






1、爬虫导读
1.1 爬虫涉及技术
● 访问网页
● 获取响应
● 提取数据
● 数据保存
1.2 第三方依赖库
● Requests:用于发送Http请求
○ pip install requests :安装requests模块
■ import requests:导入requests模块
● BeautifulSoup:用于Html解析
○ pip install bs4:安装BeautifulSoup模块
○ pip install beautifulsoup4
■ from bs4 import BeautifulSoup:导入BeautifulSoup模块
● Pandas:用于数据结构处理
○ pip install pandas
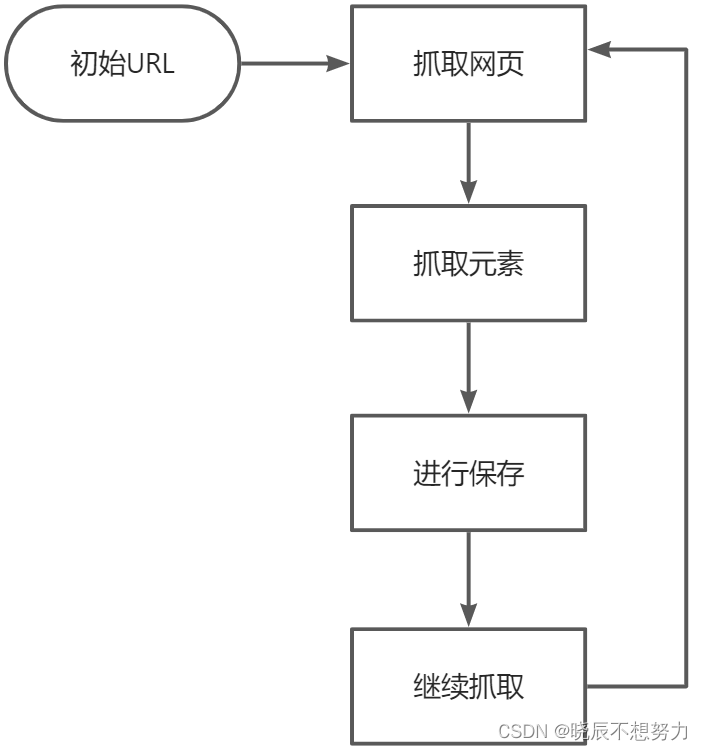
1.3 爬虫工作原理
● 初始URL
● 爬取网页
● 抓取元素
● 进行保存
● 重复爬取
2、第一个Http请求
爬取网站:http://www.51testing.com/html/91/category-catid-91.html
2.1 HTTP概览

● Request URL:表示请求的URL
● Request Method:表示请求的方法,此处用的是GET请求方法
○ Get:向指定的资源发出显示请求,一般用于获取数据
○ Post:向指定的资源提交数据,请求服务器进行处理,例如:提交表单、上传文件。数据被包含在请求文本中。
○ Delete
○ Put
● Status Code:显示HTTP请求和状态码,表示HTTP请求的状态
○ 1xx 消息——请求已被服务器接收,继续处理
○ 2xx 成功——请求已成功被服务器接收、理解、并接受
○ 3xx 重定向——需要后续操作才能完成这一请求
○ 4xx 请求错误——请求含有词法错误或者无法被执行
○ 5xx 服务器错误——服务器在处理某个正确请求时发生错误
2.2 HTTP请求头
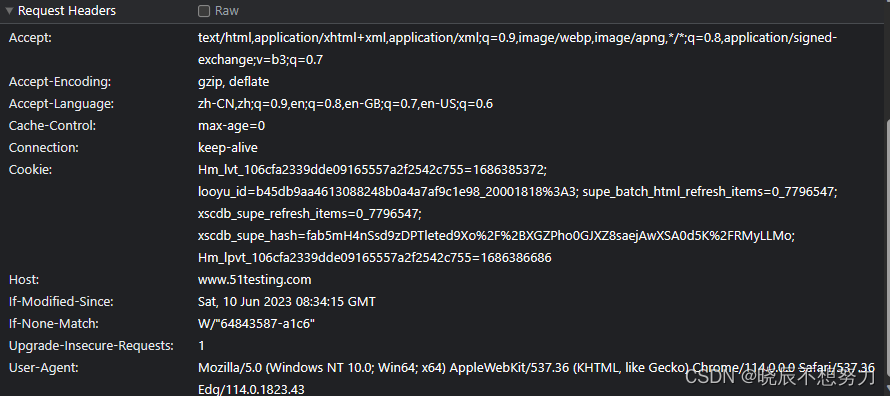
● Accept:表示请求的资源类型;
● Cookie:为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据;
● User-Agent:表示浏览器标识;
● Accept-Language:表示浏览器所支持的语言类型;
● Accept-Charset:告诉 Web 服务器,浏览器可以接受哪些字符编码;
● Accept:表示浏览器支持的 MIME 类型;
● Accept-Encoding:表示浏览器有能力解码的编码类型;
● Connection:表示客户端与服务连接类型;
2.3 用Python发送HTTP请求
import requests
from bs4 import BeautifulSoup
# 获取响应请求
response = requests.get(url="http://www.51testing.com/html/91/category-catid-91.html")
# content返回的是bytes型的原始数据
content = response.content
