






引言
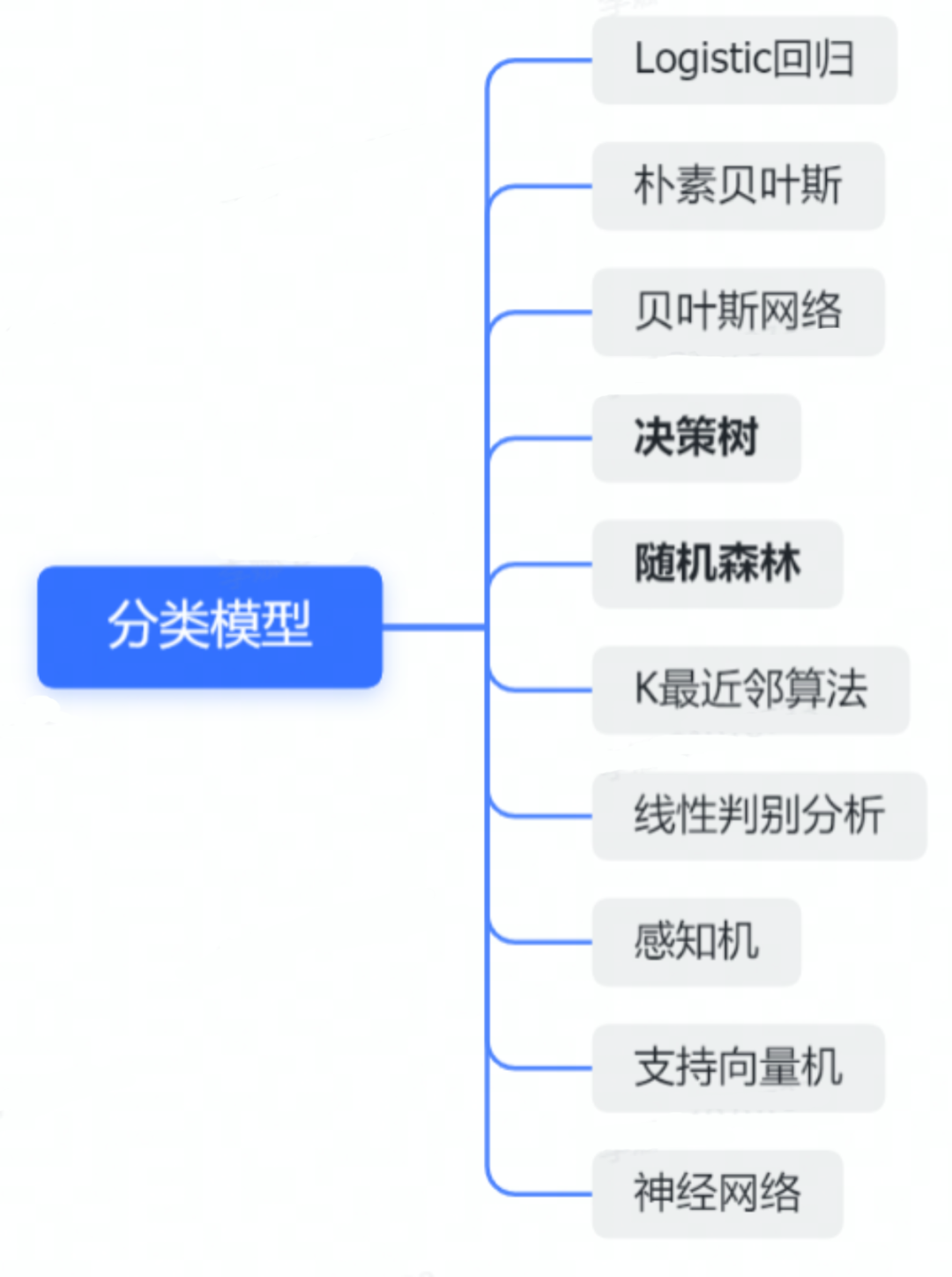
上回我们讨论了机器学习中的三种重要的分类模型:Logistic 回归、朴素贝叶斯、贝叶斯网络,并对这三种模型的数学推导和实例实现有了一个深刻的认识。今天我们继续介绍另外两种基础的分类算法:决策树和随机森林,本期分享的主要任务就是要讨论决策树的生成方法,包括 ID3 算法、C4.5 算法和 CART 算法,并通过清晰易懂的应用实例解释说明算法的实现细节。相信有了决策树基础,后面再进行随机森林的构建就会变得非常容易。
往期回顾
| 模型 | 特点 | 应用 | ||||
| 逻辑回归 (Logistic Regression) | 一种线性分类模型,在线性回归的基础上,通过Sigmoid函数将线性回归连续值压缩到0~1之间,使其拥有概率意义,实现值到概率的转换。 | 设备故障诊断、疾病诊断等 | ||||
| 朴素贝叶斯 (Naive Bayesian Model) | 基于贝叶斯定理和特征条件独立性假设,概率理论为基础的分类算法。对于给定的训练集,朴素贝叶斯首先基于特征条件独立假设学习输入和输出的联合概率分布,然后基于此模型,对给定的输入实例,利用贝叶斯公式求出最大的后验概率。 | 文本分类:垃圾邮件过滤、敏感言论检测、情等 | ||||
| 贝叶斯网络 (Bayesian Network Model) | 贝叶斯网络是一个由有向无环的逻辑图和各节点条件概率表所构建的概率图模型,贝叶斯网络与朴素贝叶斯的不同在于它考虑了各属性之间的相互关系。它能结合概率统计学、决策分析、人工智能等方法对不确定性事物进行表达描述,利用先验信息对未知数据进行分析推理,可以从不完全、不精确或不确定的知识或信息中做出有效推理。 | 病情诊断、故障分析等因果分析场景 | ||||
1 决策树
1.1 决策树核心思想
决策树作为机器学习中一种常用的分类算法,具有解释性强,符合人类的直观思维的特点。决策树类似模拟大脑逻辑决策的过程,一个决策树可以看做一种条件判断 if-then-else-then 规则的集合。以相亲为例,重现相亲时的情景...
