










跳槽对于技术人员来说,是再平常不过的一件事情,但经常就在我们刚刚起心动念还未决定之前,HR小姐姐就能未卜先知,找我们沟通聊天,普及一下企业文化,煲壶鸡汤,画个大饼,畅想一下诗和远方,然后就没有然后了。那她是如何未卜先知的呢?此外,安全团队如何识别被黑客攻击的服务器?如何识别数据泄露?这背后使用的技术就是本文要介绍的内容——UEBA
UEBA理论介绍
用户实体行为分析(UEBA)作为机器学习算法应用的一种新范式最早在网络安全领域得到广泛应用,并逐渐扩展到搜索推荐、业务风控以及内部违规管理等方面。UEBA相较传统技术的创新之处主要体现在以下几个方面:
1、行为分析导向
身份权限可能被窃取,但是行为模式难以模仿。内部威胁、外部攻击难以在基于行为的分析中完全隐藏、绕过或逃逸,行为异常成为首要的威胁信号。采集充分的数据和适当的分析,可发现横向移动、数据传输、持续回连、员工异常等异常行为。
2、聚焦用户与实体
一切的威胁都来源于人,一切的攻击最终都会必然落在帐号、 机器、数据资产和应用程序等实体上。通过持续跟踪用户和实体的 行为,持续进行风险评估,可以使安全团队最全面地了解内部威胁 风险,将日志、告警、事件、异常与用户和实体关联,构建完整的 时间线。通过聚焦用户与实体,安全团队可以摆脱告警疲惫,聚焦 到业务最关注的风险、有的放矢,提升安全运营绩效,同时通过聚 焦到以账号、资产和关键数据为中心,可以大幅降低误报告警数量
3、全时空分析
行为分析不再是孤立的针对每个独立事件,而是采用全时空分 析方法,连接起过去(历史基线)、现在(正在发生的事件)、未来 (预测的趋势),也连接起个体、群组、部门、相似职能的行为模式。 通过结合丰富的上下文,安全团队可以从多源异构数据中以多视角、 多维度对用户和实体的行为进行全方位分析,发现异常。
4、机器学习驱动
行为分析大量的采用统计分析、时序分析等基本数据分析技术, 以及非监督学习、有监督学习、深度学习等高级分析技术。通过机 器学习技术,可以从行为数据中捕捉人类无法感知、无法认知的细 微之处,找到潜藏在表象之下异常之处。同时机器学习驱动的行为 分析,避免了人工设置阈值的困难和无效。
5、异常检测
行为分析的目的,是发现异常,从正常用户中发现异常的恶意 用户,从用户的正常行为中发现异常的恶意行为。
UEBA的核心就是个人基线分析与对等组分析,通过横向个人行为比较与纵向群组比较找出异常。
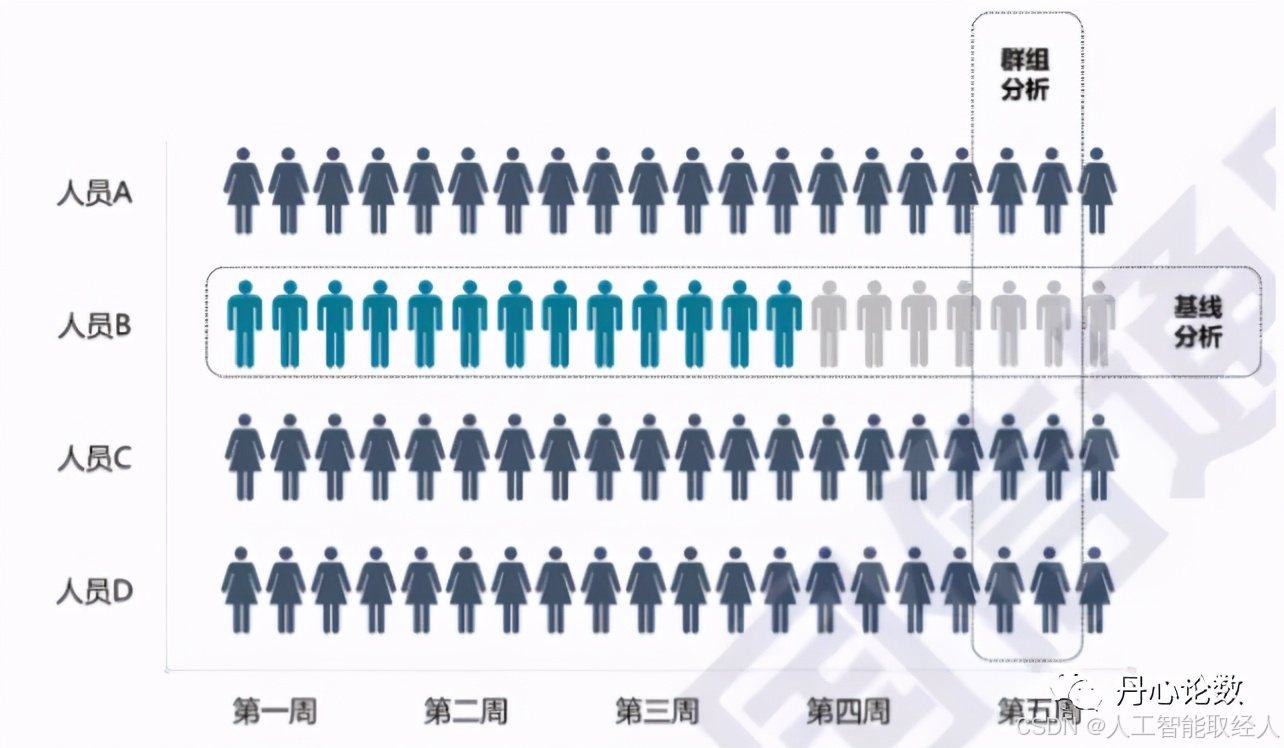
UEBA python实现
1、个人行为异常检测算法(纵向个人行为对比)
class Base_line(object):
def __init__(self,timeseries,thld=2,p_max = 7,d_max = 2,q_max = 7,train_pro=1):
self.timeseries = timeseries
self.thld = thld
self.p_max = p_max
self.d_max = d_max
self.q_max = q_max
self.p_values = range(0,self.p_max)
self.d_values = range(0,self.d_max)
self.q_values = range(0,self.q_max)
self.train_pro = train_pro
def evaluate_arima_model(self,arima_order):