# 打印结果
print(content)
返回了一大串编码了的 HTML 源码,这些 HTML 源码未经解码和解析,如下图

内容拓展:
# 当前编码,默认为 ISO-8859-1
print(response.encoding)
# 当前网页的内容的实际编码
print(response.apparent_encoding)
# content返回的是bytes型的原始数据
print(response.content)
# text返回的是处理过的Unicode型的数据
print(response.text)
# statuscode返回的请求状态码
print(response.statuscode)
# json返回的是json格式的数据
print(response.json)
3、爬取网页内容
3.1 爬取第一页标题
- FireBug工具获取xpath定位方式
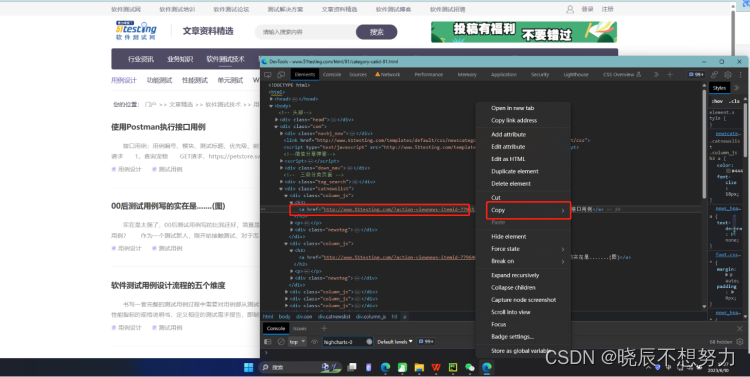
- 代码实现
import requests
from bs4 import BeautifulSoup
# 获取响应请求
response = requests.get(url="http://www.51testing.com/html/91/category-catid-91.html")
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
item = soup.select("body > div.con > div.catnewslist > div:nth-child(1) > h3 > a")
print(item)
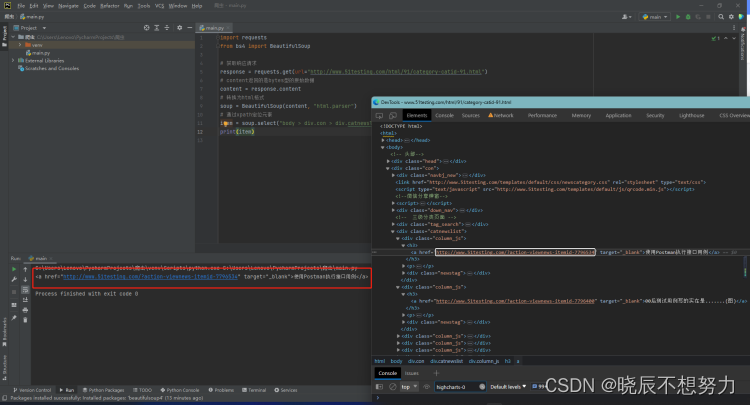
- 进行标题文本获取
import requests
from bs4 import BeautifulSoup
# 获取响应请求
response = requests.get(url="http://www.51testing.com/html/91/category-catid-91.html")
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
titles = soup.select("body > div.con > div.catnewslist > div:nth-child(1) > h3 > a")
for title in titles:
print(title.text)
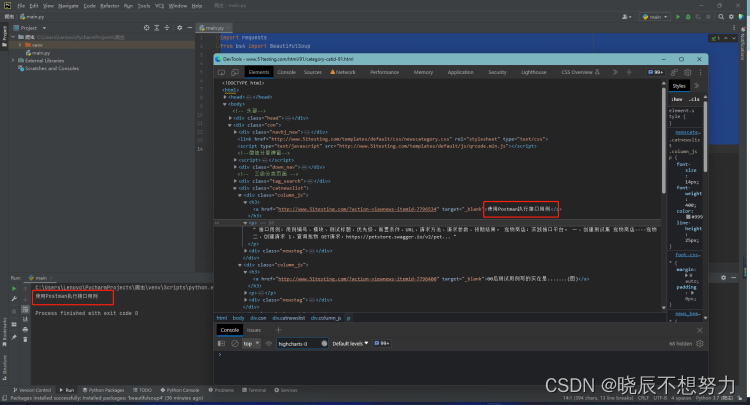
- 爬取第一页标题
1、第一条标题:body > div.con > div.catnewslist > div:nth-child(1) > h3 > a
2、第二条标题:body > div.con > div.catnewslist > div:nth-child(2) > h3 > a
3、第三条标题:body > div.con > div.catnewslist > div:nth-child(3) > h3 > a
问题:寻找其中的规律,如果通过循环来实现?