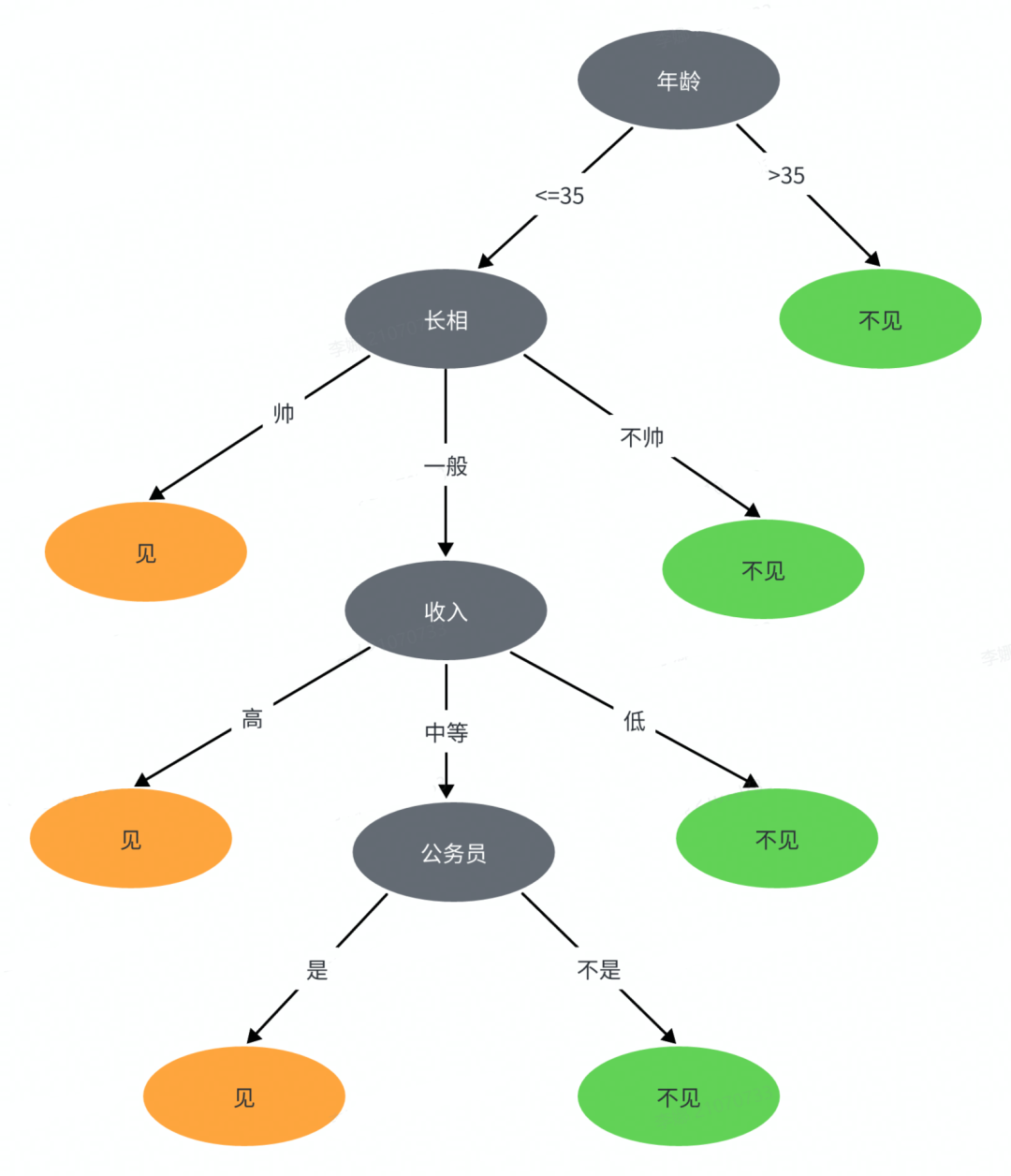
决策树是一种树形结构,其中:
-
中间结点和根节点表示一个属性的测试判断
-
分支表示一个测试输出
-
叶子结点代表一种类别
决策树有多种不同类型的模型,其中比较典型的模型包括ID3树、C4.5树和CART树,其中ID3与C4.5是以熵为基础的决策树生成算法,而CART算法采用Gini系数作为选择准则的基础。在决策树模型的构建过程中,比较常见实现的准则有信息增益、信息增益率和Gini指数,下面我们来简单介绍一下这几种方法在构建决策树时进行最优属性判定中的应用。
首先,我们需要先了解信息论中的一个概念,香农熵(信息熵)描述了随机变量不确定性程度
信息熵越大说明随机变量的不确定性越大,所包含的信息量越大;反之,信息量越小,数据纯度越高。
1.1.1 信息增益(ID3)
信息增益是ID3算法采用的属性划分标准。信息增益定义为数据集的经验熵(类别标签的熵值)与划分后条件熵的差值,数学定义如下
代表特征属性,
为分类标签。其中,
信息增益越大,代表特征X的分类能力越强,即通过特征X分类后数据熵值减少越多,分类后数据纯度提升越大。
通过上表,下面演示一个简单的信息增益计算的应用实例。
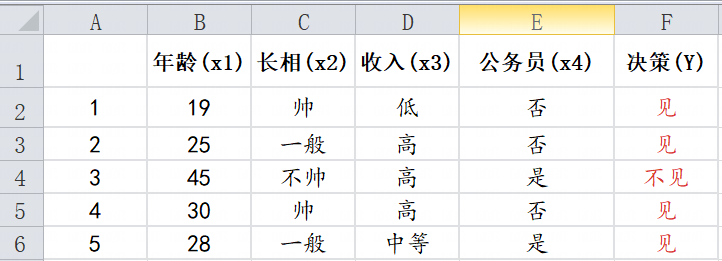
首先可以统计出经验熵为
![]()
以公务员属性划分:

因此,如果以公务员属性为分裂节点,分类后的熵值减少0.3219。
1.1.2 信息增益率(C4.5)
1.信息增益率
C4.5算法采用信息增益率作为节点选取标准。信息增益率定义为
信息增益比可理解为信息增益与特征X信息熵的比值,该比值越大,说明当前特征X具有很强分类的能力。
公务员属性划分信息增益率为
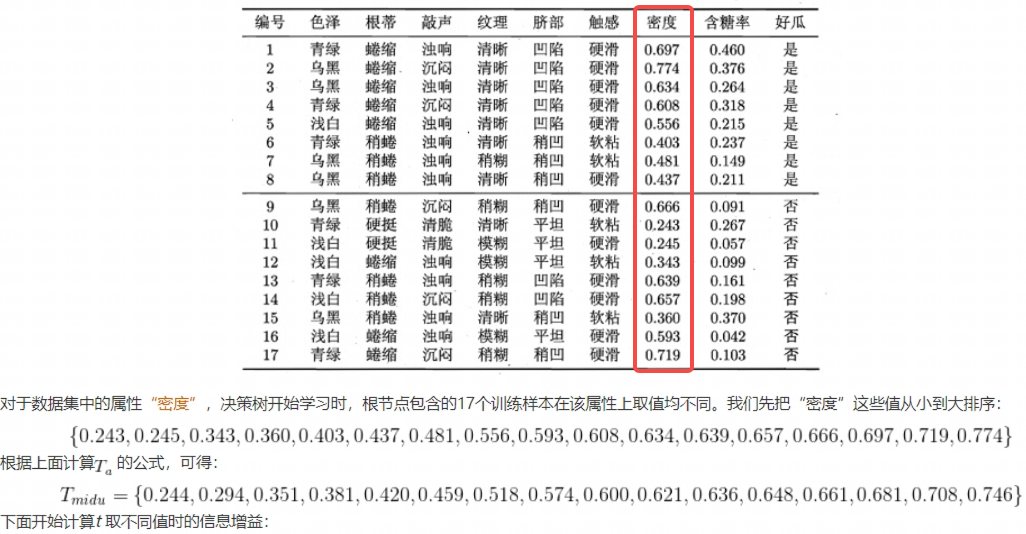
2.连续特征离散化
连续属性取值数目并非有限,无法直接对连续数据进行划分。C4.5引入二分法对连续属性进行处理。假定样本集 的连续属性
有