#基线模型评估函数,评估指标为ARIMA预测值与真实值的标准平方根误差
#参数说明:X-时间序列数据,arima_order-arima模型的参数pdq,train_pro-训练数据的比例
# 1、训练数据准备
if self.train_pro<1:
train_size = int(len(self.timeseries) * train_pro)
train, test = self.timeseries[0:train_size], self.timeseries[train_size:]
else:
train, test = self.timeseries,self.timeseries
history = [x for x in train]
# 2、构建arima模型预测并对模型结果进行评估
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=arima_order)
model_fit = model.fit(disp=0)
yhat = model_fit.forecast()[0]
predictions.append(yhat)
history.append(test[t])
# calculate out of sample error
error = mean_squared_error(test, predictions)
return error
def bestfit_arima(self):
#最优化参数(pdq)的ARIMA模型
#参数说明:dataset-时间序列数据,p_values-p值的取值范围,列表或者数组类型,
#d_values -d值的取值范围,列表或者数组类型,q_values -q值的取值范围,列表或者数组#类型,train_pro-训练数据的比例
self.timeseries = self.timeseries.astype('float32')
best_score, best_cfg = float("inf"), None
##迭代各个参数以evaluate_arima_model函数定义的标准为依据找到最优的模型参数
for p in self.p_values:
for d in self.d_values:
for q in self.q_values:
order = (p,d,q)
try:
mse = self.evaluate_arima_model(order)
print(mse)
if mse < best_score:
best_score, best_cfg = mse, order
print('ARIMA%s MSE=%.3f' % (order,mse))
except:
continue
print('Best ARIMA%s MSE=%.3f' % (best_cfg, best_score))
return best_cfg,best_score
def base_line_predict(self):
#时间序列数据的基线预测函数
#参数说明:timeseries-时间序列数据,thld-偏离度函数,p_max-p最大值,d_max-d#最大值,q_max-q最大值,title-画图主题,train_pro-训练样本比例。
warnings.filterwarnings("ignore")
best_cfg,best_mse = self.bestfit_arima()
