









LDA变分EM算法
变分推理(variational inference)是贝叶斯学习中常用的,含有隐变量模型的学习方法。变分推理和上一章节的吉布斯采样不同,吉布斯采样的算法通过随机抽样的方法近似计算模型的后验概率,而变分推理通过解析的方法计算模型的后验概率的近似值。
本章节内容参考李航博士的《统计学习方法》
书中是简化版本的变分EM算法推导,本章节进行完整的推导。
上一章节介绍了LDA的吉布斯采样方法.
1. 变分推理
变分推理的思想如下:
假设模型是联合概率分布
p
(
x
,
z
)
p(x,z)
p(x,z),其中
x
x
x是观测变量,
z
z
z是隐变量 ,包括参数。目标是学习模型的后验概率
p
(
z
∣
x
)
p(z|x)
p(z∣x)。但是这个分布复杂无法直接求解,所以考虑用概率分布
q
(
z
)
q(z)
q(z)来近似条件概率分布
p
(
z
∣
x
)
p(z|x)
p(z∣x),之后用KL散度
K
L
(
q
(
z
)
∣
∣
p
(
z
∣
x
)
)
KL(q(z)||p(z|x))
KL(q(z)∣∣p(z∣x))计算两者之间的相似度,
q
(
z
)
q(z)
q(z)称为变分分布。
KL散度可以写成以下形式:
K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) = ∑ z q ( z ) log q ( z ) p ( z ∣ x ) = ∑ z q ( z ) log q ( z ) − ∑ z q ( z ) log ( p ( z ∣ x ) ) = ∑ z q ( z ) log q ( z ) − ∑ z q ( z ) log p ( z , x ) p ( x ) = ∑ z q ( z ) log q ( z ) − ∑ z q ( z ) log p ( z , x ) + ∑ z q ( z ) log p ( x ) = ∑ z q ( z ) log q ( z ) − ∑ z q ( z ) log p ( z , x ) + log p ( x ) = log p ( x ) − { E q [ log p ( x , z ) ] − E q [ log q ( z ) ] } \begin{aligned} KL(q(z) || p(z|x)) &= \sum_z q(z) \log \frac {q(z)} {p(z|x)} \\ &= \sum_z q(z) \log q(z) - \sum_z q(z) \log (p(z|x)) \\ & = \sum_z q(z) \log q(z) - \sum_z q(z) \log \frac {p(z, x)}{p(x)} \\ & = \sum_z q(z) \log q(z) - \sum_z q(z) \log p(z, x) + \sum_z q(z) \log p(x) \\ & = \sum_z q(z) \log q(z) - \sum_z q(z) \log p(z, x) + \log p(x) \\ & = \log p(x) -\{ E_q[\log p(x,z)] - E_q[\log q(z)] \} \end{aligned} KL(q(z)∣∣p(z∣x))=z∑q(z)logp(z∣x)q(z)=z∑q(z)logq(z)−z∑q(z)log(p(z∣x))=z∑q(z)logq(z)−z∑q(z)logp(x)p(z,x)=z∑q(z)logq(z)−z∑q(z)logp(z,x)+z∑q(z)logp(x)=z∑q(z)logq(z)−z∑q(z)logp(z,x)+logp(x)=logp(x)−{Eq[logp(x,z)]−Eq[logq(z)]}
因为KL散度是大于等于0,但且仅当两个分布一致时位0,所以可以得到:
log p ( x ) ≥ E q [ log p s ( x , z ) ] − E q [ log q ( z ) ] \log p(x) \ge E_q[\log ps(x,z)] - E_q[\log q(z)] logp(x)≥Eq[logps(x,z)]−Eq[logq(z)]
不等式右断是左端的下界,左端称为证据(evidence),有端称为证据下界(evidence lower bound, ELBO),记做:
L ( q ) = E q [ log p ( x , z ) ] − E q [ log q ( z ) ] L(q) = E_q[\log p(x,z)] - E_q[\log q(z)] L(q)=Eq[logp(x,z)]−Eq[logq(z)]
因为 x x x是观测量,所以 p ( x ) p(x) p(x)是定值,所以通过求解证据下界的最大化来求取 q ( z ) q(z) q(z),因为证据下界越大,越靠近 p ( x ) p(x) p(x),BL散度越小,说明 q ( z ) q(z) q(z)和 p ( z ∣ x ) p(z|x) p(z∣x)的分布越接近。
其实证据下界也可以由Jensen不等式得到,如下推导:
log p ( x ) = log ∫ z p ( x , z ) d z = log ∫ z p ( x , z ) q ( z ) q ( z ) d z = log ∫ z q ( z ) p ( z , x ) q ( z ) d z = log [ E q p ( x , z ) q ( z ) ] ≥ E q [ log p ( x , z ) q ( z ) ] = E q [ log p ( x , z ) ] − E q [ log q ( z ) ] \begin{aligned} \log p(x) & = \log \int_z p(x, z) d z \\ & = \log \int_z p(x, z) \frac {q(z)} {q(z)} d z \\ & = \log \int_z q(z) \frac {p(z,x)} {q(z)} d z \\ & = \log [E_q \frac{p(x,z)}{q(z)}] \\ & \ge E_q[\log \frac {p(x,z)} {q(z)}] \\ &= E_q[\log p(x,z)] - E_q[\log q(z)] \end{aligned} logp(x)=log∫zp(x,z)dz=log∫zp(x,z)q(z)q(z)dz=log∫zq(z)q(z)p(z,x)dz=log[Eqq(z)p(x,z)]≥Eq[logq(z)p(x,z)]=Eq[logp(x,z)]−Eq[logq(z)]
通常假设 q ( z ) q(z) q(z)对 z z z的所有分量都是相互独立的(实际是条件独立于参数),即满足
q ( z ) = q ( z 1 ) q ( z 2 ) . . . q ( z n ) q(z) = q(z_1)q(z_2)...q(z_n) q(z)=q(z1)q(z2)...q(zn)
这时的变分分布称为平均场(mean filed).