个不同的取值,对这些值从小到大排序,得到属性值的集合
,将
的中点值作为候选划分点,于是得到包含
个元素的划分点集合
基于每个划分点 ,可将样本集
分为子集
和
,其中
中包含属性
中不大于
的样本集合,
包含属性
中大于
的样本集合。此时我们就完成了连续变量的离散化,这样,后续我们就可以像处理离散数据值那种方式处理连续变量。
举个例子

1.1.3 Gini指数(CART)
CART分类树采用 Gini 指数作为节点选取标准。Gini指数数学定义为
为样本属于第
类的概率。Gini指数反映了从数据集
中随机抽取两个样本,其类别不一致的概率。因此,Gini指数越小表示数据集纯度越高。
特别地,对于一个二分类问题,Gini指数为
若一个训练集 被特征值
划分为2个子集
,基尼指数可定义为
Gini 指数的计算不需要对数运算,因而实现起来更加高效。
公务员属性的Gini指数:
D1={1,2,4} D2={3,5}
对于离散型特征,CART算法与ID3算法、C4.5算法是有很大区别的。如果离散特征值多于两个,ID3和C4.5会在结点上根据特征值划分出多叉树。但是CART算法则不同,无论离散特征值有几个,在结点上都会划分成二叉树。如下图所示,假设特征 有
个取值,分别为
,需要对其进行二划分

CART算法是将符合某个特征取值的数据分为一个集合,而不符合这个特征取值的数据划分到另一个集合。比如,图中的划分1,CART算法将符合取值的 样本归为一类,将符合其他特征取值的样本归为另一类。
个特征取值就有
种划分方式,计算每种划分下的Gini指数,最后选择Gini指数最小的一个划分作为最优的特征划分。这样,我们可以根据(10)计算出
个Gini系数
最后找出这 个Gini系数中的最小值作为特征
的最优切分点。
问题:找出属性收入的最优切分点
1. 划分1:x3=低,{1} {2,3,4,5}
2. 划分2:x3=中等,{5} {1,2,3,4}
3. 划分3:x3=高,{2,3,4} {1,5}