train_size = int(len(self.timeseries) * self.train_pro)
##定义基础模型为指数平滑移动平均,并得到基础模型的基础误差值,用以与最优化的arima模型对比
if self.train_pro<1:
test_size = len(self.timeseries)-train_size
base_mean = self.timeseries.ewm(span=7).mean()
base_mse = mean_squared_error(self.timeseries[train_size:],base_mean[train_size:])
else:
base_mean = self.timeseries.ewm(span=7).mean()
base_mse = mean_squared_error(self.timeseries,base_mean)
## 得到arima模型的最优化参数及对应的误差值
## 对比最优化arima的误差和基础模型的误差,取误差最小的为最优模型
if best_mse0:
pred_vals = arima_result.predict(dynamic=True,typ="levels")
else:
pred_vals = arima_result.predict(dynamic=True)
except:
pred_vals = base_mean
else:
pred_vals = base_mean
print("指数平滑平均化的预测误差为:%s"%base_mse)
if (pred_vals<0).any(): pred_vals='base_mean' base_line='pd.concat([self.timeseries,pred_vals],axis=1,keys=['original',' base_line keys base_line.reset_indexinplace='True)' base_line.columns='["date",'original',' base_line base_linebase_line.fillnamethod='bfill' inplace='True)' base_lineflag_base_line='np.where(base_line["original"]/(base_line["base_line"]+1)'>self.thld,1,0)
print(base_line)
return base_line ##返回dataframe 日期、原始值、基线值和是否偏离四个字段
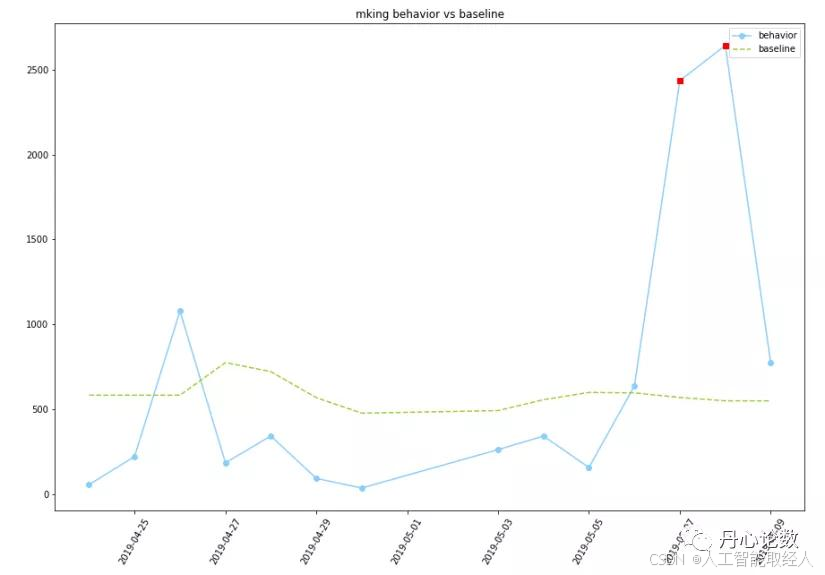
def base_line_plot(self,title="employee"):
base_line = self.base_line_predict()
fig = plt.figure('baseline',figsize=(15,10))
abm_indx=base_line[base_line["flag_base_line"]==1].index#max value index
plt.plot(base_line["date"],base_line["original"],'b-o',color = 'lightskyblue',label="behavior")
