






简单的线性回归用于预测分析和推断。在这种类型中,存在一个自变量和一个因变量。每当建模中存在因果关系时,我们都会进行回归分析。当我们使用因子分析技术时,性能在实时分析中更加准确。回归分析基础知识在有监督的机器学习中的使用。这里要注意的三件事:
- 我们需要数据来进行分析,对于整个人群来说,这是一个非常繁琐的任务,因此我们需要获取样本数据进行分析。
- 获取数据后,我们需要设计一个模型,使其适用于整个人群。
- 建模之后,我们可以对总体进行预测。
直线方程为
y = mx + b
这里,
Y是因变量(结果)或预测变量。
X是一个 自变量。
M是一个斜率,或者我们可以说是梯度。
B是y轴上的值截距。
Y是X的函数。回归模型是线性近似。为了获得良好的预测,我们需要找到B和M。
例子:
假设我们具有“能量”和“公里数”的适应性数据。

我们需要找到乙和中号。查找这些值得公式如下:
M =样本数*(XY总和-X总和* Y总和)/样本数*(X平方总和-X总和的平方)
B = Y总和-M * X总和/样本数
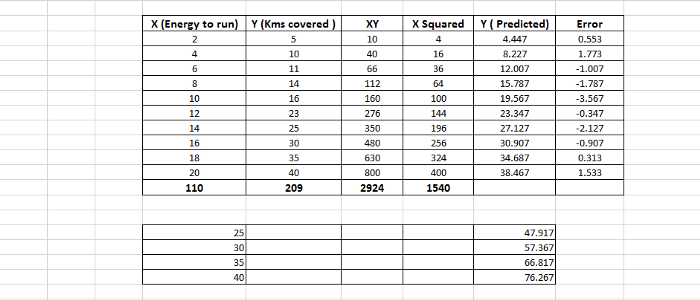
该图显示了这些值。

计算出该值之后,M变为1.89,B的值为0.667。从这些值,我们可以从公式中得出预测。
Y = 1.89 * X + 0.667
在检查了一些X值后,可以预测公里数。一个例子如下所示:
我们得到了模型,但是是一种简单的技术。让我们用python检查是否获得相同的值。
#import all the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm读取Excel文件
df = pd.read_excel("fitness.xlsx")使用describe函数查看统计信息。

将数据分为x和y。
y = df['Y1']
x = df['X1']
#plot the scatter plot between them
plt.scatter(x,y)
plt.xlabel('Energy', fontsize =20)
plt.ylabel('Kms Covered', fontsize =20)
plt.show()我们几乎得到了线性相关。

现在,将OLS模型拟合到我们的数据上。
x_new = sm.add_constant(x)
output = sm.OLS(y, x_new).fit()
output.summary()
#output:
coef
---------------------------------
const 0.667
x1 1.89得到摘要后,我们得到相同的值。在这里,我们使用statsmodels,这是用于统计和推断的出色库。
拟合之后,OLS模型允许使用拟合线检查散布图。
plt.scatter(x1,y)
y_pred = 1.89*X + 0.667
fig = plt.plot(x1, y_pred, lw = 5, c='red', label='regression line'
plt.xlabel('Energy', fontsize =20)
plt.ylabel('Kms Covered', fontsize =20)
plt.show()这是拟合最佳线后的散点图。

结论:
OLS提供了简单的线性回归近似值,而statsmodel提供了对数据统计信息的绝佳见解。
















 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