所以,"x3=高"为属性x3的最优切分点
总结
| 算法 | 树结构 | 特征选择标准 | 支持模型 | 连续值处理 | 缺失值处理 | 剪枝优化 |
| ID3 | 多叉树 | 信息增益 | 分类 | 不支持 | 不支持 | 不支持 |
| C4.5 | 多叉树 | 信息增益率 | 分类 | 支持 | 支持 | 支持 |
| CART | 二叉树 | 基尼系数(分类)、平方误差和(回归) | 分类、回归 | 支持 | 支持 | 支持 |
1.2 ID3决策树生成
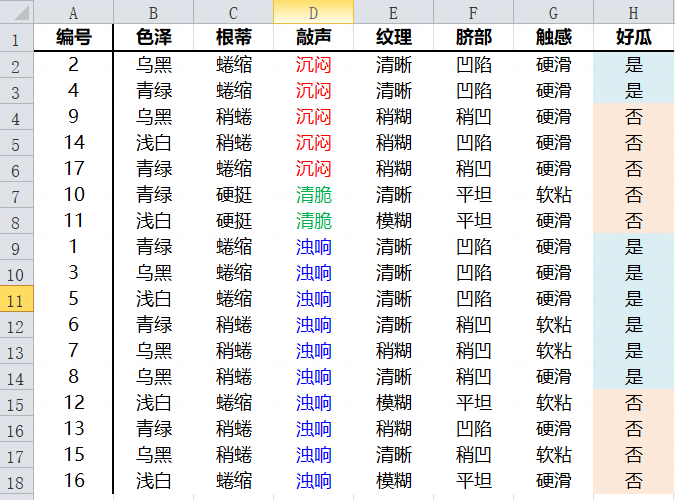
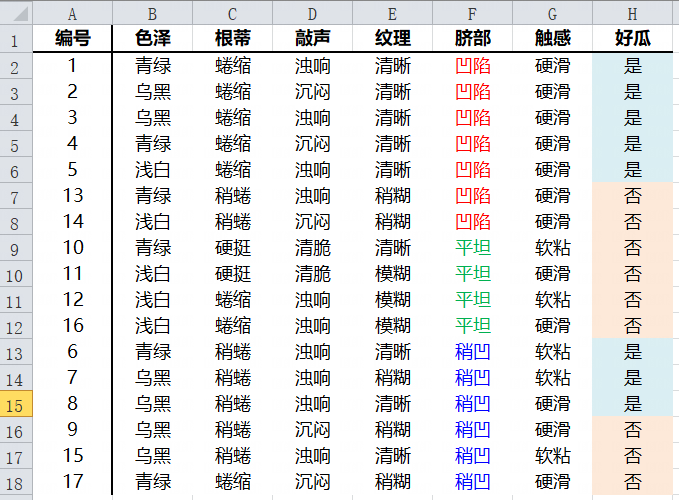
原始数据集
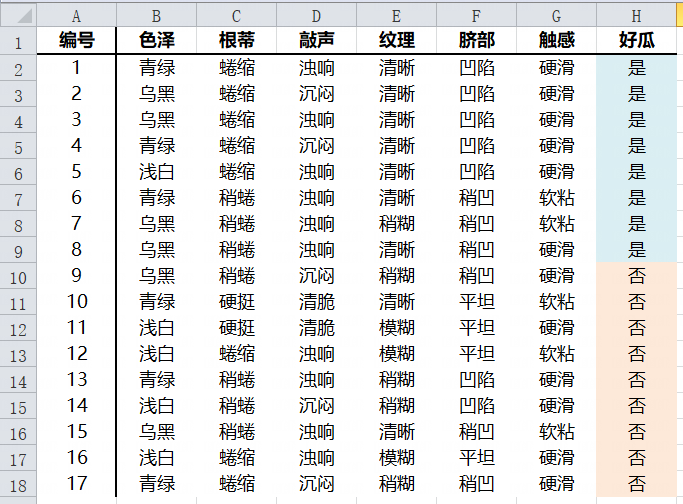
本数据集 共包括17条数据,6个特征属性,2个标签取值。
根据最右侧一列标签数据直接计算出经验熵
1. 分别计算6个属性的信息增益,选择最大信息增益对应的属性作为分裂节点
-
色泽属性
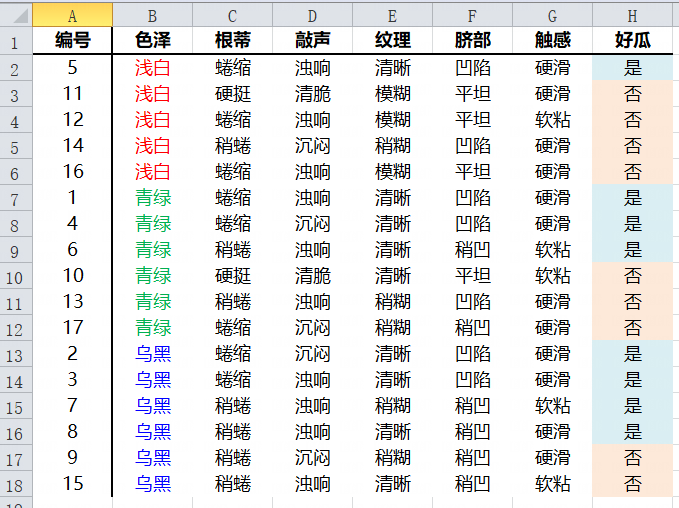
色泽属性中三种类型的条件熵分别为
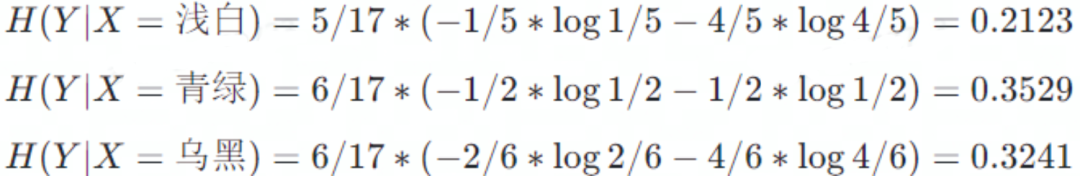
因此,信息增益为
![]()
-
根蒂属性
根蒂属性中三种类型的条件熵分别为

因此,信息增益为
![]()
-
敲声属性
敲声属性中三种类型的条件熵分别为
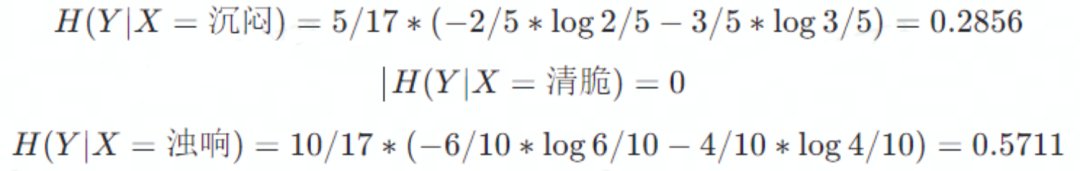
因此,信息增益为
![]()
-
纹理属性
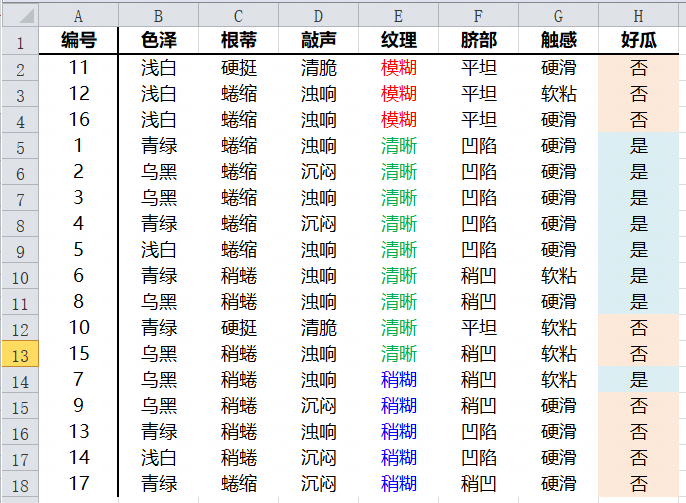
纹理属性中三种类型的条件熵分别为
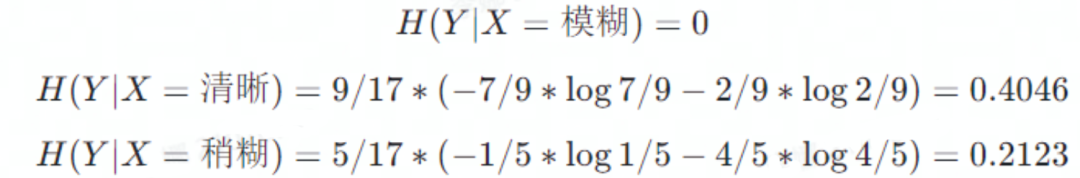
因此,信息增益为
![]()
-
脐部属性
脐部属性中三种类型的条件熵分别为
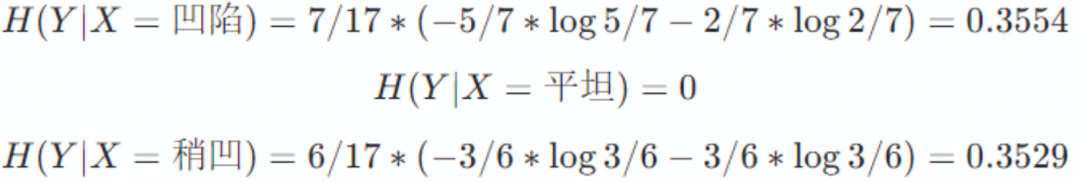
