 \{D, \hat{\alpha}\}=\arg \min _{D, \alpha}\|Y-D \alpha\|_{2}^{2}+\eta\|\alpha\|_{0} {D,α^}=argD,αmin∥Y−Dα∥22+η∥α∥0
参数 η \eta η控制数据拟合项和稀疏项之间的权衡。上述解可以用交替优化来实现,即先固定D解α,再固定α解D。求解α的第一阶段称为稀疏编码,求解D的第二阶段称为字典学习。 L 1 L_1 L1最小化作为最接近 L 0 L_0 L0最小化的凸函数,被广泛用作解决 L 0 L_0 L0最小化问题的替代方法 { D , α ^ } = arg min D , α ∥ Y − D α ∥ 2 2 + η ∥ α ∥ 1 \{D, \hat{\alpha}\}=\arg \min _{D, \alpha}\|Y-D \alpha\|_{2}^{2}+\eta\|\alpha\|_{1} {D,α^}=argD,αmin∥Y−Dα∥22+η∥α∥1
用 L 1 L_1 L1范数代替 L 0 L_0 L0范数可以保证解的唯一性。稀疏表示可以抑制噪声,原因有几个。
- 首先,信号可以用很少的原子来表示,而噪声不能。
- 第二,字典学习将在一定程度上拒绝噪声,尽管它是使用噪声信号或图像训练的。
- 第三,稀疏编码,例如正交匹配追踪(OMP)方法,在表示误差达到预定的小值时停止,以便不重构噪声。
方法
Rank Analysis of Clean and Noisy HSI
假设HSI遵循线性混合模型,它可以表示为 X = A S X=AS X=AS,其中 X ∈ R M N × L X\in\mathbb{R}^{MN\times L} X∈RMN×L为HSI, S ∈ R P × L = [ s 1 , s 2 , ⋯ , s P ] T S\in\mathbb{R}^{P\times L}=[s_1,s_2,\cdots,s_P]^T S∈RP×L=[s1,s2,⋯,sP]T为端元矩阵, s i ∈ R L s_i\in\mathbb{R}^L si∈RL, A ∈ R M N × P A\in\mathbb{R}^{MN\times P} A∈RMN×P为abundance矩阵,元素 a i , j a_{i,j} ai,j表示第 i i i个像素中光谱响应的第 j j j个端元的fractional abundance. 大多数情况下, P ≪ m i n ( M N , L ) P\ll min(MN,L) P≪min(MN,L),因此 r a n k ( X ) ≤ m i n ( r a n k ( A ) , r a n k ( S ) ) ≤ P ≪ m i n ( M N , L ) rank(X)\leq min(rank(A),rank(S))\leq P\ll min(MN,L) rank(X)≤min(rank(A),rank(S))≤P≪min(MN,L)
干净的HSI的秩远远小于HSI的大小。对于noisy HSI Y Y Y, W W W为高斯噪声,则有 Y = X + W = A S + W Y=X+W=AS+W Y=X+W=AS+W,由于噪声的随机性,不同波段的噪声分量之间没有相关性。噪声分量 W W W的秩通常是满的 r a n k ( W ) = m i n ( M N , L ) ≫ r a n k ( X ) rank(W)=min(MN,L)\gg rank(X) rank(W)=min(MN,L)≫rank(X)
又 Y = X + W = W − ( − X ) Y=X+W=W-(-X) Y=X+W=W−(−X), Y Y Y的秩满足 r a n k ( Y ) ≥ r a n k ( W ) − r a n k ( X ) ≈ r a n k ( W ) ≫ r a n k ( X ) rank(Y)\geq rank(W)-rank(X)\approx rank(W)\gg rank(X) rank(Y)≥rank(W)−rank(X)≈rank(W)≫rank(X)