2. LDA的EM算法推导
2.1 证据下界的定义
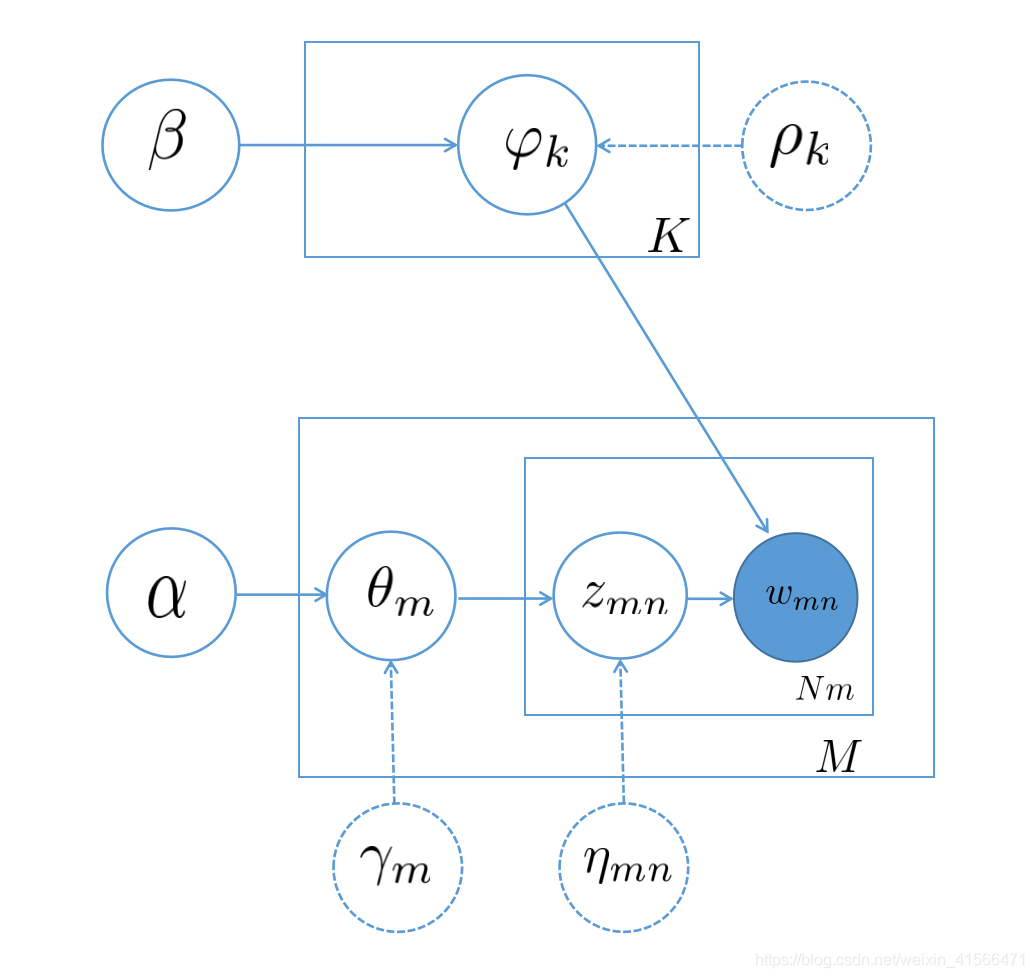
如上图所示,实线圈是LDA的模型参数,而虚线圈代表了变分参数。
和上一章节的参数一致,随机变量 w , z , θ , φ w, z, \theta, \varphi w,z,θ,φ的联合概率分布是:
p ( w , z , θ , φ ∣ α , β ) = p ( θ ∣ α ) p ( φ ∣ β ) p ( z ∣ θ ) p ( w ∣ z , φ ) p(w, z,\theta, \varphi | \alpha, \beta) = p(\theta|\alpha) p(\varphi|\beta) p(z|\theta) p(w|z,\varphi) p(w,z,θ,φ∣α,β)=p(θ∣α)p(φ∣β)p(z∣θ)p(w∣z,φ)
其中 w w w是可观测变量, θ , φ , z \theta, \varphi, z θ,φ,z是隐变量, α , β \alpha, \beta α,β是参数。
定义基于平均场的变分分布
q ( θ , φ , z ∣ γ , ρ , η ) = q ( θ ∣ γ ) q ( φ ∣ ρ ) q ( z ∣ η ) q(\theta, \varphi, z| \gamma, \rho, \eta) = q(\theta| \gamma) q(\varphi|\rho) q(z| \eta) q(θ,φ,z∣γ,ρ,η)=q(θ∣γ)q(φ∣ρ)q(z∣η)
其中 γ , ρ \gamma, \rho γ,ρ分别是 θ , φ \theta, \varphi θ,φ的狄利克雷分布参数, η \eta η是 z z z的多项分布参数。
由此,可以得到文本的证据下界
L ( γ , η , ρ , α , β ) = E q [ log p ( w , z , θ , φ ∣ α , β ) ] − E q [ log p ( θ , φ , z ∣ γ , ρ , η ) ] L(\gamma,\eta,\rho,\alpha,\beta) = E_q[\log p(w, z,\theta, \varphi | \alpha, \beta)] - E_q[\log p(\theta, \varphi, z| \gamma, \rho, \eta)] L(γ,η,ρ,α,β)=Eq[logp(w,z,θ,φ∣α,β)]−Eq[logp(θ,φ,z∣γ,ρ,η)]
将上式展开
L ( γ , η , ρ , α , β ) = E q [ log p ( θ ∣ α ) ] + E q [ log p ( φ ∣ β ) ] + E q [ log p ( z ∣ θ ) ] + E q [ log p ( w ∣ z , φ ) ] − E q [ log q ( θ ∣ γ ) ] − E q [ log q ( φ ∣ ρ ) ] − E q [ log q ( z ∣ η ) ] L(\gamma,\eta,\rho,\alpha,\beta) = E_q[\log p(\theta|\alpha)] + E_q[\log p(\varphi|\beta)] + E_q[\log p(z|\theta)] + E_q[\log p(w|z,\varphi)] \\ - E_q[\log q(\theta| \gamma)] - E_q[\log q(\varphi|\rho)] - E_q[\log q(z| \eta)] L(γ,η,ρ,α,β)=Eq[logp(θ∣α)]+Eq[logp(φ∣β)]+Eq[logp(z∣θ)]+Eq[logp(w∣z,φ)]−Eq[logq(θ∣γ)]−Eq[logq(φ∣ρ)]−Eq[logq(z∣η)]
变分参数增加了各个隐变量之间的独立性
下面就是依据变分参数和模型参数将上面每一项展开
第一项:
E q [ log p ( θ ∣ α ) ] = E q [ log ∏ m = 1 M p ( θ m ∣ α ) ] = E q [ log ∏ m = 1 M Γ ( ∑ k = 1 K α k ) ∏ k = 1 K Γ ( α k ) ∏ k = 1 K θ m k α k − 1 ] = ∑ m = 1 M E q [ log Γ ( ∑ k = 1 K α k ) − ∑ k = 1 K log Γ ( α k ) + ∑ k = 1 K ( α k − 1 ) log θ m k ] = ∑ m = 1 M { log Γ ( ∑ k = 1 K α k ) − ∑ k = 1 K log Γ ( α k ) + ∑ k = 1 K ( α k − 1 ) E q [ log θ m k ] } = ∑ m = 1 M { log Γ ( ∑ k = 1 K α k ) − ∑ k = 1 K log Γ ( α k ) + ∑ k = 1 K ( α k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] } \begin{aligned} E_q[\log p(\theta|\alpha)] &= E_q[\log \prod_{m=1}^M p(\theta_m|\alpha)] \\ & = E_q[\log \prod_{m=1}^M \frac {\Gamma(\sum_{k=1}^K \alpha_k)} {\prod_{k=1}^K \Gamma(\alpha_k)} \prod_{k=1}^K \theta_{mk}^{\alpha_k-1} ] \\ & = \sum_{m=1}^M E_q[\log \Gamma(\sum_{k=1}^K \alpha_k) - \sum_{k=1}^K \log \Gamma(\alpha_k) + \sum_{k=1}^K (\alpha_k-1) \log \theta_{mk} ] \\ & = \sum_{m=1}^M \{\log \Gamma(\sum_{k=1}^K \alpha_k) - \sum_{k=1}^K \log \Gamma(\alpha_k) + \sum_{k=1}^K (\alpha_k-1)E_q[ \log \theta_{mk}] \} \\ &= \sum_{m=1}^M \{\log \Gamma(\sum_{k=1}^K \alpha_k) - \sum_{k=1}^K \log \Gamma(\alpha_k) + \sum_{k=1}^K (\alpha_k-1)[\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml})]\} \\ \end{aligned} Eq[logp(θ∣α)]=Eq[logm=1∏Mp(θm∣α)]=Eq[logm=1∏M∏k=1KΓ(αk)Γ(∑k=1Kαk)k=1∏Kθmkαk−1]=m=1∑MEq[logΓ(k=1∑Kαk)−k=1∑KlogΓ(αk)+k=1∑K(αk−1)logθmk]=m=1∑M{logΓ(k=1∑Kαk)−k=1∑KlogΓ(αk)+k=1∑K(αk−1)Eq[logθmk]}=m=1∑M{logΓ(k=1∑Kαk)−k=1∑KlogΓ(αk)+k=1∑K(αk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)]}
其中 Ψ \Psi Ψ是digamma函数,是对数伽马函数的一阶导数。
第二项:
E q [ log p ( φ ∣ β ) ] = E q [ log ∏ k = 1 K p ( φ k ∣ β ) ] = E q [ log ∏ k = 1 K Γ ( ∑ v = 1 V β v ) ∏ v = 1 V Γ ( β v ) ∏ v = 1 V φ k v β v − 1 ] = ∑ k = 1 K E q [ log Γ ( ∑ v = 1 V β v ) − ∑ v = 1 V log Γ ( β v ) + ∑ v = 1 V ( β v − 1 ) log φ k v ] = ∑ k = 1 K { log Γ ( ∑ v = 1 V β v ) − ∑ v = 1 V log Γ ( β v ) + ∑ v = 1 V ( β v − 1 ) E q [ log φ k v ] } = ∑ k = 1 K { log Γ ( ∑ v = 1 V β v ) − ∑ v = 1 V log Γ ( β v ) + ∑ v = 1 V ( β v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] } \begin{aligned} E_q[\log p(\varphi|\beta)] &= E_q[\log \prod_{k=1}^K p(\varphi_k|\beta)] \\ & =E_q[\log \prod_{k=1}^K \frac {\Gamma (\sum_{v=1}^V \beta_v)} {\prod_{v=1}^V \Gamma(\beta_v)} \prod_{v=1}^V \varphi_{kv}^{\beta_v-1}] \\ &= \sum_{k=1}^K E_q[\log \Gamma (\sum_{v=1}^V \beta_v) - \sum_{v=1}^V \log \Gamma(\beta_v) + \sum_{v=1}^V (\beta_v -1) \log \varphi_{kv}] \\ &= \sum_{k=1}^K \{ \log \Gamma (\sum_{v=1}^V \beta_v) - \sum_{v=1}^V \log \Gamma(\beta_v) + \sum_{v=1}^V (\beta_v -1) E_q[ \log \varphi_{kv}] \}\\ &= \sum_{k=1}^K \{ \log \Gamma (\sum_{v=1}^V \beta_v) - \sum_{v=1}^V \log \Gamma(\beta_v) + \sum_{v=1}^V (\beta_v -1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \}\\ \end{aligned} Eq[logp(φ∣β)]=Eq[logk=1∏Kp(φk∣β)]=Eq[logk=1∏K∏v=1VΓ(βv)Γ(∑v=1Vβv)v=1∏Vφkvβv−1]=k=1∑KEq[logΓ(v=1∑Vβv)−v=1∑VlogΓ(βv)+v=1∑V(βv−1)logφkv]=k=1∑K{logΓ(v=1∑Vβv)−v=1∑VlogΓ(βv)+v=1∑V(βv−1)Eq[logφkv]}=k=1∑K{logΓ(v=1∑Vβv)−v=1∑VlogΓ(βv)+v=1∑V(βv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]}