因此,信息增益为
![]()
-
触感属性
触感属性中三种类型的条件熵分别为
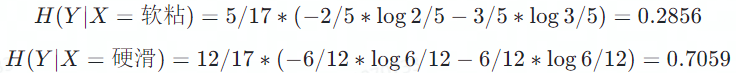
因此,信息增益为
![]()
综上,可得到6个属性对应的信息增益
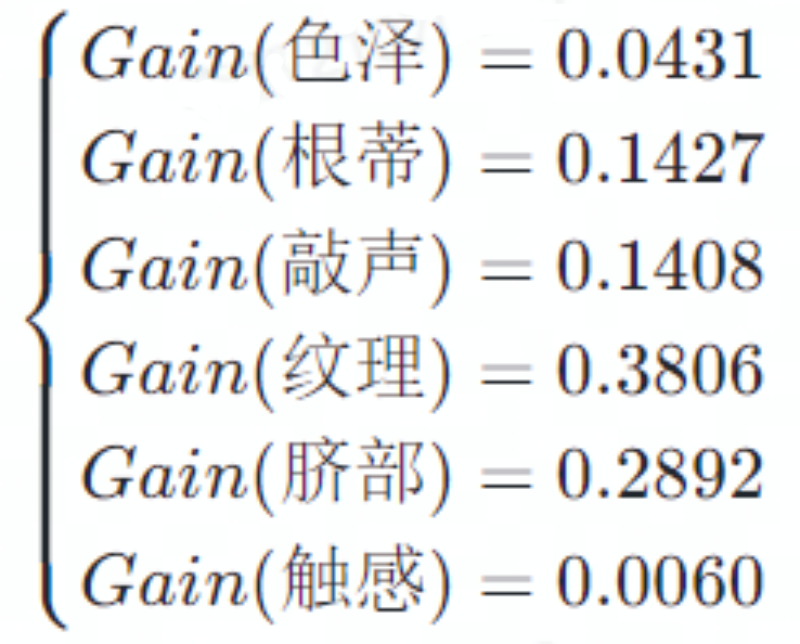
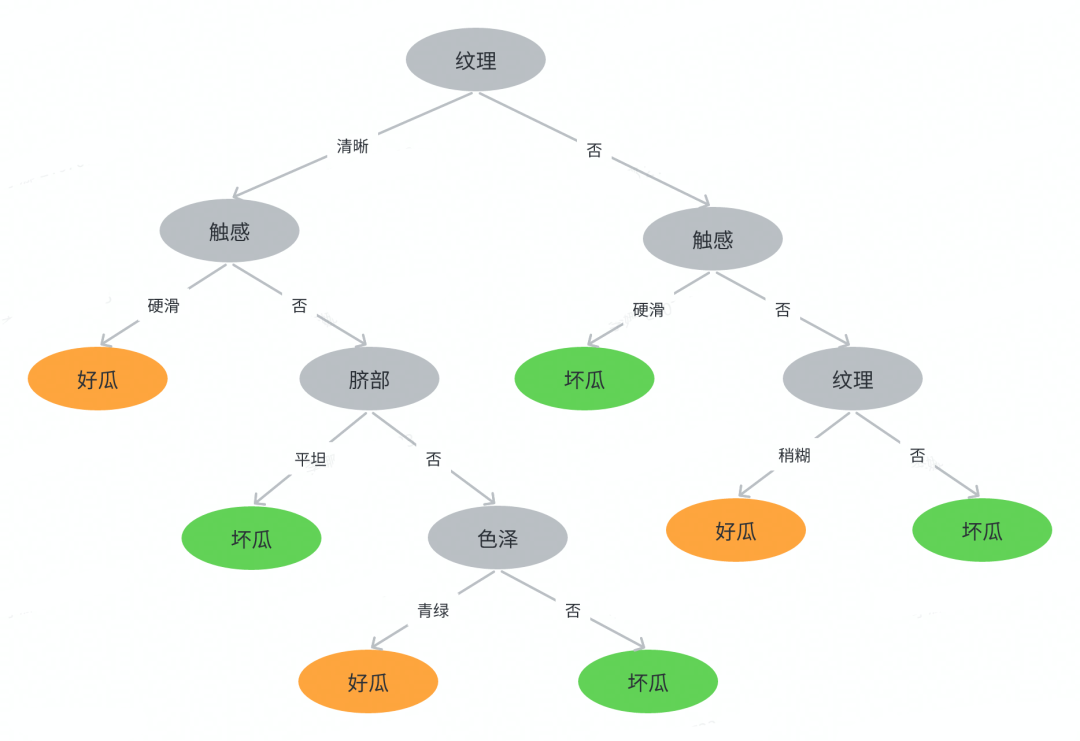
可见当以纹理属性划分时对应的信息增益最大,因此决策树根节点选择纹理,初始树状图如下:
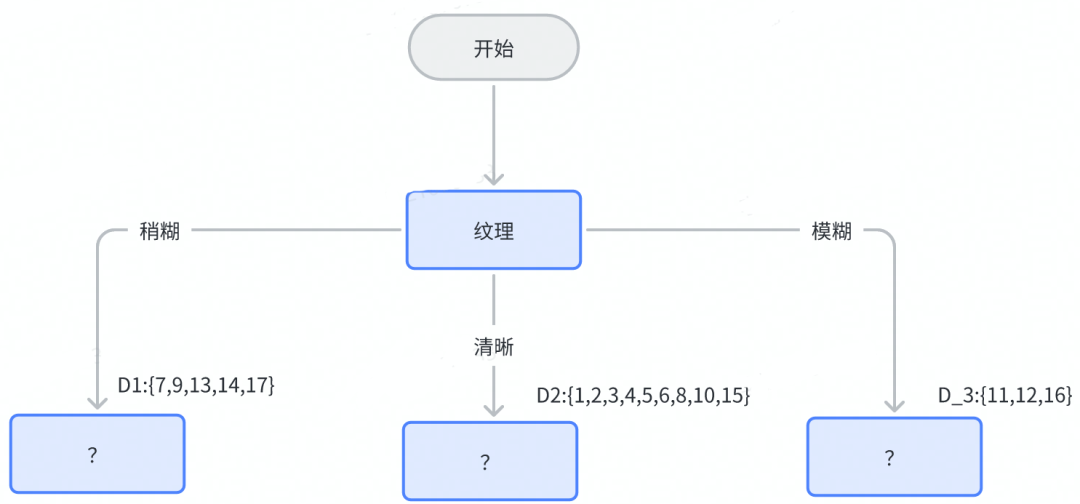
2. 以递归的方式分别计算子数据集 ,
,
的信息增益,选择最大增益值对应的属性作为分裂节点。
-
使用纹理属性判断是否稍糊即可得到稍糊子数据集
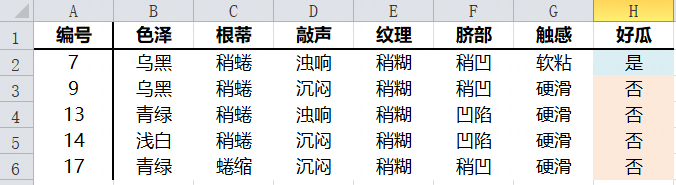
子数据集 的经验熵为0.7219,不确定性非常高,需要进一步划分。下面分别计算除纹理外的其他属性的信息增益。

可知触感属性信息增益最大,因此,此处应使用触感属性作为分裂节点。
-
使用纹理属性判断是否清晰即可得到清晰子数据集
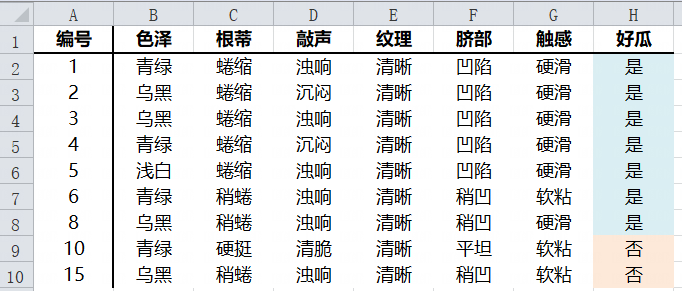
子数据集 的信息熵为0.7642,不确定性也是非常高,下面分别计算除纹理外的其他属性的信息增益。

可见根蒂、脐部和触感三个属性均可达到最大信息增益,这里可用任选其一作为划分属性。
-
使用纹理属性判断是否模糊即可得到模糊子数据集
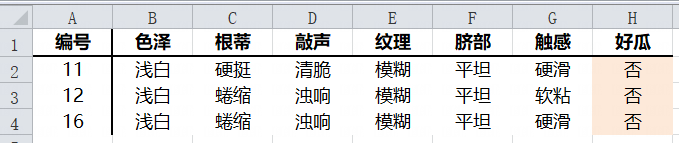
子数据集 的信息熵为0,数据纯度最大了,数据属于同一类,不需要进一步分类了。
同理,继续对每个分支结点进行类似递归操作直到节点不可分裂为止,可得到最终的决策树如下:
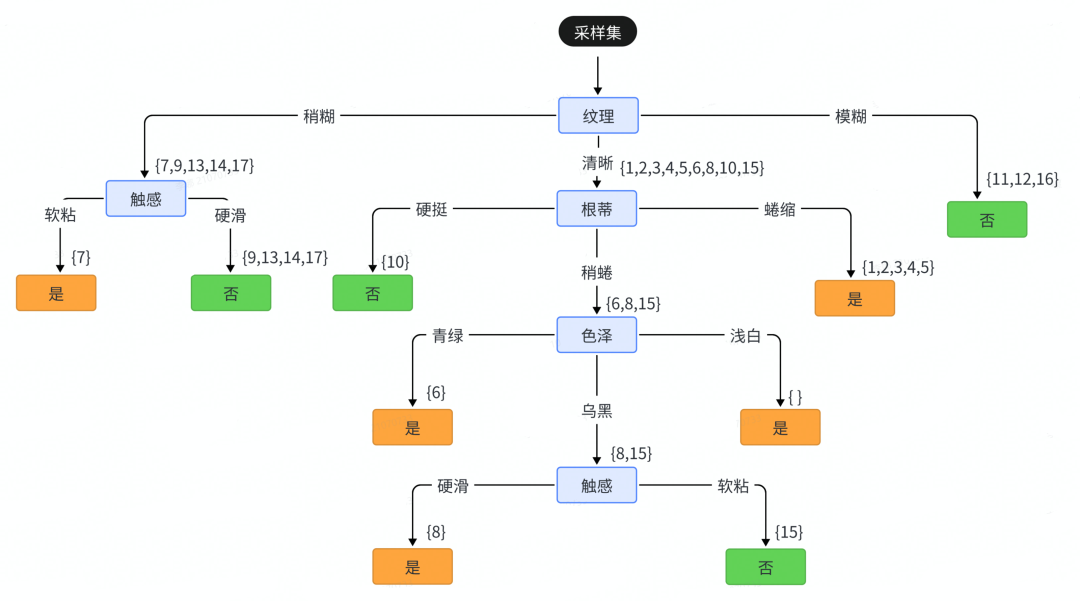
需要注意的是色泽属性浅白分支,这里其实是个空集合,那这里为什么判定为好瓜呢?