数据地址:http://speclab.cr.usgs.gov/spectral.lib06
Local and Global Jointly Denoising
稀疏表示框架中HSI的去噪目标函数可以表示如下: { X , D , α i } = arg min D , X , α i γ ∥ X − Y ∥ 2 2 + ∑ i ∥ R i X − D α i ∥ 2 2 + ∑ i η ∥ α i ∥ 0 ( 1 ) \left\{X, D, \alpha_{i}\right\}=\underset{D, X, \alpha_{i}}{\arg \min } \gamma\|X-Y\|_{2}^{2}+\sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\sum_{i} \eta\left\|\alpha_{i}\right\|_{0}\quad(1) {X,D,αi}=D,X,αiargminγ∥X−Y∥22+i∑∥RiX−Dαi∥22+i∑η∥αi∥0(1)
其中 X , Y ∈ R M × N × L X,Y\in\mathbb{R}^{M\times N\times L} X,Y∈RM×N×L, R i R_i Ri为从 X X X中提取第 i i i个重叠块(patch) R i X R_iX RiX的算子。第一项是数据保真项,其权重 γ \gamma γ取决于噪声的方差,这一项有助于移除块边界上的可见伪影。第二第三项表明,使用字典 D D D中的几个原子,HSI的每个patch都可以用小误差线性表示。
为了有效地去除噪声,需要仔细设计块提取方法。为了避免维数灾难和减少误差,并联合使用空间和光谱信息,通过对每个波段的图像进行矢量化,将三维HSI立方体整形为二维矩阵。然后,从这个矩阵中提取一个二维图像块,它将同时包含空间和光谱信息。
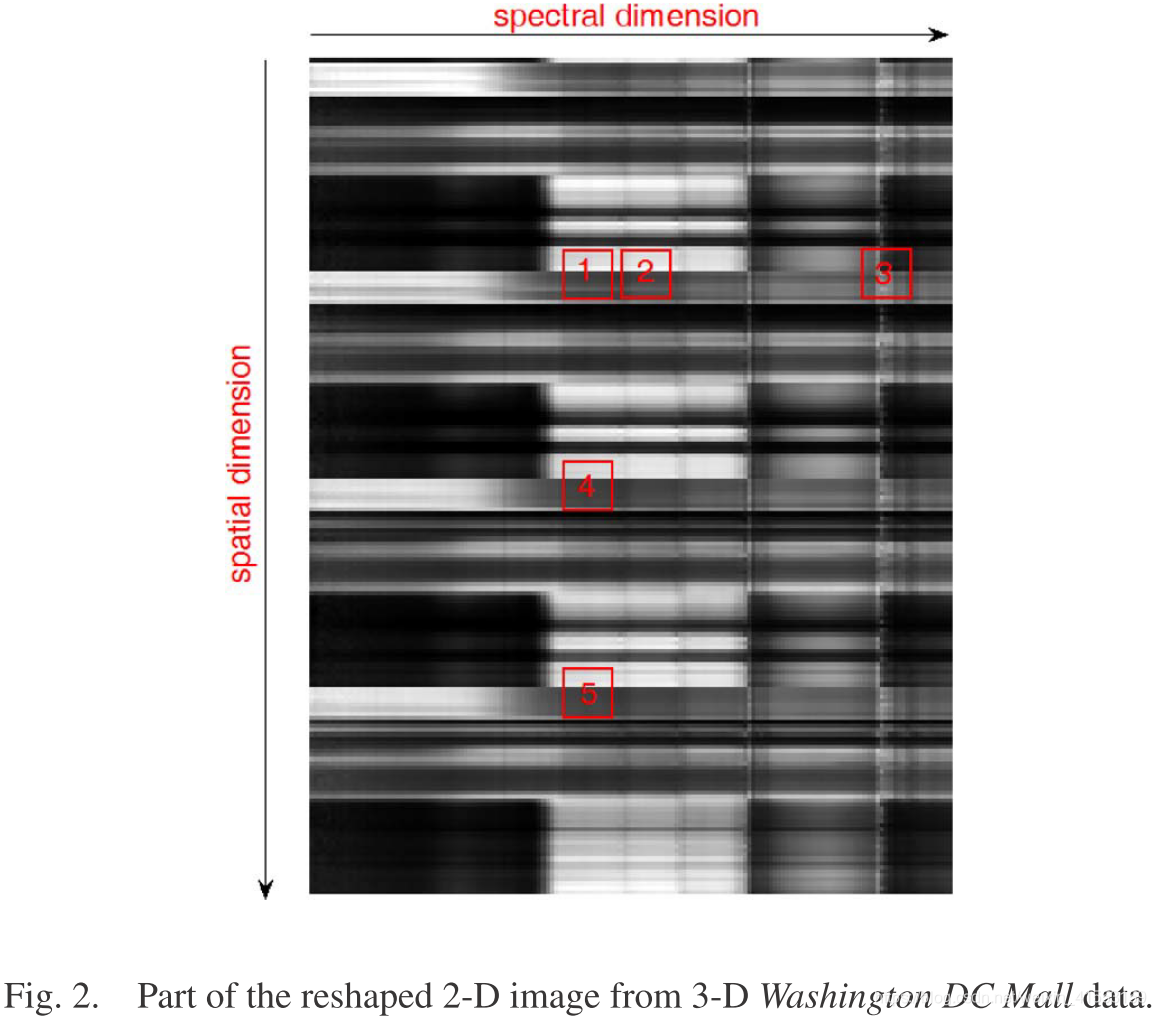
如上图,块1和2是相似的,因为它们在光谱维度上是相邻的,光谱反射率值几乎相同。然而,块1和3之间的RAC较低,尽管其中的像素来自相同的空间坐标。块1和块3的光谱反射率值差异很大,因为它们位于不同的波段子集。对于块1、4和5,尽管它们来自不同的空间位置,但由于空间域中的结构(自)相似性,它们之间的RAC仍然很高。如上所述的分析,相似的块位于整个空间域和局部光谱域。
如果不考虑整个光谱维度上的RAC,会导致较大的光谱失真。无噪声HSI的秩预计会很低。它可以看作是光谱域中的一个全局约束。通过考虑光谱域中的全局限制,(1)式可以改为 { X , D , α i } = arg min D , X , α i γ ∥ X − Y ∥ 2 2 + ∑ i ∥ R i X − D α i ∥ 2 2 + ∑ i η ∥ α i ∥ 0 + μ R a n k ( X ) \left\{X, D, \alpha_{i}\right\}=\underset{D, X, \alpha_{i}}{\arg \min } \gamma\|X-Y\|_{2}^{2}+\sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\sum_{i} \eta\left\|\alpha_{i}\right\|_{0}+\mu Rank(X) {X,D,αi}=D,X,αiargminγ∥X−Y∥22+i∑∥RiX−Dαi∥22+i∑η∥αi∥0+μRank(X)