import requests
from bs4 import BeautifulSoup
# 获取响应请求
response = requests.get(url="http://www.51testing.com/html/91/category-catid-91.html")
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
# 获取标题
for i in range(1, 21):
titles = soup.select('body > div.con > div.catnewslist > div:nth-child( ' + str(i) + ') > h3 > a')
for title in titles:
print(title.get_text())
3.2 爬取第一页正文
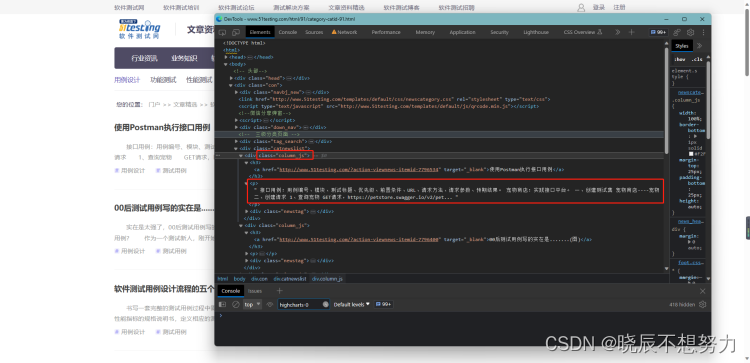
import requests
from bs4 import BeautifulSoup
# 获取响应请求
response = requests.get(url="http://www.51testing.com/html/91/category-catid-91.html")
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
main_pages = soup.select(".column_js p")
for page in main_pages:
print(page.get_text())
3.3 将标题和正文存储到列表中
import requests
from bs4 import BeautifulSoup
# 定义列表,用于存储标题
titles_list = []
# 定义列表,用于存储正文
pages_list = []
# 获取响应请求
response = requests.get(url="http://www.51testing.com/html/91/category-catid-91.html")
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
# 获取标题
for i in range(1, 21):
titles = soup.select('body > div.con > div.catnewslist > div:nth-child( ' + str(i) + ') > h3 > a')
for title in titles:
titles_list.append(title.get_text())
# 获取正文
main_pages = soup.select(".column_js p")
for page in main_pages:
pages_list.append(page.get_text())
问题:
1、打印pages_list,查看结果,存在格式字符串,如何进行字符串处理?
4、爬取多个页面
第一页:http://www.51testing.com/html/91/category-catid-91.html
第二页:http://www.51testing.com/html/91/category-catid-91-page-2.html
第三页:http://www.51testing.com/html/91/category-catid-91-page-3.html
问题:寻找其中的规律,如果通过循环来实现?
4.1 代码实现
import requests
from bs4 import BeautifulSoup
# 定义列表,用于存储标题
titles_list = []
# 定义列表,用于存储正文
pages_list = []
# 定义url
for i in range(1, 5):
if i == 1:
url = "http://www.51testing.com/html/91/category-catid-91.html"
else:
url = "http://www.51testing.com/html/91/category-catid-91-page-" + str(i) + ".html"
# 获取响应请求
response = requests.get(url=url)
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
# 获取标题
for i in range(1, 21):
titles = soup.select('body > div.con > div.catnewslist > div:nth-child( ' + str(i) + ') > h3 > a')
for title in titles:
titles_list.append(title.get_text())
# 获取正文
main_pages = soup.select(".column_js p")
for page in main_pages:
pages_list.append(page.get_text())
5、写入文件
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 定义列表,用于存储标题
titles_list = []
# 定义列表,用于存储正文
pages_list = []
# 定义url
for i in range(1, 5):
if i == 1:
url = "http://www.51testing.com/html/91/category-catid-91.html"
else:
url = "http://www.51testing.com/html/91/category-catid-91-page-" + str(i) + ".html"
# 获取响应请求
response = requests.get(url=url)
# content返回的是bytes型的原始数据
content = response.content
# 转换为html格式
soup = BeautifulSoup(content, "html.parser")
# 通过xpath定位元素
# 获取标题
for i in range(1, 21):
titles = soup.select('body > div.con > div.catnewslist > div:nth-child( ' + str(i) + ') > h3 > a')
for title in titles:
titles_list.append(title.get_text())
# 获取正文
main_pages = soup.select(".column_js p")
for page in main_pages:
pages_list.append(page.get_text())
# 创建DataFrame数据
df = pd.DataFrame({"title": titles_list, "content": pages_list})
# 创建ExcelWrite对象
writer = pd.ExcelWriter('website.xlsx')
df.to_excel(writer)
writer.save()















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