plt.plot(base_line["date"],base_line["base_line"],'m--',color = 'yellowgreen',label="baseline")
plt.plot(base_line["date"][abm_indx],base_line["original"][abm_indx],'rs')
plt.title(str(title)+' original vs baseline')
plt.legend()
plt.xticks(rotation=60)
plt.show()
输出结果:
2、对等组分析
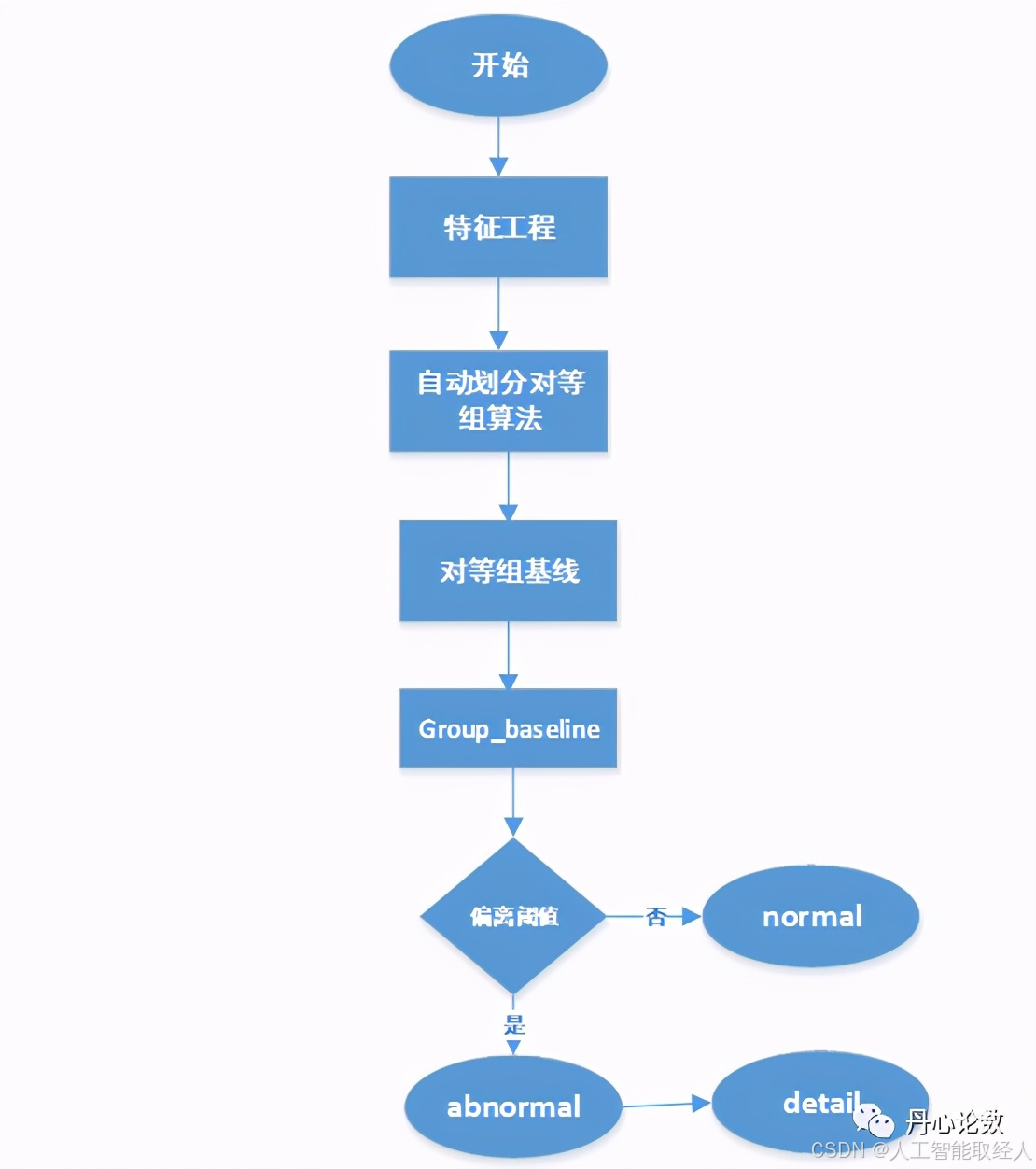
class Peer_group_analysis(object):
def __init__(self,cluster_data,src_user,all_beh,thld=2):
"""
cluster_data:用于划分对等组的数据
src_user:分析对象
all_beh:所有人的时间序列操作行为,index为src_user,列名为date和operation
"""
self.cluster_data = cluster_data
self.src_user = src_user
self.all_beh = all_beh
self.thld = thld
def group_cluster(self,start_k=2, end_k=10):
print('training cluster')
scores = []
models = []
for i in range(start_k, end_k):
kmeans_model = KMeans(n_clusters=i, n_jobs=multiprocessing.cpu_count(), )
kmeans_model.fit(self.cluster_data)
score = silhouette_score(self.cluster_data,kmeans_model.labels_,metric='euclidean')
scores.append(score) # 保存每一个k值的score值, 在这里用欧式距离
print('{} Means score loss = {}'.format(i, score))
models.append(kmeans_model)
best_cluster = models[scores.index(max(scores))]
self.cluster_data["peer_group"] = best_cluster.predict(self.cluster_data.values)
return self.cluster_data[["peer_group"]]
def group_cluster_detector(self):
peer_group = self.group_cluster(start_k=2, end_k=4)
group_index = peer_group.ix[self.src_user]["peer_group"]
group_cluster_data = pd.merge(peer_group,self.all_beh,left_index=True,right_index=True)
group_cluster_data = group_cluster_data[group_cluster_data["peer_group"]==group_index]