第三项:
E q [ log p ( z ∣ θ ) ] = E q [ log ∏ m = 1 M ∏ n = 1 N m ∏ k = 1 K θ m k I ( z m n = k ) ] = ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 E q [ I ( z m n = k ) ] E q [ log θ m k ] = ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 η m n k E q [ log θ m k ] = ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 η m n k { Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) } \begin{aligned} E_q[\log p(z|\theta)] &= E_q[\log \prod_{m=1}^M \prod_{n=1}^{N_m} \prod_{k=1}^K \theta_{mk}^{I(z_{mn} =k)}] \\ & = \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1} E_q[I(z_{mn} =k)] E_q[\log \theta_{mk}] \\ & = \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1} \eta_{mnk} E_q[\log \theta_{mk}] \\ & = \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1} \eta_{mnk} \{\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \} \end{aligned} Eq[logp(z∣θ)]=Eq[logm=1∏Mn=1∏Nmk=1∏KθmkI(zmn=k)]=m=1∑Mn=1∑Nmk=1∑Eq[I(zmn=k)]Eq[logθmk]=m=1∑Mn=1∑Nmk=1∑ηmnkEq[logθmk]=m=1∑Mn=1∑Nmk=1∑ηmnk{Ψ(γmk)−Ψ(l=1∑Kγml)}
第四项:
E q [ log p ( w ∣ z , φ ) ] = E q [ log ∏ m = 1 M ∏ n = 1 N m ∏ v = 1 V ∏ k = 1 K φ k v I ( z m n = k , w m n = v ) ] = E q [ ∑ m = 1 M ∑ n = 1 N m ∑ v = 1 V ∑ k = 1 K I ( z m n = k , w m n = v ) log φ k v ] = ∑ m = 1 M ∑ n = 1 N m ∑ v = 1 V ∑ k = 1 K I ( z m n = k , ) I ( w m n = v ) E q [ log φ k v ] = ∑ m = 1 M ∑ n = 1 N m ∑ v = 1 V ∑ k = 1 K η n m k w m n v [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] \begin{aligned} E_q[\log p(w|z,\varphi)] &= E_q[\log \prod_{m=1}^M \prod_{n=1}^{N_m} \prod_{v=1}^V \prod_{k=1}^K \varphi_{kv} ^{I(z_{mn}=k, w_{mn}=v)}]\\ & = E_q[ \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{v=1}^V \sum_{k=1}^K I(z_{mn}=k, w_{mn}=v) \log \varphi_{kv}]\\ & = \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{v=1}^V \sum_{k=1}^K I(z_{mn}=k,) I(w_{mn}=v) E_q[\log \varphi_{kv}] \\ &= \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{v=1}^V \sum_{k=1}^K \eta_{nmk} w_{mn}^v [\Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})] \\ \end{aligned} Eq[logp(w∣z,φ)]=Eq[logm=1∏Mn=1∏Nmv=1∏Vk=1∏KφkvI(zmn=k,wmn=v)]=Eq[m=1∑Mn=1∑Nmv=1∑Vk=1∑KI(zmn=k,wmn=v)logφkv]=m=1∑Mn=1∑Nmv=1∑Vk=1∑KI(zmn=k,)I(wmn=v)Eq[logφkv]=m=1∑Mn=1∑Nmv=1∑Vk=1∑Kηnmkwmnv[Ψ(ρkv)−Ψ(s=1∑Vρks)]
第五项:
E q [ log q ( θ ∣ γ ) ] = E q [ log ∏ m = 1 M q ( θ m ∣ γ m ) ] = E q [ log ∏ m = 1 M Γ ( ∑ k = 1 K γ m k ) ∏ k = 1 K Γ ( γ m k ) ∏ k = 1 K θ m k γ m k − 1 ] = ∑ m = 1 M E q [ log Γ ( ∑ k = 1 K γ m k ) − ∑ k = 1 K log Γ ( γ m k ) + ∑ k = 1 K ( γ m k − 1 ) log θ m k ] = ∑ m = 1 M { log Γ ( ∑ k = 1 K γ m k ) − ∑ k = 1 K log Γ ( γ m k ) + ∑ k = 1 K ( γ m k − 1 ) E q [ log θ m k ] } = ∑ m = 1 M { log Γ ( ∑ k = 1 K γ m k ) − ∑ k = 1 K log Γ ( γ m k ) + ∑ k = 1 K ( γ m k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] } \begin{aligned} E_q[\log q(\theta| \gamma)] &= E_q[\log \prod_{m=1}^M q(\theta_m|\gamma_m)] \\ & = E_q[\log \prod_{m=1}^M \frac {\Gamma(\sum_{k=1}^K \gamma_{mk})} {\prod_{k=1}^K \Gamma(\gamma_{mk})} \prod_{k=1}^K \theta_{mk}^{\gamma_{mk} - 1}] \\ &=\sum_{m=1}^M E_q[\log \Gamma(\sum_{k=1}^K \gamma_{mk}) - \sum_{k=1}^K \log \Gamma (\gamma_{mk}) + \sum_{k=1}^K (\gamma_{mk} - 1) \log \theta_{mk}] \\ &= \sum_{m=1}^M \{ \log \Gamma(\sum_{k=1}^K \gamma_{mk}) - \sum_{k=1}^K \log \Gamma (\gamma_{mk}) + \sum_{k=1}^K (\gamma_{mk} - 1) E_q[\log \theta_{mk}] \}\\ &= \sum_{m=1}^M \{ \log \Gamma(\sum_{k=1}^K \gamma_{mk}) - \sum_{k=1}^K \log \Gamma (\gamma_{mk}) + \sum_{k=1}^K (\gamma_{mk} - 1) [\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml})] \}\\ \end{aligned} Eq[logq(θ∣γ)]=Eq[logm=1∏Mq(θm∣γm)]=Eq[logm=1∏M∏k=1KΓ(γmk)Γ(∑k=1Kγmk)k=1∏Kθmkγmk−1]=m=1∑MEq[logΓ(k=1∑Kγmk)−k=1∑KlogΓ(γmk)+k=1∑K(γmk−1)logθmk]=m=1∑M{logΓ(k=1∑Kγmk)−k=1∑KlogΓ(γmk)+k=1∑K(γmk−1)Eq[logθmk]}=m=1∑M{logΓ(k=1∑Kγmk)−k=1∑KlogΓ(γmk)+k=1∑K(γmk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)]}