其中 X , Y ∈ R M N × L X,Y\in\mathbb{R}^{MN\times L} X,Y∈RMN×L,矩阵的秩可视为其奇异值矩阵的 L 0 L_0 L0范数,它是非凸的,上述目标函数的解不一定唯一。这里我们用核范数放松(relax)秩算子,核范数是所有奇异值的绝对值之和: { X , D , α i } = arg min D , X , α i γ ∥ X − Y ∥ 2 2 + ∑ i ∥ R i X − D α i ∥ 2 2 + ∑ i η ∥ α i ∥ 0 + μ ∥ X ∥ ∗ ( 2 ) \left\{X, D, \alpha_{i}\right\}=\underset{D, X, \alpha_{i}}{\arg \min } \gamma\|X-Y\|_{2}^{2}+\sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\sum_{i} \eta\left\|\alpha_{i}\right\|_{0}+\mu \lVert X \rVert _{\ast}\quad(2) {X,D,αi}=D,X,αiargminγ∥X−Y∥22+i∑∥RiX−Dαi∥22+i∑η∥αi∥0+μ∥X∥∗(2)
Solver
目标函数(2)可以通过变量分裂和替代优化(variable splitting and alternative optimization)来求解。引入辅助变量 U U U,第四项中的变量 X X X用约束 X = U X = U X=U的 U U U代替,于是(2)式可以写成 { X , U , D , α i } = arg min D , X , α i γ ∥ X − Y ∥ 2 2 + ∑ i ∥ R i X − D α i ∥ 2 2 + ∑ i η ∥ α i ∥ 0 + μ ∥ U ∥ ∗ s . t . X = U \left\{X, U, D, \alpha_{i}\right\}=\underset{D, X, \alpha_{i}}{\arg \min } \gamma\|X-Y\|_{2}^{2}+\sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\sum_{i} \eta\left\|\alpha_{i}\right\|_{0}+\mu \lVert U \rVert _{\ast}\\ s.t.\quad X=U {X,U,D,αi}=D,X,αiargminγ∥X−Y∥22+i∑∥RiX−Dαi∥22+i∑η∥αi∥0+μ∥U∥∗s.t.X=U
对于适当的参数 λ \lambda λ,我们用二次罚函数(quadratic penalty)求解以下无约束问题: { X , U , D , α i } = arg min D , X , U , α i γ ∥ X − Y ∥ 2 2 + ∑ i ∥ R i X − D α i ∥ 2 2 + ∑ i η ∥ α i ∥ 0 + μ ∥ U ∥ ∗ + λ ∥ X − U ∥ 2 2 ( 3 ) \left\{X, U, D, \alpha_{i}\right\}=\underset{D, X, U, \alpha_{i}}{\arg \min } \gamma\|X-Y\|_{2}^{2}+\sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\sum_{i} \eta\left\|\alpha_{i}\right\|_{0}+\mu \lVert U \rVert _{\ast}+\lambda\lVert X-U \rVert_2^2\quad(3) {X,U,D,αi}=D,X,U,αiargminγ∥X−Y∥22+i∑∥RiX−Dαi∥22+i∑η∥αi∥0+μ∥U∥∗+λ∥X−U∥22(3)
对于上述目标函数,使用替代优化方法。我们针对部分变量,通过固定其他变量来优化上式,然后将其简化为以下子问题:
(1)固定
U
,
X
U,X
U,X,优化
α
i
,
D
\alpha_i,D
αi,D
{
D
,
α
i
}
=
arg
min
D