group_cluster_data.drop("peer_group",axis=1,inplace=True)
per_data = group_cluster_data.ix[self.src_user]
group_data = group_cluster_data[group_cluster_data.index!=self.src_user]
group_cluster_baseline = group_cluster_data.groupby("date").agg(np.mean)
pg_line = pd.merge(per_data,group_cluster_baseline,how="left",left_on="date",right_index=True,suffixes=("_original","_group_baseline"))
pg_line.reset_index(inplace=True,drop=True)
pg_line.columns = ["date",'original', 'pg_baseline']
pg_line["pg_baseline"].fillna(method="bfill",inplace=True)
pg_line["flag_pg_baseline"] = np.where(pg_line["original"]/(pg_line["pg_baseline"]+1)>self.thld,1,0)
return pg_line
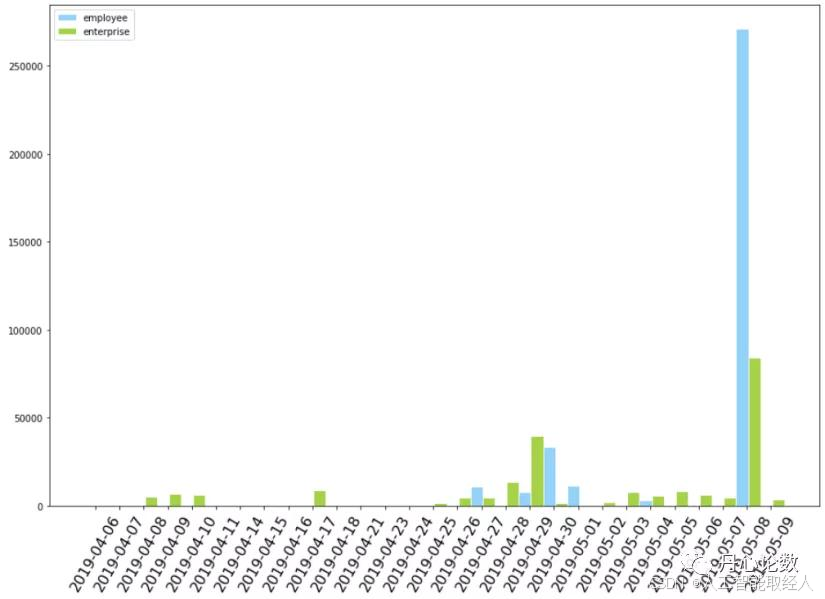
def pg_baseline_plot(self):
base_line = self.group_cluster_detector()
fig = plt.figure('baseline',figsize=(15,10))
xlocation = np.linspace(1, len(base_line), len(base_line))
plt.bar(xlocation, height=base_line["original"], alpha=0.9, width = 0.5, color = 'lightskyblue', edgecolor = 'white', label='employee')
plt.bar(xlocation+0.5, height=base_line["pg_baseline"],alpha=0.9, width = 0.5, color = 'yellowgreen', edgecolor = 'white', label='enterprise')
labels = [str(date).split()[0] for date in base_line["date"]]
plt.xticks(xlocation+0.2,labels, fontsize=16 ,rotation =60)
plt.legend()
plt.show()
输出结果:
UEBA是大数据分析、机器学习、人工智能技术在网络安全和内部管理方面应用的典型体现,本文用python实现其中基线分析与对等组分析这两大最核心的技术,当然这只是UEBA的冰山一角。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