第六项:
E q [ log q ( φ ∣ ρ ) ] = E q [ log ∏ k = 1 K q ( φ k ) ∣ ρ k ] = E q [ log ∏ k = 1 K Γ ( ∑ v = 1 V ρ k v ) ∏ v = 1 V Γ ( ρ k v ) ∏ v = 1 V φ k v ρ k v − 1 ] = ∑ k = 1 K E q [ log Γ ( ∑ v = 1 V ρ k v ) − ∑ v = 1 V log Γ ( ρ k v ) + ∑ v = 1 V ( ρ k v − 1 ) log φ k v ] = ∑ k = 1 K { log Γ ( ∑ v = 1 V ρ k v ) − ∑ v = 1 V log Γ ( ρ k v ) + ∑ v = 1 V ( ρ k v − 1 ) E q [ log φ k v ] } = ∑ k = 1 K { log Γ ( ∑ v = 1 V ρ k v ) − ∑ v = 1 V log Γ ( ρ k v ) + ∑ v = 1 V ( ρ k v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] } \begin{aligned} E_q[\log q(\varphi|\rho)] &= E_q[\log \prod_{k=1}^K q(\varphi_k)| \rho_k] \\ & = E_q[\log \prod_{k=1}^K \frac {\Gamma (\sum_{v=1}^V \rho_{kv})} {\prod_{v=1}^V \Gamma(\rho_{kv})} \prod_{v=1}^V \varphi_{kv}^{\rho_{kv}-1}] \\ & = \sum_{k=1}^K E_q[\log \Gamma (\sum_{v=1}^V \rho_{kv}) - \sum_{v=1}^V \log \Gamma(\rho_{kv}) + \sum_{v=1}^V (\rho_{kv}-1) \log \varphi_{kv}] \\ &= \sum_{k=1}^K \{\log \Gamma (\sum_{v=1}^V \rho_{kv}) - \sum_{v=1}^V \log \Gamma(\rho_{kv}) + \sum_{v=1}^V (\rho_{kv}-1) E_q[\log \varphi_{kv}] \} \\ &= \sum_{k=1}^K \{\log \Gamma (\sum_{v=1}^V \rho_{kv}) - \sum_{v=1}^V \log \Gamma(\rho_{kv}) + \sum_{v=1}^V (\rho_{kv}-1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \} \\ \end{aligned} Eq[logq(φ∣ρ)]=Eq[logk=1∏Kq(φk)∣ρk]=Eq[logk=1∏K∏v=1VΓ(ρkv)Γ(∑v=1Vρkv)v=1∏Vφkvρkv−1]=k=1∑KEq[logΓ(v=1∑Vρkv)−v=1∑VlogΓ(ρkv)+v=1∑V(ρkv−1)logφkv]=k=1∑K{logΓ(v=1∑Vρkv)−v=1∑VlogΓ(ρkv)+v=1∑V(ρkv−1)Eq[logφkv]}=k=1∑K{logΓ(v=1∑Vρkv)−v=1∑VlogΓ(ρkv)+v=1∑V(ρkv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]}
第七项:
E q [ log q ( z ∣ η ) ] = E q [ log ∏ m = 1 M ∏ n = 1 N m q ( z m n ∣ η m n ) ] = E q [ log ∏ m = 1 M ∏ n = 1 N m ∏ k = 1 K η m n k I ( z m n = k ) ] = ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 K E q [ I ( z m n = k ) ] E q [ log η m n k ] = ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 K η m n k log η m n k \begin{aligned} E_q[\log q(z| \eta)] &= E_q[\log \prod_{m=1}^M \prod_{n=1}^{N_m} q(z_{mn}|\eta_{mn})]\\ & = E_q[\log \prod_{m=1}^M \prod_{n=1}^{N_m} \prod_{k=1}^K \eta_{mnk}^{I(z_{mn}=k)}]\\ & = \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1}^K E_q[I(z_{mn}=k)] E_q[\log \eta_{mnk}] \\ & = \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1}^K \eta_{mnk} \log \eta_{mnk} \end{aligned} Eq[logq(z∣η)]=Eq[logm=1∏Mn=1∏Nmq(zmn∣ηmn)]=Eq[logm=1∏Mn=1∏Nmk=1∏KηmnkI(zmn=k)]=m=1∑Mn=1∑Nmk=1∑KEq[I(zmn=k)]Eq[logηmnk]=m=1∑Mn=1∑Nmk=1∑Kηmnklogηmnk
将上面的公式带入证据下界
L ( γ , η , ρ , α , β ) = E q [ log p ( θ ∣ α ) ] + E q [ log p ( φ ∣ β ) ] + E q [ log p ( z ∣ θ ) ] + E q [ log p ( w ∣ z , φ ) ] − E q [ log q ( θ ∣ γ ) ] − E q [ log q ( φ ∣ ρ ) ] − E q [ log q ( z ∣ η ) ] = ∑ m = 1 M { log Γ ( ∑ k = 1 K α k ) − ∑ k = 1 K log Γ ( α k ) + ∑ k = 1 K ( α k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] } + ∑ k = 1 K { log Γ ( ∑ v = 1 V β v ) − ∑ v = 1 V log Γ ( β v ) + ∑ v = 1 V ( β v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] } + ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 K η m n k { Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) } + ∑ m = 1 M ∑ n = 1 N m ∑ v = 1 V ∑ k = 1 K η n m k w m n v [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] − ∑ m = 1 M { log Γ ( ∑ k = 1 K γ m k ) − ∑ k = 1 K log Γ ( γ m k ) + ∑ k = 1 K ( γ m k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] } − ∑ k = 1 K { log Γ ( ∑ v = 1 V ρ k v ) − ∑ v = 1 V log Γ ( ρ k v ) + ∑ v = 1 V ( ρ k v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] } − ∑ m = 1 M ∑ n = 1 N m ∑ k = 1 K η m n k log η m n k \begin{aligned} L(\gamma,\eta,\rho,\alpha,\beta) &= E_q[\log p(\theta|\alpha)] + E_q[\log p(\varphi|\beta)] + E_q[\log p(z|\theta)] + E_q[\log p(w|z,\varphi)] \\ &- E_q[\log q(\theta| \gamma)] - E_q[\log q(\varphi|\rho)] - E_q[\log q(z| \eta)] \\ & = \sum_{m=1}^M \{\log \Gamma(\sum_{k=1}^K \alpha_k) - \sum_{k=1}^K \log \Gamma(\alpha_k) + \sum_{k=1}^K (\alpha_k-1)[\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml})]\} \\ &+ \sum_{k=1}^K \{ \log \Gamma (\sum_{v=1}^V \beta_v) - \sum_{v=1}^V \log \Gamma(\beta_v) + \sum_{v=1}^V (\beta_v -1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \}\\ & + \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1}^K \eta_{mnk} \{\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \} \\ & + \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{v=1}^V \sum_{k=1}^K \eta_{nmk} w_{mn}^v [\Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})] \\ & - \sum_{m=1}^M \{ \log \Gamma(\sum_{k=1}^K \gamma_{mk}) - \sum_{k=1}^K \log \Gamma (\gamma_{mk}) + \sum_{k=1}^K (\gamma_{mk} - 1) [\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml})] \}\\ & - \sum_{k=1}^K \{\log \Gamma (\sum_{v=1}^V \rho_{kv}) - \sum_{v=1}^V \log \Gamma(\rho_{kv}) + \sum_{v=1}^V (\rho_{kv}-1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \} \\ & - \sum_{m=1}^M \sum_{n=1}^{N_m} \sum_{k=1}^K \eta_{mnk} \log \eta_{mnk} \end{aligned} L(γ,η,ρ,α,β)=Eq[logp(θ∣α)]+Eq[logp(φ∣β)]+Eq[logp(z∣θ)]+Eq[logp(w∣z,φ)]−Eq[logq(θ∣γ)]−Eq[logq(φ∣ρ)]−Eq[logq(z∣η)]=m=1∑M{logΓ(k=1∑Kαk)−k=1∑KlogΓ(αk)+k=1∑K(αk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)]}+k=1∑K{logΓ(v=1∑Vβv)−v=1∑VlogΓ(βv)+v=1∑V(βv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]}+m=1∑Mn=1∑Nmk=1∑Kηmnk{Ψ(γmk)−Ψ(l=1∑Kγml)}+m=1∑Mn=1∑Nmv=1∑Vk=1∑Kηnmkwmnv[Ψ(ρkv)−Ψ(s=1∑Vρks)]−m=1∑M{logΓ(k=1∑Kγmk)−k=1∑KlogΓ(γmk)+k=1∑K(γmk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)]}−k=1∑K{logΓ(v=1∑Vρkv)−v=1∑VlogΓ(ρkv)+v=1∑V(ρkv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]}−m=1∑Mn=1∑Nmk=1∑Kηmnklogηmnk
2.2 变分参数的估计
-
求 γ m k \gamma_{mk} γmk:
先抽取证据下界中含有 γ m k \gamma_{mk} γmk的项L ( γ m k ) = ( α k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) + ∑ n = 1 N m η m n k { Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) − log Γ ( ∑ k = 1 K γ m k ) + log Γ ( γ m k ) − ( γ m k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] \begin{aligned} L(\gamma_{mk}) = & (\alpha_k-1)[\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \\ & + \sum_{n=1}^{N_m} \eta_{mnk} \{\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \\ & - \log \Gamma(\sum_{k=1}^K \gamma_{mk}) + \log \Gamma (\gamma_{mk}) - (\gamma_{mk} - 1) [\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml})] \end{aligned} L(γmk)=(αk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)+n=1∑Nmηmnk{Ψ(γmk)−Ψ(l=1∑Kγml)−logΓ(k=1∑Kγmk)+logΓ(γmk)−(γmk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)]
求导:
∂ L ( γ m k ) ∂ γ m k = ( α k − 1 ) [ Ψ ′ ( γ m k ) − Ψ ′ ( ∑ l = 1 K γ m l ) ] + ∑ n = 1 N m η m n k { Ψ ′ ( γ m k ) − Ψ ′ ( ∑ l = 1 K γ m l ) − Ψ ( ∑ l = 1 K γ m l ) + Ψ ( γ m k ) − ( γ m k − 1 ) [ Ψ ′ ( γ m k ) − Ψ ′ ( ∑ l = 1 K γ m l ) ] − Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) = [ ( α k − 1 ) + ∑ n = 1 N m η m n k − ( γ m k − 1 ) ] [ Ψ ′ ( γ m k ) − Ψ ′ ( ∑ l = 1 K γ m l ) ] \begin{aligned} \frac {\partial L(\gamma_{mk})} {\partial \gamma_{mk}} = & (\alpha_k-1)[\Psi'(\gamma_{mk}) - \Psi'(\sum_{l=1}^K \gamma_{ml})] \\ & + \sum_{n=1}^{N_m} \eta_{mnk} \{\Psi'(\gamma_{mk}) - \Psi'(\sum_{l=1}^K \gamma_{ml}) \\ & - \Psi(\sum_{l=1}^K \gamma_{ml})+ \Psi(\gamma_{mk}) \\ &- (\gamma_{mk} - 1) [\Psi'(\gamma_{mk}) - \Psi'(\sum_{l=1}^K \gamma_{ml})] \\ & - \Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \\ & = [(\alpha_k-1) + \sum_{n=1}^{N_m} \eta_{mnk}- (\gamma_{mk} - 1) ] [\Psi'(\gamma_{mk}) - \Psi'(\sum_{l=1}^K \gamma_{ml})] \end{aligned} ∂γmk∂L(γmk)=(αk−1)[Ψ′(γmk)−Ψ′(l=1∑Kγml)]+n=1∑Nmηmnk{Ψ′(γmk)−Ψ′(l=1∑Kγml)−Ψ(l=1∑Kγml)+Ψ(γmk)−(γmk−1)[Ψ′(γmk)−Ψ′(l=1∑Kγml)]−Ψ(γmk)−Ψ(l=1∑Kγml)=[(αk−1)+n=1∑Nmηmnk−(γmk−1)][Ψ′(γmk)−Ψ′(l=1∑Kγml)]
令上式为零,又有 Ψ ′ ( γ m k ) − Ψ ′ ( ∑ l = 1 K γ m l ) ≠ 0 \Psi'(\gamma_{mk}) - \Psi'(\sum_{l=1}^K \gamma_{ml}) \ne 0 Ψ′(γmk)−Ψ′(∑l=1Kγml)=0,故
( α k − 1 ) + ∑ n = 1 N m η m n k − ( γ m k − 1 ) = 0 (\alpha_k-1) + \sum_{n=1}^{N_m}\eta_{mnk} - (\gamma_{mk} - 1) = 0 (αk−1)+n=1∑Nmηmnk−(γmk−1)=0
解得:
γ m k = α k + ∑ n = 1 N m η m n k \gamma_{mk} = \alpha_k + \sum_{n=1}^{N_m} \eta_{mnk} γmk=αk+n=1∑Nmηmnk
-
求 ρ k v \rho_{kv} ρkv:
先抽取证据下界中含有 ρ k v \rho_{kv} ρkv的项L ( ρ k v ) = ( β v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] + ∑ m = 1 M ∑ n = 1 N m η n m k w m n v [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] − log Γ ( ∑ v = 1 V ρ k v ) + log Γ ( ρ k v ) − ( ρ k v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] \begin{aligned} L(\rho_{kv}) &= (\beta_v -1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \\ & + \sum_{m=1}^M \sum_{n=1}^{N_m} \eta_{nmk} w_{mn}^v [\Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})] \\ & - \log \Gamma (\sum_{v=1}^V \rho_{kv}) + \log \Gamma(\rho_{kv}) - (\rho_{kv}-1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \\ \end{aligned} L(ρkv)=(βv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]+m=1∑Mn=1∑Nmηnmkwmnv[Ψ(ρkv)−Ψ(s=1∑Vρks)]−logΓ(v=1∑Vρkv)+logΓ(ρkv)−(ρkv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]
求导:
∂ L ( ρ k v ) ∂ ρ k v = ( β v − 1 ) [ Ψ ′ ( ρ k v ) − Ψ ′ ( ∑ s = 1 V ρ k s ) ] + ∑ m = 1 M ∑ n = 1 N m η n m k w m n v [ Ψ ′ ( ρ k v ) − Ψ ′ ( ∑ s = 1 V ρ k s ) ] − Ψ ( ∑ s = 1 V ρ k s ) + Ψ ( ρ k v ) − ( ρ k v − 1 ) [ Ψ ′ ( ρ k v ) − Ψ ′ ( ∑ s = 1 V ρ k s ) ] − Ψ ( ρ k v ) + Ψ ( ∑ s = 1 V ρ k s ) = [ ( β v − 1 ) + ∑ m = 1 M ∑ n = 1 N m η n m k w m n v − ( ρ k v − 1 ) ] [ Ψ ′ ( ρ k v ) − Ψ ′ ( ∑ s = 1 V ρ k s ) ] = 0 \begin{aligned} \frac {\partial L(\rho_{kv})} {\partial \rho_{kv}} &= (\beta_v -1) [\Psi'(\rho_{kv} )- \Psi'( \sum_{s=1}^V \rho_{ks} ) ] \\ & + \sum_{m=1}^M \sum_{n=1}^{N_m} \eta_{nmk} w_{mn}^v [\Psi'(\rho_{kv}) - \Psi'(\sum_{s=1}^V \rho_{ks})] \\ & - \Psi( \sum_{s=1}^V \rho_{ks} ) + \Psi(\rho_{kv} ) - (\rho_{kv}-1) [\Psi'(\rho_{kv} )- \Psi'( \sum_{s=1}^V \rho_{ks} ) ] \\ & - \Psi(\rho_{kv} )+ \Psi( \sum_{s=1}^V \rho_{ks} ) \\ & = [(\beta_v -1) + \sum_{m=1}^M \sum_{n=1}^{N_m} \eta_{nmk} w_{mn}^v - (\rho_{kv}-1)] [\Psi'(\rho_{kv}) - \Psi'(\sum_{s=1}^V \rho_{ks})] \\ & = 0 \end{aligned} ∂ρkv∂L(ρkv)=(βv−1)[Ψ′(ρkv)−Ψ′(s=1∑Vρks)]+m=1∑Mn=1∑Nmηnmkwmnv[Ψ′(ρkv)−Ψ′(s=1∑Vρks)]−Ψ(s=1∑Vρks)+Ψ(ρkv)−(ρkv−1)[Ψ′(ρkv)−Ψ′(s=1∑Vρks)]−Ψ(ρkv)+Ψ(s=1∑Vρks)=[(βv−1)+m=1∑Mn=1∑Nmηnmkwmnv−(ρkv−1)][Ψ′(ρkv)−Ψ′(s=1∑Vρks)]=0
因为 Ψ ′ ( ρ k v ) − Ψ ′ ( ∑ s = 1 V ρ k s ) ≠ 0 \Psi'(\rho_{kv}) - \Psi'(\sum_{s=1}^V \rho_{ks}) \ne 0 Ψ′(ρkv)−Ψ′(∑s=1Vρks)=0,所以得到:
ρ k v = β v + ∑ m = 1 M ∑ n = 1 N m η n m k w m n v \rho_{kv} = \beta_v + \sum_{m=1}^M \sum_{n=1}^{N_m} \eta_{nmk} w_{mn}^v ρkv=βv+m=1∑Mn=1∑Nmηnmkwmnv
-
求 η m n k \eta_{mnk} ηmnk
先抽取证据下界中含有 η m n k \eta_{mnk} ηmnk的项,又因为 ∑ k = 1 K η m n k = 1 \sum_{k=1}^K \eta_{mnk} = 1 ∑k=1Kηmnk=1, 所以有约束的最优化问题拉格朗日函数为L ( η m n k ) = η m n k { Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) } + ∑ v = 1 V η n m k w m n v [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] − η m n k log η m n k + λ ( η m n k − 1 ) \begin{aligned} L(\eta_{mnk}) & = \eta_{mnk} \{\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \} \\ & + \sum_{v=1}^V \eta_{nmk} w_{mn}^v [\Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})] \\ & - \eta_{mnk} \log \eta_{mnk} \\ & + \lambda(\eta_{mnk} - 1) \end{aligned} L(ηmnk)=ηmnk{Ψ(γmk)−Ψ(l=1∑Kγml)}+v=1∑Vηnmkwmnv[Ψ(ρkv)−Ψ(s=1∑Vρks)]−ηmnklogηmnk+λ(ηmnk−1)
求导
∂ L ( η m n k ) ∂ η m n k = Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) + ∑ v = 1 V w m n v Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) − 1 − log η m n k + λ = 0 \begin{aligned} \frac {\partial L(\eta_{mnk})} {\partial \eta_{mnk}} & = \Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml}) \\ & + \sum_{v=1}^V w_{mn}^v \Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks}) \\ & - 1 - \log \eta_{mnk} + \lambda \\ & = 0 \end{aligned} ∂ηmnk∂L(ηmnk)=Ψ(γmk)−Ψ(l=1∑Kγml)+v=1∑VwmnvΨ(ρkv)−Ψ(s=1∑Vρks)−1−logηmnk+λ=0
则:
log η m n k = [ Ψ ( γ m k ) + ∑ v = 1 V w m n v Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ) ] + [ λ − 1 − Ψ ( ∑ l = 1 K γ m l ) ] \log \eta_{mnk} = [\Psi(\gamma_{mk}) + \sum_{v=1}^V w_{mn}^v \Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})) ] + [\lambda -1 - \Psi(\sum_{l=1}^K \gamma_{ml})] logηmnk=[Ψ(γmk)+v=1∑VwmnvΨ(ρkv)−Ψ(s=1∑Vρks))]+[λ−1−Ψ(l=1∑Kγml)]
当 k k k变动时,后面一项不影响 η m n k \eta_{mnk} ηmnk,所以可以写作
η m n k ⋉ exp ( Ψ ( γ m k ) + ∑ v = 1 V w m n v Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ) \eta_{mnk} \ltimes \exp(\Psi(\gamma_{mk}) + \sum_{v=1}^V w_{mn}^v \Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})) ηmnk⋉exp(Ψ(γmk)+v=1∑VwmnvΨ(ρkv)−Ψ(s=1∑Vρks))
在具体实现过程中要对 η m n k \eta_{mnk} ηmnk归一化处理。
2.3 模型参数的估计
-
求 α k \alpha_k αk