,
α
i
∑
i
∥
R
i
X
−
D
α
i
∥
2
2
+
∑
i
η
∥
α
i
∥
0
\left\{D, \alpha_{i}\right\}=\underset{D, \alpha_{i}}{\arg \min } \sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\sum_{i} \eta\left\|\alpha_{i}\right\|_{0}
{D,αi}=D,αiargmini∑∥RiX−Dαi∥22+i∑η∥αi∥0
这个阶段是字典学习和稀疏编码,这个子问题的唯一解是存在的,并且可以通过K均值奇异值分解(K-SVD)方法来求解。
(2)固定
X
,
D
,
α
i
X,D,\alpha_i
X,D,αi,优化
U
U
U
{
U
}
=
arg
min
U
μ
2
λ
∥
U
∥
∗
+
1
2
∥
X
−
U
∥
2
2
\{U\}=\arg \min _{U} \frac{\mu}{2 \lambda}\|U\|_{*}+\frac{1}{2}\|X-U\|_{2}^{2}
{U}=argUmin2λμ∥U∥∗+21∥X−U∥22
它可以通过对矩阵 U U U的奇异值进行逐元素软收缩(elementwise soft shrinkage)来解决。
(3)固定
U
,
D
,
α
i
U,D,\alpha_i
U,D,αi,优化
X
X
X
{
X
}
=
arg
min
X
γ
∥
X
−
Y
∥
2
2
+
∑
i
∥
R
i
X
−
D
α
i
∥
2
2
+
λ
∥
X
−
U
∥
2
2
\left\{X\right\}=\underset{X}{\arg \min } \gamma\|X-Y\|_{2}^{2}+\sum_{i} \left\|R_{i} X-D \alpha_{i}\right\|_{2}^{2}+\lambda\lVert X-U \rVert_2^2
{X}=Xargminγ∥X−Y∥22+i∑∥RiX−Dαi∥22+λ∥X−U∥22
对于上式中的 X X X存在一个封闭形式的解: X = ( γ I + ∑ i R i T R i + λ I ) − 1 ∙ ( γ Y + ∑ i R i T D α i + λ U ) X=\left(\gamma I+\sum_{i} R_{i}^{T} R_{i}+\lambda I\right)^{-1} \bullet\left(\gamma Y+\sum_{i} R_{i}^{T} D \alpha_{i}+\lambda U\right) X=(γI+i∑RiTRi+λI)−1∙(γY+i∑RiTDαi+λU)
根据[19]和[31],公式(1)的解存在且唯一。此外,核范数项是凸的、适当的和强制的(coercive),因此,公式(2)的解仍然存在并且是唯一的[46]。如果参数 λ \lambda λ变为无穷大,则(3)的解收敛于(2)的解。对于固定 λ \lambda λ,文[47]证明并分析了收敛性质。对子问题重复上述优化,直到满足迭代停止条件。当连续迭代的解或相应的目标函数值没有显著变化时,即两个连续迭代解之间的差范数小于给定的正常数时,算法停止。如果运行时间超过上限,我们也可以停止迭代过程。在我们的实验中,当迭代次数达到预定义的最大值时,迭代停止。
[19] Image denoising via sparse and redundant representations over learned dictionaries
[31] K-SVD: An algorithm for designing of over complete dictionaries for sparse representation
[46] J. Nocedal and S. J. Wright, Numerical Optimization, 2nd ed.