当前结点包含的样本集为空集,且不能划分,对应的处理措施为:将其设置为叶节点,类别为设置为其父节点集合{6,8,15}所含样本最多的类别,6,8为正样本,15为负样本,因此“色泽=浅白”结点的类别为好瓜。
此时我们可以利用该决策树进行预测,下面给出三个测试数据
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 决策 | |
| 1 | 浅白 | 硬挺 | 清脆 | 清晰 | 稍凹 | 软粘 | no |
| 2 | 乌黑 | 蜷缩 | 清脆 | 稍糊 | 平坦 | 软粘 | yes |
| 3 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 凹陷 | 硬滑 | yes |
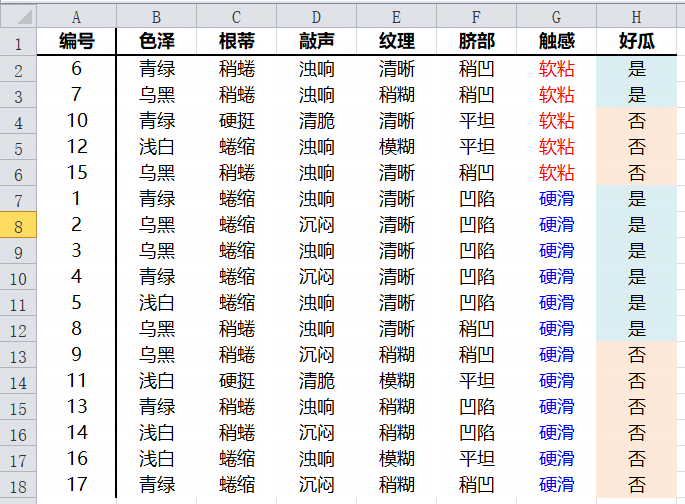
1.3 CART分类树生成
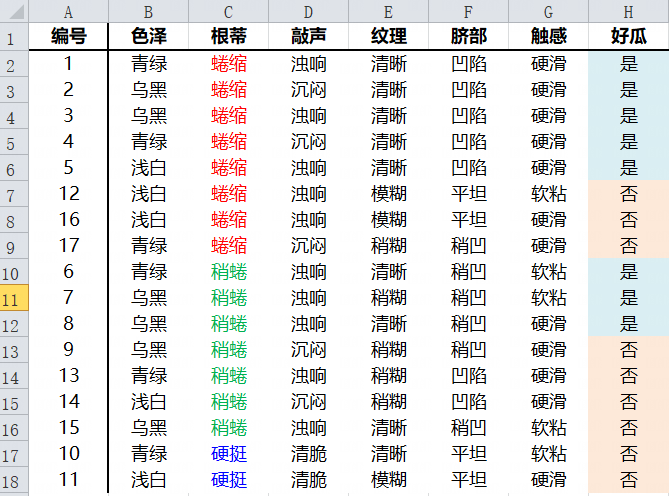
原始数据集
-
色泽属性Gini指数
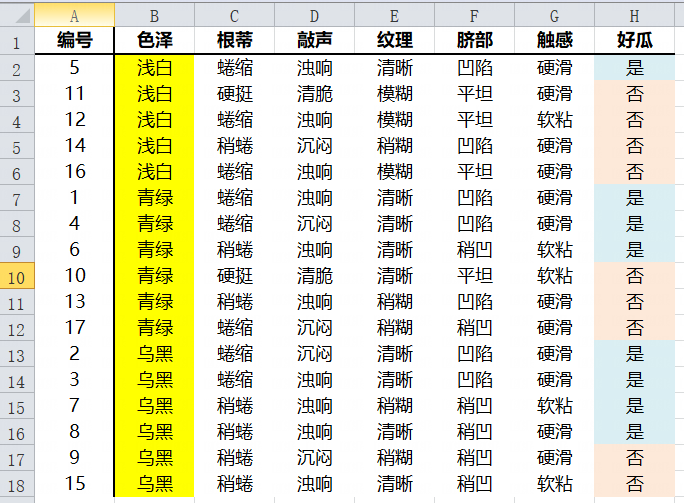
当选取色泽属性时,属性包含三个特征值,浅白,青绿,乌黑,但CART树是一棵二叉树,因此需要对数据进行划分然后计算出特征的最优切分点,该属性存在三种划分方式:
(1)以特征值浅白作为划分,有 浅白={5,11,12,14,16},青绿,乌黑={1,4,6,10,13,17,2,3,7,8,9,15} 两个子集
| 好瓜? | 浅白 | 其他 |
| 是 | 1 | 7 |
| 否 | 4 | 5 |
| 总计 | 5 | 12 |
(2)若以特征值青绿作为划分,有 青绿={1,4,6,10,13,17},浅白,乌黑={5,11,12,14,16,2,3,7,8,9,15} 两个子集
| 好瓜? | 青绿 | 其他 |
| 是 | 3 | 5 |
| 否 | 3 | 6 |
| 总计 | 6 | 11 |
(3)以特征值乌黑作为划分,有 乌黑={2,3,7,8,9,15},浅白,青绿={5,11,12,14,16,1,4,6,10,13,17} 两个子集
| 好瓜? | 乌黑 | 其他 |
| 是 | 2 | 4 |
| 否 | 4 | 7 |
| 总计 | 6 | 11 |
特征值浅白的Gini指数最小,因此浅白作为色泽属性的最优切分点。
-
根蒂属性Gini指数
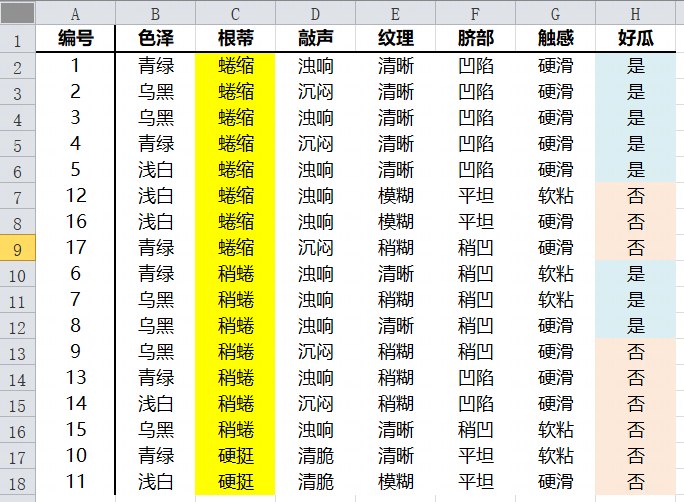
同理,对于根蒂属性