先抽取证据下界中含有 α k \alpha_k αk的项L ( α k ) = ∑ m = 1 M { log Γ ( ∑ k = 1 K α k ) − log Γ ( α k ) + ( α k − 1 ) [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] } L(\alpha_k) = \sum_{m=1}^M \{\log \Gamma(\sum_{k=1}^K \alpha_k) - \log \Gamma(\alpha_k) + (\alpha_k-1)[\Psi(\gamma_{mk}) - \Psi(\sum_{l=1}^K \gamma_{ml})]\} L(αk)=m=1∑M{logΓ(k=1∑Kαk)−logΓ(αk)+(αk−1)[Ψ(γmk)−Ψ(l=1∑Kγml)]}
求偏导得
∂ L ( α k ) α k = M [ Ψ ( ∑ l = 1 K α l ) − Ψ ( α k ) ] + ∑ m = 1 M [ Ψ ( γ m k ) − Ψ ( ∑ l = 1 K γ m l ) ] \frac {\partial L(\alpha_k)} {\alpha_k} = M[\Psi(\sum_{l=1}^K \alpha_l) - \Psi(\alpha_k)] + \sum_{m=1}^M [\Psi (\gamma_{mk} ) - \Psi(\sum_{l=1}^K \gamma_{ml})] αk∂L(αk)=M[Ψ(l=1∑Kαl)−Ψ(αk)]+m=1∑M[Ψ(γmk)−Ψ(l=1∑Kγml)]
这个结果是 L L L对 α \alpha α得梯度 g ( α ) g(\alpha) g(α)
在对 α l \alpha_l αl求偏导得
∂ 2 L ∂ α k ∂ α l = M [ Ψ ′ ( ∑ l = 1 M α l ) − δ ( k , l ) Ψ ′ ( α k ) ] \frac {\partial^2 L} {\partial \alpha_k \partial \alpha_l} = M[\Psi'(\sum_{l=1}^M \alpha_l) - \delta(k, l) \Psi'(\alpha_k)] ∂αk∂αl∂2L=M[Ψ′(l=1∑Mαl)−δ(k,l)Ψ′(αk)]
这个结果是Hessian矩阵 H ( α ) H(\alpha) H(α)。
用以下公式迭代,得到参数 α \alpha α的估计值α n e w = α o l d − H ( α o l d ) − 1 g ( α o l d ) \alpha_{new} = \alpha_{old} - H(\alpha_{old})^{-1} g(\alpha_{old}) αnew=αold−H(αold)−1g(αold)
-
求 β v \beta_v βv
先抽取证据下界中含有 β v \beta_v βv的项L ( β v ) = ∑ k = 1 K { log Γ ( ∑ s = 1 V β s ) − log Γ ( β v ) + ( β v − 1 ) [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] } L(\beta_v) = \sum_{k=1}^K \{ \log \Gamma (\sum_{s=1}^V \beta_s) - \log \Gamma(\beta_v) + (\beta_v -1) [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] \} L(βv)=k=1∑K{logΓ(s=1∑Vβs)−logΓ(βv)+(βv−1)[Ψ(ρkv)−Ψ(s=1∑Vρks)]}
同样的
g ( β ) = ∂ L ∂ β k = K [ Ψ ( ∑ s = 1 V β s ) − Ψ ( β v ) ] + ∑ k = 1 K [ Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ] g(\beta) = \frac {\partial L} {\partial \beta_k} = K[\Psi(\sum_{s=1}^V \beta_s) - \Psi(\beta_v)] + \sum_{k=1}^K [\Psi(\rho_{kv} )- \Psi( \sum_{s=1}^V \rho_{ks} ) ] g(β)=∂βk∂L=K[Ψ(s=1∑Vβs)−Ψ(βv)]+k=1∑K[Ψ(ρkv)−Ψ(s=1∑Vρks)]
H ( β ) = ∂ L ∂ β v ∂ β s = K [ Ψ ′ ( ∑ s = 1 V β s ) − δ ( v , s ) Ψ ′ ( β v ) ] H(\beta) = \frac {\partial L} {\partial \beta_v \partial \beta_s} = K[\Psi'(\sum_{s=1}^V \beta_s) - \delta(v,s) \Psi'(\beta_v)] H(β)=∂βv∂βs∂L=K[Ψ′(s=1∑Vβs)−δ(v,s)Ψ′(βv)]
用以下公式迭代:
β n e w = β o l d − H ( β o l d ) − 1 g ( β o l d ) \beta_{new} = \beta_{old} - H(\beta_{old})^{-1}g(\beta_{old}) βnew=βold−H(βold)−1g(βold)
变分EM算法
E步:求解变分参数γ m k = α k + ∑ n = 1 N m η m n k \gamma_{mk} = \alpha_k + \sum_{n=1}^{N_m} \eta_{mnk} γmk=αk+n=1∑Nmηmnk
ρ k v = β v + ∑ m = 1 M ∑ n = 1 N m η n m k w m n v \rho_{kv} = \beta_v + \sum_{m=1}^M \sum_{n=1}^{N_m} \eta_{nmk} w_{mn}^v ρkv=βv+m=1∑Mn=1∑Nmηnmkwmnv
η m n k ⋉ exp ( Ψ ( γ m k ) + ∑ v = 1 V w m n v Ψ ( ρ k v ) − Ψ ( ∑ s = 1 V ρ k s ) ) \eta_{mnk} \ltimes \exp(\Psi(\gamma_{mk}) +\sum_{v=1}^V w_{mn}^v \Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks})) ηmnk⋉exp(Ψ(γmk)+v=1∑VwmnvΨ(ρkv)−Ψ(s=1∑Vρks))
M步: 求模型参数
α n e w = α o l d − H ( α o l d ) − 1 g ( α o l d ) \alpha_{new} = \alpha_{old} - H(\alpha_{old})^{-1} g(\alpha_{old}) αnew=αold−H(αold)−1g(αold)
β n e w = β o l d − H ( β o l d ) − 1 g ( β o l d ) \beta_{new} = \beta_{old} - H(\beta_{old})^{-1}g(\beta_{old}) βnew=βold−H(βold)−1g(βold)
3. LDA的python实现
代码实现变量名称与理论推导参数的对应关系
:param gamma:
γ
\gamma
γ
:param rho:
ρ
\rho
ρ
:param eta:
η
\eta
η
:param alpha:
α
\alpha
α
:param beta:
β
\beta
β
import numpy as np
from scipy.special import digamma, polygamma, gammaln
from copy import deepcopy
class LDAEM(object):
def __init__(self, K=3):
"""
变分EM算法实现LDA模型
:param K: 主题个数,默认值为3
:param M: 文档个数
:param Nm: 第m个文档的单词个数
:param N: 文本单词个数列表,(M,)
:param V: 单词集合的个数
:param tockens: 单词tockens
:param gamma: 变分参数,对应文档主题,(M, K)
:param rho: 变分参数,对应单词主题,(K, V)
:param eta: 变分参数,对应文本中单词的主题(M, Nm, K)
:param alpha: 模型参数文档主题theta的参数,(K,)
:param beta: 模型参数单词主题varphi的参数,(V,)
"""
self.K = K
self.M = None
self.V = None
self.tockens = None
self.N = None
self.params = {
'gamma': None,
'rho': None,
'eta': None,
'alpha': None,
'beta': None
}
def _init_params(self):
"""
初始化参数
:return:
"""
# 初始化变分参数
# 约束条件sum_k gamma_mk = 1, 即对于第m个文档主题之和为1
gamma = np.random.dirichlet(100 * np.ones(self.K), self.M)
# 约束条件sum_v rho_kv = 1,即对于第k个主题,所有单词之和为1
rho = np.random.dirichlet(100 * np.ones(self.V), self.K)
