






今天做题碰到Group by 的问题有点犯迷糊,记录下。
题目:

错误答案:
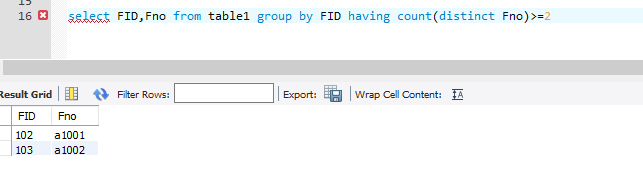
正确答案:
select * from table1 where FID in
(
select FID from table1 group by FID having count(Distinct Fno) >=2
)使用了group by 之后,就要求select后面的字段包含在group by 或聚合函数里面,
如此题如果想取到FID的不同记录,就需要在外面再嵌套一层循环

今天做题碰到Group by 的问题有点犯迷糊,记录下。
题目:
错误答案:
正确答案:
select * from table1 where FID in
(
select FID from table1 group by FID having count(Distinct Fno) >=2
)使用了group by 之后,就要求select后面的字段包含在group by 或聚合函数里面,
如此题如果想取到FID的不同记录,就需要在外面再嵌套一层循环
 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