| 好瓜? | 蜷缩 | 其他 |
| 是 | 5 | 3 |
| 否 | 3 | 6 |
| 总计 | 8 | 9 |
| 好瓜? | 稍蜷 | 其他 |
| 是 | 3 | 5 |
| 否 | 4 | 5 |
| 总计 | 7 | 10 |
| 好瓜? | 硬挺 | 其他 |
| 是 | 0 | 8 |
| 否 | 2 | 7 |
| 总计 | 2 | 15 |
特征值硬挺的Gini指数最小,因此硬挺作为根蒂属性的最优切分点。
-
敲声属性Gini指数
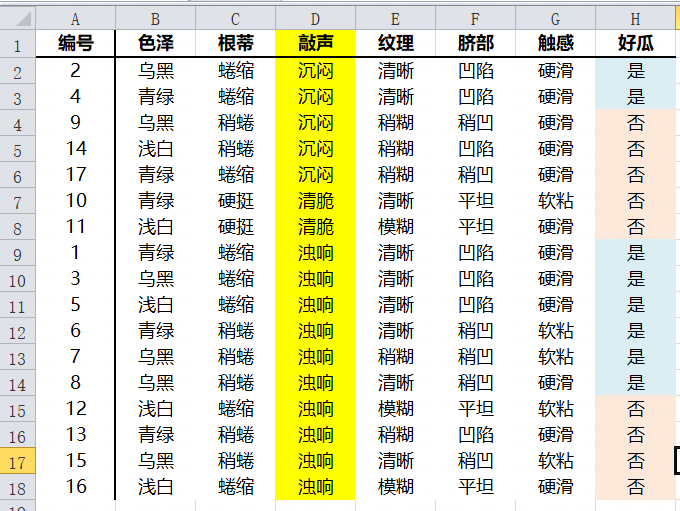
| 好瓜? | 沉闷 | 其他 |
| 是 | 2 | 6 |
| 否 | 3 | 6 |
| 总计 | 5 | 12 |
| 好瓜? | 清脆 | 其他 |
| 是 | 0 | 8 |
| 否 | 2 | 7 |
| 总计 | 2 | 15 |
| 好瓜? | 浊响 | 其他 |
| 是 | 6 | 2 |
| 否 | 4 | 5 |
| 总计 | 10 | 7 |
特征值清脆的Gini指数最小,因此清脆作为敲声属性的最优切分点。
-
纹理属性Gini指数
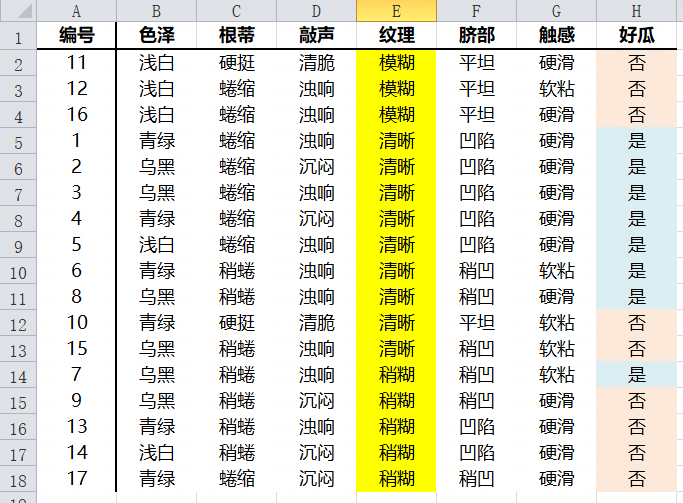
| 好瓜? | 模糊 | 其他 |
| 是 | 0 | 8 |
| 否 | 3 | 6 |
| 总计 | 3 | 14 |
| 好瓜? | 清晰 | 其他 |
| 是 | 7 | 1 |
| 否 | 2 | 7 |
| 总计 | 9 | 8 |
| 好瓜? | 稍糊 | 其他 |
| 是 | 1 | 7 |
| 否 | 4 | 5 |
| 总计 | 5 | 12 |
特征值清晰的Gini指数最小,因此清晰作为纹理属性的最优切分点。
-
脐部属性Gini指数
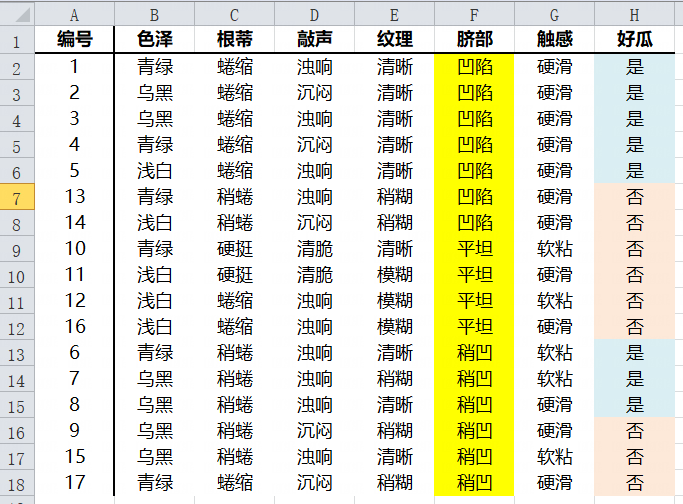
| 好瓜? | 凹陷 | 其他 |
| 是 | 5 | 3 |
| 否 | 2 | 7 |
| 总计 | 7 | 10 |
| 好瓜? | 平坦 | 其他 |
| 是 | 0 | 8 |
| 否 | 4 | 5 |
| 总计 | 4 | 13 |
| 好瓜? | 稍凹 | 其他 |
| 是 | 3 | 5 |
| 否 | 3 | 6 |
| 总计 | 6 | 11 |
特征值平坦的Gini指数最小,因此平坦作为脐部属性的最优切分点。
-
触感属性Gini指数
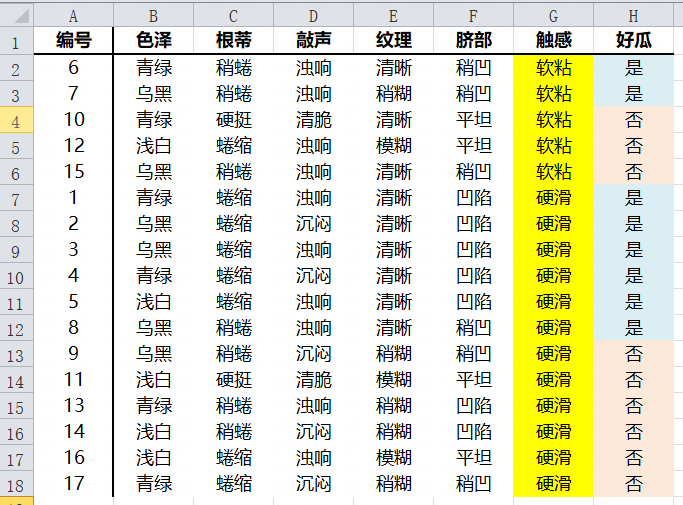