[47] A new alternating minimization algorithm for total variation image reconstruction

值得注意的是,上述求解方法与交替方向最小化乘子(ADMM)法相似,但仍有一定差异。变量分裂技术通常用于通过增加一系列等式约束将优化问题解耦(decouple)成一组独立的子问题。子问题比原问题更容易解决。
增广拉格朗日方法(ALM)通常用于解决线性等式约束优化问题。ALM方案中变量太多,不仅包括解,还包括拉格朗日乘子和变量分裂引入的辅助变量。因此,我们可以优化ALM问题,关于每个变量,交替和迭代地使用ADMM的想法。
我们的算法每次迭代的整体计算复杂度为 O ( M N L 2 + M N L + L ) . O(MNL^2+MNL+L). O(MNL2+MNL+L).
实验
对比方法:PCA+WS,VBM3D
Denoising of hyperspectral imagery using principal component analysis and wavelet shrinkage
模拟数据实验
评估指标:PSNR,SSIM,FSIM,分类精度
无论测试数据是什么,我们算法中的参数都是根据噪声水平设置的。


当噪声的标准差增加时,基于稀疏表示的去噪方法的有效性降低,因为从有噪声的HSI中学习的字典将被噪声破坏,并且当噪声水平较高时变得更差。
在稀疏表示方法的稀疏编码和字典更新阶段可能引入近似误差。这些误差可以通过低秩约束来抑制。另一方面,低秩重构只考虑谱相关;如果考虑到空间信息,性能将得到提高。稀疏表示在空间维度上利用了RAC。
参数选择: γ = 30 / σ \gamma=30/\sigma γ=30/σ, η \eta η依赖于噪声水平,并在稀疏编码过程中通过贪婪算法隐式处理,例如OMP方法。参数 μ \mu μ取决于噪声方差和数据大小,如果噪声方差和数据量很大,它应该很大。 μ \mu μ和 λ \lambda λ的比例为 μ / λ = max ( M N , L ) ∙ σ / 6.5 \mu / \lambda=\max (\sqrt{M N}, \sqrt{L}) \bullet \sigma / 6.5 μ/λ=max(MN,L)∙σ/6.5,噪声水平将在迭代过程中降低;因此,参数 μ \mu μ应更新为较小的值。在实验中,我们在每个迭代循环中将这个参数除以10。第四个正则化参数 λ \lambda λ设置为100。15是最佳迭代次数,如果迭代次数太多,稀疏编码阶段可能会发生过拟合,进而降低去噪性能。
改进:当噪声较强时,去噪性能可能会降低。这是基于字典学习的去噪方法的缺点。未来,我们将致力于消除强噪声下HSI的噪声。加速算法的速度是另一个具有实际意义的研究方向。
代码
源代码:http://pan.baidu.com/s/1sjNTijj
华盛顿购物中心图(200×200×191)测试结果(PSNR,SSIM,FSIM)(似乎有问题):历时 11236.338934 秒。
结果不太好,需要调参

使用LRMR的计算PSNR和SSIM:
















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









