







1.LSTM其实很好理解,在理解了RNN的基础上,继续理解GRU(多了两个门),LSTM也差不多;
在构建LSTM的时候,我们只需要关心两个参数:(input_size,超参数hidden_size)
第一次初始化后就再加上隐藏状态H[batch_size,hidden_size]
多少个batch,就是一次处理多少个样本,所以就有batch_size个H

构建LSTM:
1.每一个门都是 [input, hidden]这个是和X和H运算的;
2.然后一个全连接加激活函数[hidden,hidden]和sigmoid;
3.运算的时候注意是加还是乘法,如果是乘法就是直接对应元素相乘;
eg:Ct = FtCt-1 + ItC~t
最后别忘了Y
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
# 调用API
lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
2.双向循环神经网络前向和后向RNN连结的方式是前向的H和后面的H用concat连接
公式: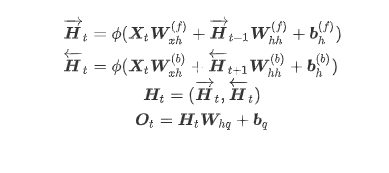
3.深度循环神经网络层数越深越好?明显错,层数多了,模型会变复杂,计算量增大。
但是好多网络不深就提取不出信息。。。
4.梯度爆炸就用梯度裁剪吧。 L2范数,即欧几里得距离,根号平方和
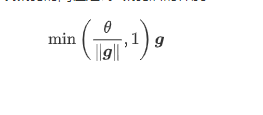
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
在pytorch调用的时候,直接对参数进行处理:
grad_clipping(params, clipping_theta, device)
5.协变量偏移,标签偏移,概念偏移简答理解
协变量偏移:特征分布的变化,就是协变量的变化,协变量移位。比如随着时间改变,这个特征会发生变化;
标签偏移:如果数据量很少,少到测试集中存在训练集中未包含的标签,就会发生标签偏移。测试出现了训练没有的label;
概念偏移:同一个物种,比如说发菜,在广东在北方的概念会不一样















 4649
4649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