属性触感只有两个特征值,只有一个切分点,也是触感属性的最优切分点,因此只有一个Gini系数
| 好瓜? | 软粘 | 硬滑 |
| 是 | 2 | 6 |
| 否 | 3 | 6 |
| 总计 | 5 | 12 |
综上分析可知纹理属性的 最小,所以选择纹理作为最优分裂属性,X=清晰 为最优切分点。按照这种方法递归直到所有分支都不可再分为止,得到如下CART二叉树:
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 决策 | |
| 1 | 浅白 | 硬挺 | 清脆 | 清晰 | 稍凹 | 软粘 | no |
| 2 | 乌黑 | 蜷缩 | 清脆 | 稍糊 | 平坦 | 软粘 | yes |
| 3 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 凹陷 | 硬滑 | yes |
基础的决策树模型是后续集成学习模型的重要理论基础,在掌握决策树的生成方法后随机森林的构建就变得非常简单了。
2 随机森林
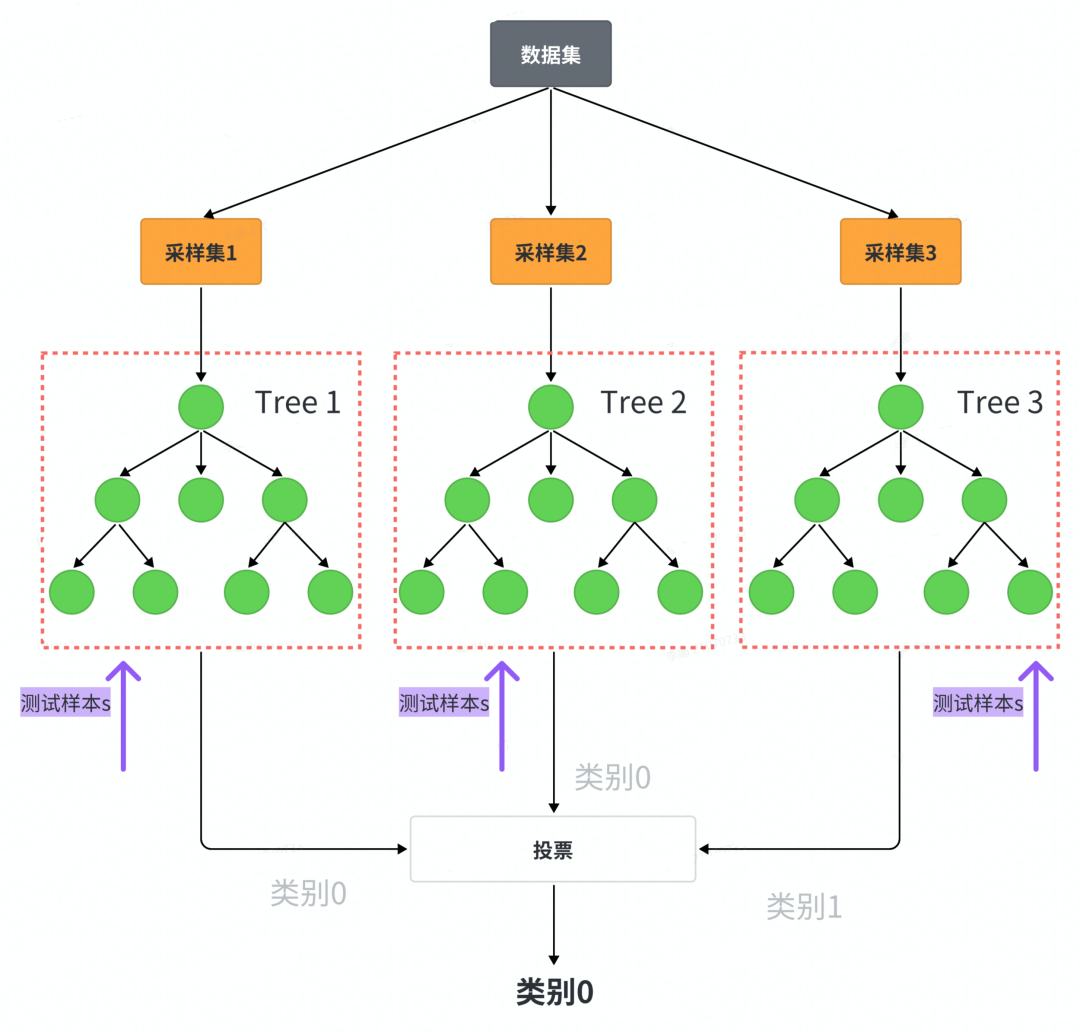
随机森林是由多个决策树组成,在得到一个随机森林后,当有新的样本进入的时候,随机森林中的每一棵决策树分别进行判断,然后分析出该样本属于哪一类,最后再看哪一类被选择最多,那么该样本就属于这一类。
所以,随机森林是以单决策树作为基分类器进行集成,并进一步在决策树训练过程中引入了随机选择数据和特征的方法,随机森林的随机性主要体现在两个方面,行抽样和列抽样:
-
行抽样:数据集的随机选取
-
列抽样:特征的随机选取
假设训练集$$T$$的数据容量大小为$$n$$,特征数目为$$m$$,构建的随机森林容量为$$k$$,随机森林算法的具体步骤描述如下:
实现流程:
-
行采样:对于训练集
,有放回地随机抽取
个样本组成抽样样本
。
-
列采样:随机从
个特征中选取出
个特征,并满足条件
。
-
基于抽样样本
-
重复(1)-(3)步构建
个决策树构成随机森林。
3 团队介绍
「三翼鸟数字化技术平台-前端开发能力平台」通过持续搭建和完善前端研发流程、跨端复用能力、通用能力、规范和机制,建立标准化、平台化的前端研发体系,致力于提升团队前端开发能力、研发效率和用户体验,同时负责内容交互、场景交互、小程序、海外app等前端业务开发。


















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