# 约束条件 sum_k eta_mnk=1,即对于第m个文档,第n个单词,文档主题概率之和为1
eta = np.array([np.random.dirichlet(100 * np.ones(self.K), Nm) for Nm in self.N])
# 初始化模型参数
alpha = np.ones(self.K)
beta = np.ones(self.V)
self.params = {
'gamma': gamma,
'rho': rho,
'eta': eta,
'alpha': alpha,
'beta': beta
}
def _update_gamma(self):
"""
$$\gamma_{mk} = \alpha_k + \sum_{n=1}^{N_m} \eta_{mnk}$$
:return:
"""
alpha = deepcopy(self.params['alpha'])
eta = deepcopy(self.params['eta'])
# 预定义占位
gamma = np.zeros((self.M, self.K))
for m in range(self.M):
gamma[m] = alpha + np.sum(eta[m], axis=0)
# 归一化
gamma = np.array([gamma[:, k] / np.sum(gamma, axis=1) for k in range(self.K)]).T
return gamma
def _update_rho(self):
"""
$$\rho_{kv} = \beta_v + \sum_{m=1}^M \sum_{n=1}^{N_m} \eta_{nmk} w_{mn}^v $$
:return:
"""
beta = deepcopy(self.params['beta'])
eta = deepcopy(self.params['eta'])
rho = np.zeros((self.K, self.V))
for k in range(self.K):
for v in range(self.V):
sum_mn = 0
for m in range(self.M):
for n in range(self.N[m]):
sum_mn += eta[m][n][k] * (self.texts[m][n] == self.tockens[v])
rho[k][v] = sum_mn + beta[v]
# 归一化
rho = np.array([rho[k] / np.sum(rho[k]) for k in range(self.K)])
return rho
def _update_eta(self):
"""
$$\eta_{mnk} \ltimes \exp(\Psi(\gamma_{mk})
+\sum_{v=1}^V w_{mn}^v \Psi(\rho_{kv}) - \Psi(\sum_{s=1}^V \rho_{ks}))$$
计算中需要归一化
:return:
"""
gamma = deepcopy(self.params['gamma'])
rho = deepcopy(self.params['rho'])
eta = np.array([np.ones((n, self.K)) for n in self.N])
for m in range(self.M):
for n in range(self.N[m]):
sum_k = 0
eta_mn_k_list = np.zeros(self.K)
for k in range(self.K):
sum_digamma_rho_k = 0
for v in range(self.V):
sum_digamma_rho_k += digamma(rho[k][v]) * (self.tockens[v] == self.texts[m][n])
a = digamma(gamma[m][k]) + sum_digamma_rho_k + digamma(np.sum(rho[k]))
# 为了防止指数增长中的内存溢出,限定一个阈值
if a > 20:
a = 20
sum_k += np.exp(a)
eta_mn_k_list[k] = np.exp(a)
# 将k维度上的数据归一化后赋值
eta[m][n] = eta_mn_k_list / sum_k
return eta
def _E_step(self):
"""
更新变分参数,为了方便理解,将gamma,rho, eta分别计算
:return:
"""
# 更新gamma
gamma = self._update_gamma()
# 更新rho
rho = self._update_rho()
# 更新eta
eta = self._update_eta()
# 将结果写入
self.params['gamma'] = gamma
self.params['rho'] = rho
self.params['eta'] = eta
def _update_alpha(self, max_iter=1000, tol=0.1):
"""
$$\alpha_{new} = \alpha_{old} - H(\alpha_{old})^{-1} g(\alpha_{old})$$
其中g(alpha)是关于alpha的一阶导数
H(alpha)是关于alpha的Henssian矩阵
:return:
"""
alpha = deepcopy(self.params['alpha'])
gamma = deepcopy(self.params['gamma'])
for _ in range(max_iter):
alpha_old = alpha
# 计算alpha的一阶导数
# np.tile是将数据扩展
g = self.M * (digamma(np.sum(alpha)) - digamma(alpha)) + \
np.sum(
digamma(gamma) - np.tile(digamma(np.sum(gamma, axis=1)), (self.K, 1)).T,
axis=0
)
# 计算Hessen矩阵
h = -1 * self.M * polygamma(1, alpha)
z = self.M * polygamma(1, np.sum(alpha))
c = np.sum(g / h) / (z ** (-1.0) + np.sum(h ** (-1.0)))
# update alpha
alpha = alpha - (g - c) / h
# 设置终止条件
if np.sqrt(np.mean(np.square(alpha - alpha_old))) < tol:
break
return alpha
def _update_beta(self, max_iter=1000, tol=0.1):
"""
$$\beta_{new} = \beta_{old} - H(\beta_{old})^{-1}g(\beta_{old})$$
"""
beta = deepcopy(self.params['beta'])
rho = deepcopy(self.params['rho'])
for _ in range(max_iter):
beta_old = beta
g = self.K * (digamma(np.sum(beta)) - digamma(beta)) + \
np.sum(
digamma(rho) - np.tile(digamma(np.sum(rho, axis=1)), (self.V, 1)).T,
axis=0
)
h = -1 * self.K * polygamma(1, beta)
z = self.K * polygamma(1, np.sum(beta))
c = np.sum(g / h) / (z ** (-1.0) + np.sum(h ** (-1.0)))
beta = beta - (g - c) / h
if np.sqrt(np.mean(np.square(beta - beta_old))) < tol:
break
return beta
def _M_step(self):
"""
更新模型参数,alpha, beta
:return:
"""
# 更新alpha
alpha = self._update_alpha()
# 更新beta
beta = self._update_beta()
self.params['alpha'] = alpha
self.params['beta'] = beta
def fit(self, texts, tokens, max_iter=10):
"""
训练入口
:param texts:
:param tokens:
:param max_iter:
:return:
"""
self.M = len(texts)
self.tockens = tokens
self.V = len(tokens)
self.N = np.array([len(d) for d in texts])
self.texts = texts
self._init_params()
for i in range(max_iter):
print('iter: ', i + 1)
self._E_step()
self._M_step()

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









